Token Expand-Merge: Training-Free Token Compression for Vision-Language-Action Models
作者: Yifan Ye, Jiaqi Ma, Jun Cen, Zhihe Lu
分类: cs.RO
发布日期: 2025-12-10
备注: 8 pages, 5 figures
🔗 代码/项目: GITHUB
💡 一句话要点
提出TEAM-VLA,一种免训练的token压缩框架,加速VLA模型推理并保持性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言动作模型 VLA模型 Token压缩 免训练 机器人控制 模型加速 推理优化
📋 核心要点
- VLA模型参数量巨大,部署时面临计算开销大和延迟高等挑战。
- TEAM-VLA通过动态token扩展和合并,在不重新训练的情况下压缩模型。
- 在LIBERO基准测试中,TEAM-VLA提高了推理速度,并保持甚至提升了任务成功率。
📝 摘要(中文)
视觉-语言-动作(VLA)模型在大规模多模态数据集上预训练后,已成为机器人感知和控制的强大基础。然而,它们庞大的规模(通常数十亿参数)对实时部署提出了重大挑战,因为在动态环境中,推理在计算上变得昂贵且对延迟敏感。为了解决这个问题,我们提出了Token Expand-and-Merge-VLA(TEAM-VLA),这是一种免训练的token压缩框架,可在加速VLA推理的同时保持任务性能。TEAM-VLA引入了一种动态token扩展机制,用于识别和采样注意力突出显示区域附近的其他信息性token,从而增强上下文完整性。然后在动作感知指导下,在更深层中选择性地合并这些扩展的token,从而有效地减少冗余,同时保持语义连贯性。通过在单个前馈过程中耦合扩展和合并,TEAM-VLA在效率和有效性之间实现了平衡的权衡,而无需任何重新训练或参数更新。在LIBERO基准上的大量实验表明,TEAM-VLA始终提高推理速度,同时保持甚至超过完整VLA模型的任务成功率。
🔬 方法详解
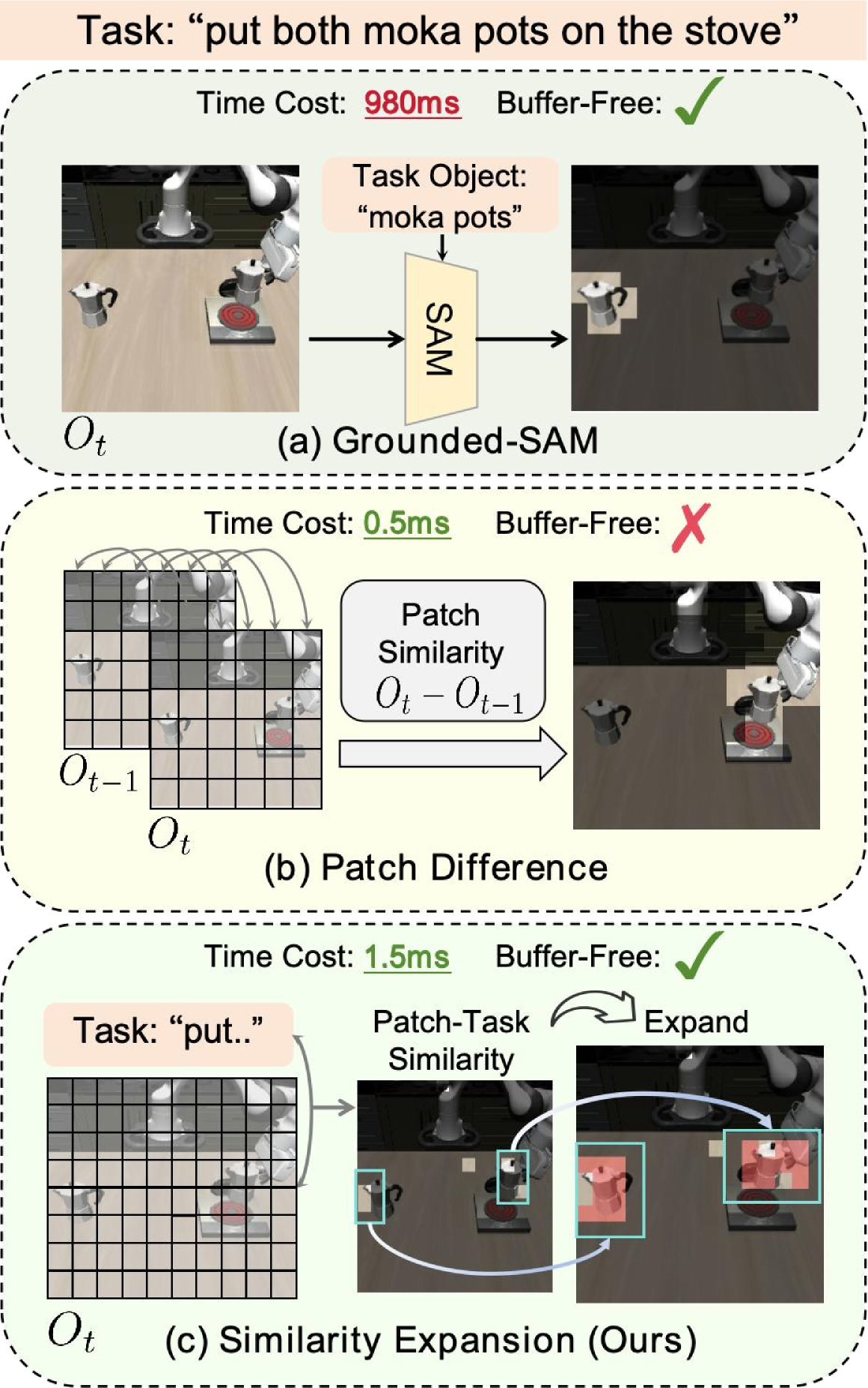
问题定义:VLA模型参数量巨大,导致推理计算成本高昂,难以满足实时性要求,尤其是在动态机器人环境中。现有方法通常需要重新训练或微调模型,增加了部署成本和复杂度。
核心思路:TEAM-VLA的核心思路是在不进行任何训练或参数更新的情况下,通过动态地扩展和合并token来压缩模型。通过扩展注意力突出区域附近的token,增强上下文信息;然后通过合并冗余token,减少计算量,从而加速推理。
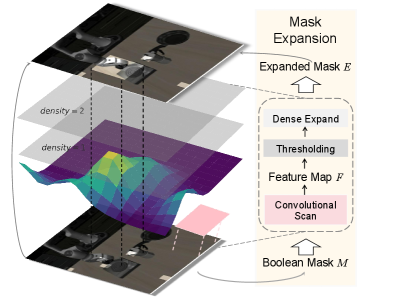
技术框架:TEAM-VLA包含两个主要阶段:Token扩展和Token合并。Token扩展阶段,首先识别注意力机制关注的区域,然后在这些区域附近采样额外的token,以补充上下文信息。Token合并阶段,在更深的网络层中,根据动作相关的指导,选择性地合并token,去除冗余信息。整个过程在一个前馈过程中完成。
关键创新:TEAM-VLA的关键创新在于其免训练的token压缩方法,以及动态token扩展和动作感知的token合并机制。与需要重新训练或微调的方法不同,TEAM-VLA可以直接应用于预训练的VLA模型,无需额外的训练成本。动作感知的token合并能够更好地保留与任务相关的关键信息。
关键设计:Token扩展阶段,采用基于注意力的采样策略,选择与高注意力区域相邻的token。Token合并阶段,使用动作相关的嵌入向量作为指导,计算token之间的相似度,并合并相似度高的token。具体的合并策略和阈值需要根据具体任务进行调整。
🖼️ 关键图片

📊 实验亮点
TEAM-VLA在LIBERO基准测试中表现出色,在提高推理速度的同时,保持甚至超过了完整VLA模型的任务成功率。实验结果表明,该方法能够有效地压缩模型,降低计算成本,并提高机器人的性能。具体的性能提升数据需要在论文中查找。
🎯 应用场景
TEAM-VLA具有广泛的应用前景,尤其是在需要实时响应的机器人应用中,例如自动驾驶、机器人操作、智能制造等。该方法可以有效降低VLA模型的计算成本和延迟,使其能够部署在资源受限的设备上,并提高机器人的决策效率和安全性。此外,该方法也可以应用于其他视觉-语言模型,以加速推理并降低部署成本。
📄 摘要(原文)
Vision-Language-Action (VLA) models pretrained on large-scale multimodal datasets have emerged as powerful foundations for robotic perception and control. However, their massive scale, often billions of parameters, poses significant challenges for real-time deployment, as inference becomes computationally expensive and latency-sensitive in dynamic environments. To address this, we propose Token Expand-and-Merge-VLA (TEAM-VLA), a training-free token compression framework that accelerates VLA inference while preserving task performance. TEAM-VLA introduces a dynamic token expansion mechanism that identifies and samples additional informative tokens in the spatial vicinity of attention-highlighted regions, enhancing contextual completeness. These expanded tokens are then selectively merged in deeper layers under action-aware guidance, effectively reducing redundancy while maintaining semantic coherence. By coupling expansion and merging within a single feed-forward pass, TEAM-VLA achieves a balanced trade-off between efficiency and effectiveness, without any retraining or parameter updates. Extensive experiments on LIBERO benchmark demonstrate that TEAM-VLA consistently improves inference speed while maintaining or even surpassing the task success rate of full VLA models. The code is public available on \href{https://github.com/Jasper-aaa/TEAM-VLA}{https://github.com/Jasper-aaa/TEAM-VLA}