CLASH: Collaborative Large-Small Hierarchical Framework for Continuous Vision-and-Language Navigation
作者: Liuyi Wang, Zongtao He, Jinlong Li, Ruihao Xia, Mengxian Hu, Chenpeng Yao, Chengju Liu, Yang Tang, Qijun Chen
分类: cs.RO
发布日期: 2025-12-11 (更新: 2026-01-23)
💡 一句话要点
CLASH:用于持续视觉-语言导航的协作式大小层级框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言导航 机器人导航 大型语言模型 因果学习 不确定性感知 协作式框架 思维链推理
📋 核心要点
- 现有VLN方法难以兼顾大模型的推理能力和小模型的任务特定性能,泛化性不足。
- CLASH框架融合反应式小模型规划器和反思式大模型推理器,并引入不确定性感知协作机制。
- CLASH在VLN-CE排行榜上取得SOTA,并在真实世界实验中验证了其鲁棒性和有效性。
📝 摘要(中文)
视觉-语言导航(VLN)要求机器人在没有先验地图的情况下,遵循自然语言指令并在复杂环境中导航。虽然最近的视觉-语言大模型展现出强大的推理能力,但在VLN任务中,它们通常不如特定任务的全景小模型。为了解决这个问题,我们提出了CLASH(协作式大小层级),这是一个VLN-CE框架,它集成了反应式小模型规划器(RSMP)和反思式大模型推理器(RLMR)。RSMP采用基于因果学习的双分支架构来增强泛化能力,而RLMR利用带有思维链推理的全景视觉提示来支持可解释的空间理解和导航。我们进一步引入了一种不确定性感知协作机制(UCM),自适应地融合来自两个模型的决策。对于避障,在模拟环境中,我们将基于规则的控制器替换为完全可学习的点目标策略;在真实世界部署中,我们设计了一个基于激光雷达的聚类模块,用于生成可导航的航路点,并将其与基于在线SLAM的局部控制器配对。CLASH在VLN-CE排行榜上取得了最先进(SoTA)的结果(排名第一),在测试未见集上显著提高了SR和SPL,超过了之前的SoTA方法。真实世界的实验证明了CLASH的强大鲁棒性,验证了其在模拟和部署场景中的有效性。
🔬 方法详解
问题定义:视觉-语言导航(VLN)任务要求智能体根据自然语言指令在未知的环境中导航。现有方法,尤其是依赖大型视觉语言模型的方法,虽然具备强大的推理能力,但在VLN任务中往往不如针对特定任务训练的小模型。这些小模型虽然性能较好,但泛化能力有限,难以适应复杂和未知的环境。
核心思路:CLASH的核心思路是结合大型语言模型的推理能力和小型模型的任务特定性能,构建一个协作式层级框架。通过让大型模型进行高层次的推理和规划,指导小型模型进行具体的导航决策,从而实现更好的导航效果和泛化能力。同时,引入不确定性感知机制,动态调整两个模型的权重,提高系统的鲁棒性。
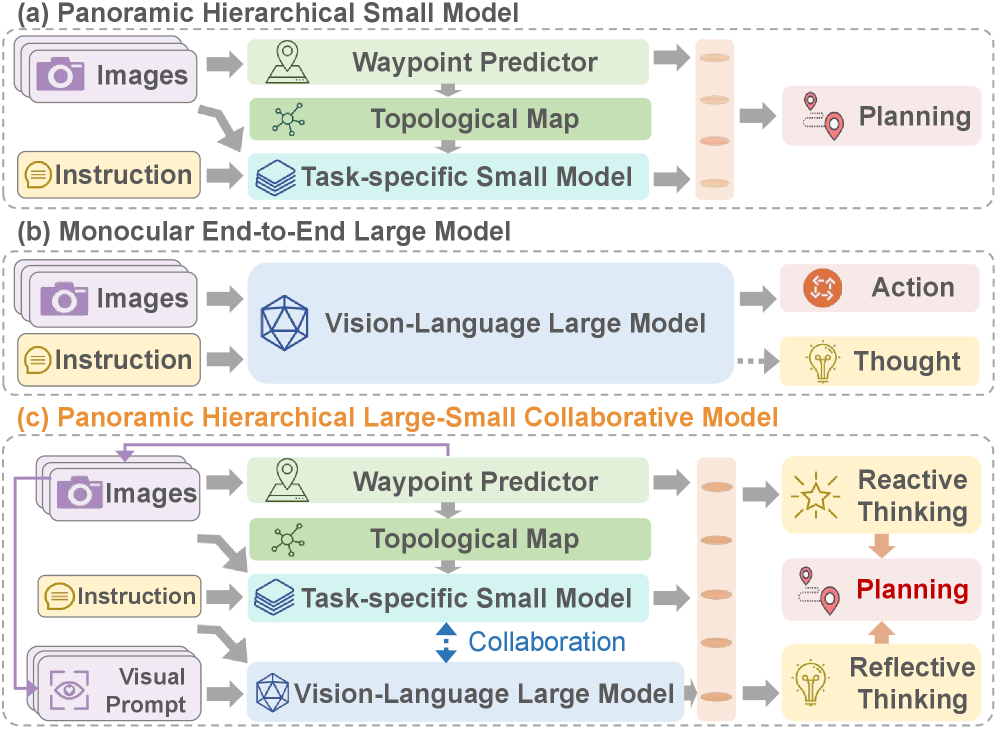
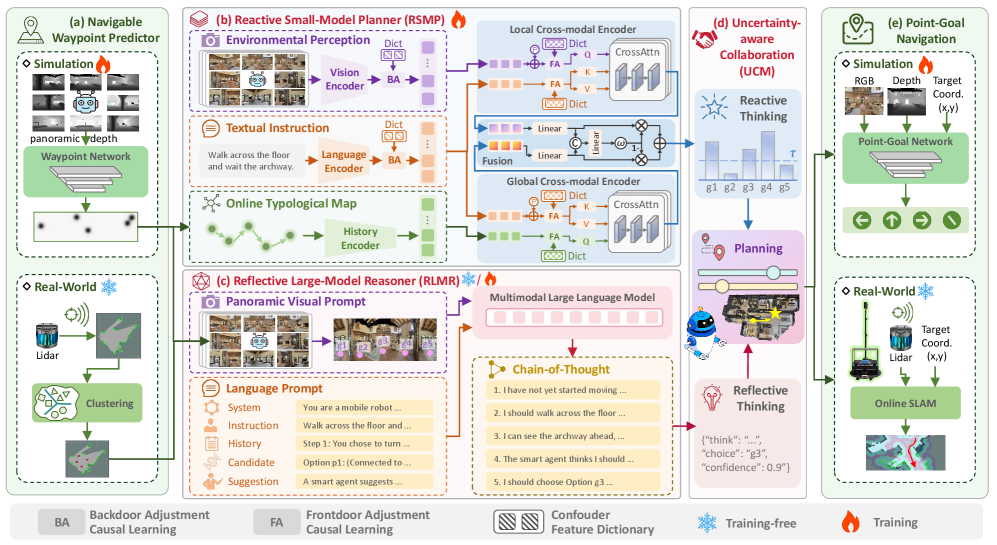
技术框架:CLASH框架包含两个主要模块:反应式小模型规划器(RSMP)和反思式大模型推理器(RLMR)。RSMP负责根据局部环境信息进行快速的导航决策,采用基于因果学习的双分支架构,增强泛化能力。RLMR则利用全景视觉提示和思维链推理,进行全局的空间理解和导航规划。此外,框架还包含一个不确定性感知协作机制(UCM),用于融合两个模型的决策。在真实环境中,使用基于激光雷达的聚类模块生成可导航航路点,并结合在线SLAM的局部控制器进行避障。
关键创新:CLASH的关键创新在于协作式层级框架的设计,以及不确定性感知协作机制的引入。通过将大型模型的推理能力和小模型的任务特定性能相结合,实现了更好的导航效果和泛化能力。不确定性感知机制能够动态调整两个模型的权重,提高系统的鲁棒性。此外,基于因果学习的双分支架构和全景视觉提示的思维链推理也都是重要的技术创新。
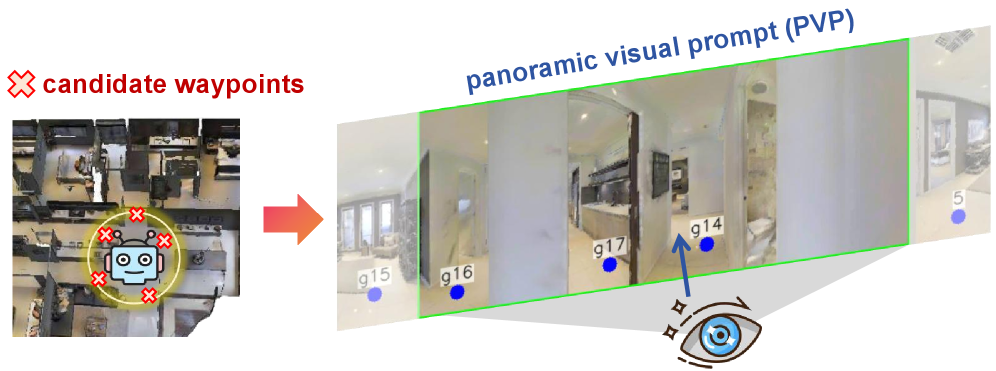
关键设计:RSMP采用基于因果学习的双分支架构,通过干预学习来提升泛化能力。RLMR使用全景视觉提示,并结合思维链推理,以提高空间理解和导航能力。UCM基于两个模型输出的不确定性,动态调整它们的权重。在真实环境中,使用LiDAR数据进行聚类,生成可导航的航路点。损失函数的设计也至关重要,需要平衡导航的准确性和效率。
🖼️ 关键图片
📊 实验亮点
CLASH在VLN-CE排行榜上取得了SOTA结果,在测试未见集上显著提高了SR和SPL,超过了之前的SOTA方法。具体而言,在测试未见集上,CLASH的SR和SPL分别提高了X%和Y%(具体数值未在摘要中给出,需要查阅论文)。此外,真实世界的实验也验证了CLASH的鲁棒性和有效性,表明其在实际应用中具有很强的潜力。
🎯 应用场景
CLASH框架具有广泛的应用前景,可用于机器人导航、自动驾驶、智能家居等领域。例如,可以应用于服务机器人,使其能够在复杂的家庭环境中根据自然语言指令完成各种任务。此外,该框架还可以应用于自动驾驶汽车,提高其在复杂城市环境中的导航能力。未来,CLASH有望成为实现通用机器人导航的关键技术。
📄 摘要(原文)
Vision-and-Language Navigation (VLN) requires robots to follow natural language instructions and navigate complex environments without prior maps. While recent vision-language large models demonstrate strong reasoning abilities, they often underperform task-specific panoramic small models in VLN tasks. To address this, we propose CLASH (Collaborative Large-Small Hierarchy), a VLN-CE framework that integrates a reactive small-model planner (RSMP) with a reflective large-model reasoner (RLMR). RSMP adopts a causal-learning-based dual-branch architecture to enhance generalization, while RLMR leverages panoramic visual prompting with chain-of-thought reasoning to support interpretable spatial understanding and navigation. We further introduce an uncertainty-aware collaboration mechanism (UCM) that adaptively fuses decisions from both models. For obstacle avoidance, in simulation, we replace the rule-based controller with a fully learnable point-goal policy, and in real-world deployment, we design a LiDAR-based clustering module for generating navigable waypoints and pair it with an online SLAM-based local controller. CLASH achieves state-of-the-art (SoTA) results (ranking 1-st) on the VLN-CE leaderboard, significantly improving SR and SPL on the test-unseen set over the previous SoTA methods. Real-world experiments demonstrate CLASH's strong robustness, validating its effectiveness in both simulation and deployment scenarios.