WholeBodyVLA: Towards Unified Latent VLA for Whole-Body Loco-Manipulation Control
作者: Haoran Jiang, Jin Chen, Qingwen Bu, Li Chen, Modi Shi, Yanjie Zhang, Delong Li, Chuanzhe Suo, Chuang Wang, Zhihui Peng, Hongyang Li
分类: cs.RO, cs.AI, cs.CV
发布日期: 2025-12-11 (更新: 2025-12-15)
💡 一句话要点
提出WholeBodyVLA以解决人形机器人大空间运动操控问题
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱六:视频提取与匹配 (Video Extraction) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 人形机器人 运动操控 视觉-语言-动作 强化学习 潜在学习 大空间操作 多模态学习
📋 核心要点
- 现有的人形机器人运动操控方法在运动意识方面存在不足,限制了其在大空间内的操作能力。
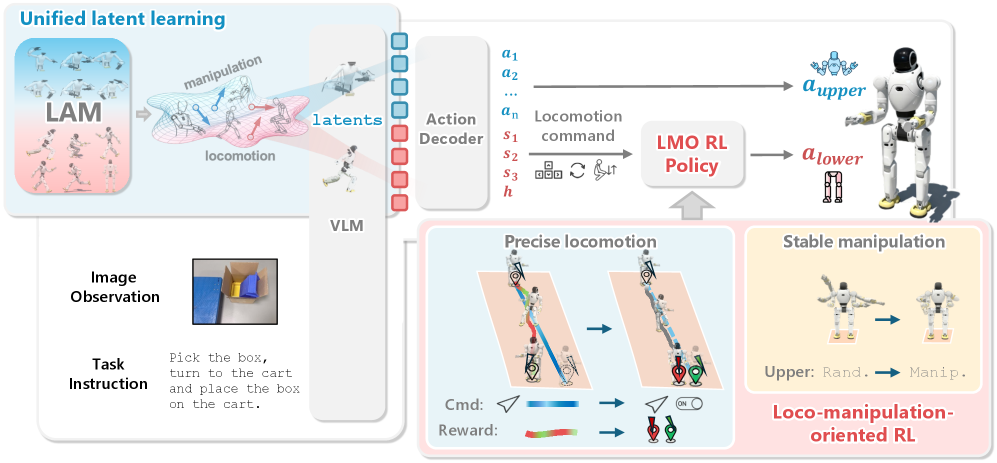
- 本文提出了WholeBodyVLA框架,通过视觉-语言-动作系统从低成本视频中学习运动操控知识,并设计了针对运动操控的强化学习策略。
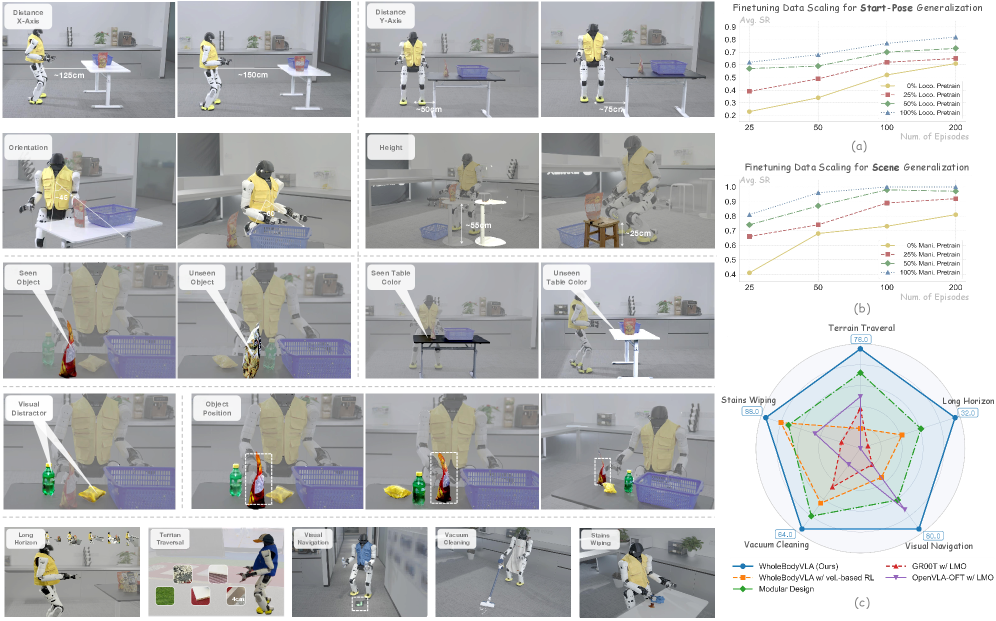
- 在AgiBot X2人形机器人上的实验结果显示,WholeBodyVLA的性能比之前的基线提高了21.3%,展现出良好的泛化能力。
📝 摘要(中文)
人形机器人在执行复杂的运动操控任务时,需要精确的运动和灵巧的操作。然而,现有的模块化或端到端方法在运动操控意识方面存在不足,限制了机器人的工作空间。为此,本文提出了一种统一的潜在学习框架WholeBodyVLA,使视觉-语言-动作系统能够从低成本的无动作自我中心视频中学习丰富的运动操控知识。此外,设计了一种高效的人类数据收集管道以扩展数据集。为提高运动指令的执行精度,提出了一种专门针对运动操控的强化学习策略。通过在AgiBot X2人形机器人上的综合实验,WholeBodyVLA的性能比之前的基线提高了21.3%,并在多种任务中表现出强大的泛化能力和高扩展性。
🔬 方法详解
问题定义:本文旨在解决人形机器人在大空间内进行运动操控的能力不足,现有方法在运动意识和数据获取方面存在挑战。
核心思路:提出统一的潜在学习框架WholeBodyVLA,使机器人能够从无动作视频中学习运动操控知识,并通过强化学习策略提高运动指令的执行精度。
技术框架:WholeBodyVLA框架包括数据收集模块、潜在学习模块和强化学习策略模块,整体流程为数据采集、知识学习和运动控制。
关键创新:WholeBodyVLA是首个能够实现大空间人形运动操控的框架,结合了视觉、语言和动作的多模态学习,显著提升了机器人的操控能力。
关键设计:设计了高效的人类数据收集管道,采用特定的损失函数和网络结构以优化运动操控的稳定性和精确性。通过强化学习策略,专注于核心运动动作的准确执行。
🖼️ 关键图片
📊 实验亮点
在AgiBot X2人形机器人上的实验结果表明,WholeBodyVLA的性能比之前的基线提高了21.3%。该框架在多种任务中展现出强大的泛化能力和高扩展性,证明了其在大空间运动操控中的有效性。
🎯 应用场景
该研究具有广泛的应用潜力,尤其在服务机器人、救援机器人和人机协作等领域。通过提高人形机器人的运动操控能力,可以实现更复杂的任务,提升机器人在实际环境中的适应性和效率,未来可能推动智能机器人技术的进一步发展。
📄 摘要(原文)
Humanoid robots require precise locomotion and dexterous manipulation to perform challenging loco-manipulation tasks. Yet existing approaches, modular or end-to-end, are deficient in manipulation-aware locomotion. This confines the robot to a limited workspace, preventing it from performing large-space loco-manipulation. We attribute this to: (1) the challenge of acquiring loco-manipulation knowledge due to the scarcity of humanoid teleoperation data, and (2) the difficulty of faithfully and reliably executing locomotion commands, stemming from the limited precision and stability of existing RL controllers. To acquire richer loco-manipulation knowledge, we propose a unified latent learning framework that enables Vision-Language-Action (VLA) system to learn from low-cost action-free egocentric videos. Moreover, an efficient human data collection pipeline is devised to augment the dataset and scale the benefits. To execute the desired locomotion commands more precisely, we present a loco-manipulation-oriented (LMO) RL policy specifically tailored for accurate and stable core loco-manipulation movements, such as advancing, turning, and squatting. Building on these components, we introduce WholeBodyVLA, a unified framework for humanoid loco-manipulation. To the best of our knowledge, WholeBodyVLA is one of its kind enabling large-space humanoid loco-manipulation. It is verified via comprehensive experiments on the AgiBot X2 humanoid, outperforming prior baseline by 21.3%. It also demonstrates strong generalization and high extensibility across a broad range of tasks.