Safe Learning for Contact-Rich Robot Tasks: A Survey from Classical Learning-Based Methods to Safe Foundation Models
作者: Heng Zhang, Rui Dai, Gokhan Solak, Pokuang Zhou, Yu She, Arash Ajoudani
分类: cs.RO
发布日期: 2025-12-10 (更新: 2026-01-26)
备注: version 2
DOI: 10.36227/techrxiv.176472870.03980379/v1
🔗 代码/项目: GITHUB
💡 一句话要点
综述:面向接触密集型机器人任务的安全学习方法,从经典方法到安全具身智能模型
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 安全学习 接触密集型任务 机器人控制 强化学习 具身智能 视觉-语言模型 安全探索 安全执行
📋 核心要点
- 接触密集型任务中,机器人面临不确定性、复杂动力学和潜在损坏风险,现有方法难以保证探索和执行过程中的安全性。
- 该综述总结了安全探索和安全执行两大类方法,强调了约束强化学习、风险敏感优化等关键技术在平衡安全与效率中的作用。
- 重点关注视觉-语言模型(VLM)和视觉-语言-动作模型(VLA)如何与安全学习原则结合,并讨论了其带来的机遇与挑战。
📝 摘要(中文)
接触密集型任务对机器人系统提出了严峻的挑战,因为其内在的不确定性、复杂的动力学以及交互过程中发生损坏的高风险。近年来,基于学习的控制方法在使机器人获得和泛化此类环境中复杂的操纵技能方面显示出巨大的潜力,但确保安全(包括探索和执行期间的安全)仍然是可靠的实际部署的关键瓶颈。本综述全面概述了用于机器人接触密集型任务的安全学习方法。我们将现有方法分为两个主要领域:安全探索和安全执行。我们回顾了关键技术,包括约束强化学习、风险敏感优化、不确定性感知建模、控制障碍函数和模型预测安全盾,并强调了这些方法如何结合先验知识、任务结构和在线自适应来平衡安全性和效率。本综述特别强调了这些安全学习原则如何扩展到新兴的机器人具身智能模型(尤其是视觉-语言模型(VLM)和视觉-语言-动作模型(VLA))并与之交互,这些模型统一了感知、语言和控制以进行接触密集型操作。我们讨论了基于VLM/VLA的方法所带来的新的安全机会(例如,约束的语言级别规范和安全信号的多模态基础),以及它们引入的放大的风险和评估挑战。最后,我们概述了当前的局限性和有希望的未来方向,以期在复杂的接触密集型环境中部署可靠的、安全对齐的和支持具身智能模型的机器人。
🔬 方法详解
问题定义:接触密集型机器人任务由于其固有的不确定性和复杂动力学,使得机器人与环境交互时容易发生碰撞和损坏,因此安全是实际应用中的关键问题。现有的学习方法虽然在复杂操作技能习得方面取得了进展,但往往忽略了安全性,或者在安全性方面表现不足,无法保证在探索和执行过程中的安全。
核心思路:本综述的核心思路是将现有的安全学习方法进行分类和总结,并分析它们在接触密集型机器人任务中的应用。同时,探讨了新兴的具身智能模型(如VLM和VLA)如何与安全学习原则相结合,从而提高机器人在复杂环境中的安全性和可靠性。通过结合先验知识、任务结构和在线自适应,平衡安全性和效率。
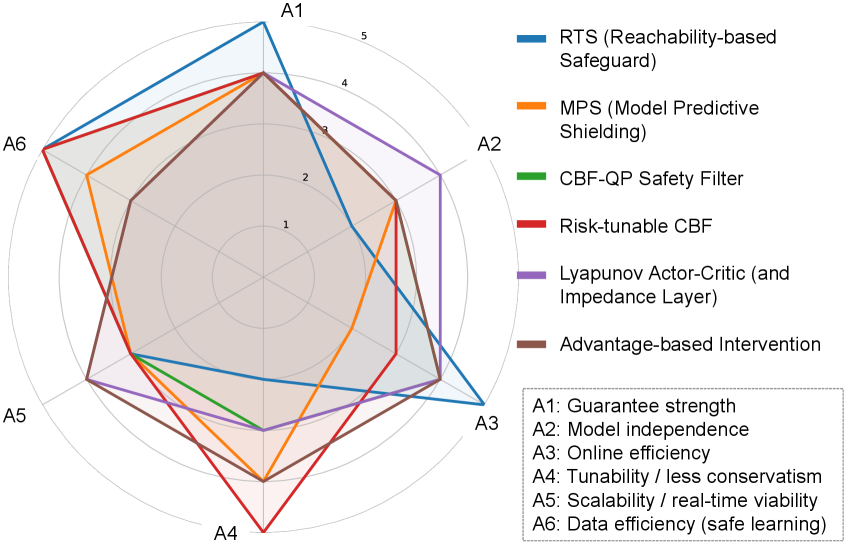
技术框架:该综述将安全学习方法分为两个主要领域:安全探索和安全执行。安全探索侧重于在学习过程中避免进入不安全状态,例如通过约束强化学习和风险敏感优化。安全执行则侧重于在执行过程中保证安全,例如通过控制障碍函数和模型预测安全盾。此外,综述还讨论了如何利用VLM/VLA模型来提高安全性和鲁棒性。
关键创新:该综述的创新之处在于,它首次全面地总结了接触密集型机器人任务中的安全学习方法,并将其与新兴的具身智能模型相结合。这为未来的研究方向提供了新的思路,例如如何利用VLM/VLA模型来提高安全性和鲁棒性,以及如何设计更有效的安全学习算法。
关键设计:综述中涉及的关键设计包括:约束强化学习中的约束设计、风险敏感优化中的风险度量、控制障碍函数中的障碍函数设计、模型预测安全盾中的预测模型设计,以及VLM/VLA模型中的视觉、语言和动作模态的融合方式。这些设计直接影响着安全学习算法的性能和鲁棒性。
🖼️ 关键图片

📊 实验亮点
该综述总结了现有安全学习方法在接触密集型任务中的应用,并分析了VLM/VLA模型带来的机遇与挑战。它为研究人员提供了一个全面的参考,并指出了未来研究方向,例如如何利用VLM/VLA模型来提高安全性和鲁棒性,以及如何设计更有效的安全学习算法。
🎯 应用场景
该研究成果可应用于各种需要与环境进行安全交互的机器人任务,例如:工业装配、医疗手术、家庭服务等。通过提高机器人的安全性和可靠性,可以降低事故风险,提高生产效率,并扩展机器人的应用范围。未来,结合具身智能模型的安全学习方法有望实现更智能、更安全的机器人系统。
📄 摘要(原文)
Contact-rich tasks pose significant challenges for robotic systems due to inherent uncertainty, complex dynamics, and the high risk of damage during interaction. Recent advances in learning-based control have shown great potential in enabling robots to acquire and generalize complex manipulation skills in such environments, but ensuring safety, both during exploration and execution, remains a critical bottleneck for reliable real-world deployment. This survey provides a comprehensive overview of safe learning-based methods for robot contact-rich tasks. We categorize existing approaches into two main domains: safe exploration and safe execution. We review key techniques, including constrained reinforcement learning, risk-sensitive optimization, uncertainty-aware modeling, control barrier functions, and model predictive safety shields, and highlight how these methods incorporate prior knowledge, task structure, and online adaptation to balance safety and efficiency. A particular emphasis of this survey is on how these safe learning principles extend to and interact with emerging robotic foundation models, especially vision-language models (VLMs) and vision-language-action models (VLAs), which unify perception, language, and control for contact-rich manipulation. We discuss both the new safety opportunities enabled by VLM/VLA-based methods, such as language-level specification of constraints and multimodal grounding of safety signals, and the amplified risks and evaluation challenges they introduce. Finally, we outline current limitations and promising future directions toward deploying reliable, safety-aligned, and foundation-model-enabled robots in complex contact-rich environments. More details and materials are available at our \href{ https://github.com/jack-sherman01/Awesome-Learning4Safe-Contact-rich-tasks}{Project GitHub Repository}.