YOPO-Nav: Visual Navigation using 3DGS Graphs from One-Pass Videos
作者: Ryan Meegan, Adam D'Souza, Bryan Bo Cao, Shubham Jain, Kristin Dana
分类: cs.RO, cs.CV
发布日期: 2025-12-10
💡 一句话要点
YOPO-Nav:利用单次视频的3DGS图进行视觉导航
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱六:视频提取与匹配 (Video Extraction)
关键词: 视觉导航 3D高斯溅射 机器人 位置识别 轨迹重溯
📋 核心要点
- 传统机器人导航依赖高精度地图,但构建和维护成本高昂,限制了其在动态和未知环境中的应用。
- YOPO-Nav利用单次探索视频构建紧凑的3DGS图,通过视觉对齐和分层控制实现高效的轨迹重溯导航。
- 在YOPO-Campus数据集上的实验表明,YOPO-Nav在真实机器人上实现了优秀的图像目标导航性能。
📝 摘要(中文)
视觉导航已成为传统机器人导航流程的实用替代方案,后者依赖于详细的地图构建和路径规划。然而,构建和维护3D地图通常计算成本高昂且内存密集。本文提出了一种视觉导航方法,适用于存在大型环境探索视频的情况。这些视频作为视觉参考,允许机器人重溯探索过的轨迹,而无需依赖度量地图。提出的方法YOPO-Nav(You Only Pass Once)将环境编码为由互连的局部3D高斯溅射(3DGS)模型组成的紧凑空间表示。在导航过程中,该框架将机器人当前的视觉观察与此表示对齐,并预测引导其返回演示轨迹的动作。YOPO-Nav采用分层设计:视觉位置识别(VPR)模块提供粗略定位,而局部3DGS模型细化目标和中间姿势以生成控制动作。为了评估该方法,引入了YOPO-Campus数据集,其中包含来自超过6公里的人工遥控机器人轨迹的4小时自我中心视频和机器人控制器输入。在YOPO-Campus数据集上,使用Clearpath Jackal机器人对最近的视觉导航方法进行了基准测试。实验结果表明,YOPO-Nav在真实场景中对物理机器人进行图像目标导航方面表现出色。数据集和代码将公开发布,用于视觉导航和场景表示研究。
🔬 方法详解
问题定义:现有视觉导航方法通常需要密集的3D地图,这在计算和存储上都是昂贵的。此外,当环境发生变化时,地图需要更新,增加了维护成本。因此,如何在无需精确地图的情况下,利用已有的探索视频实现高效的视觉导航是一个关键问题。
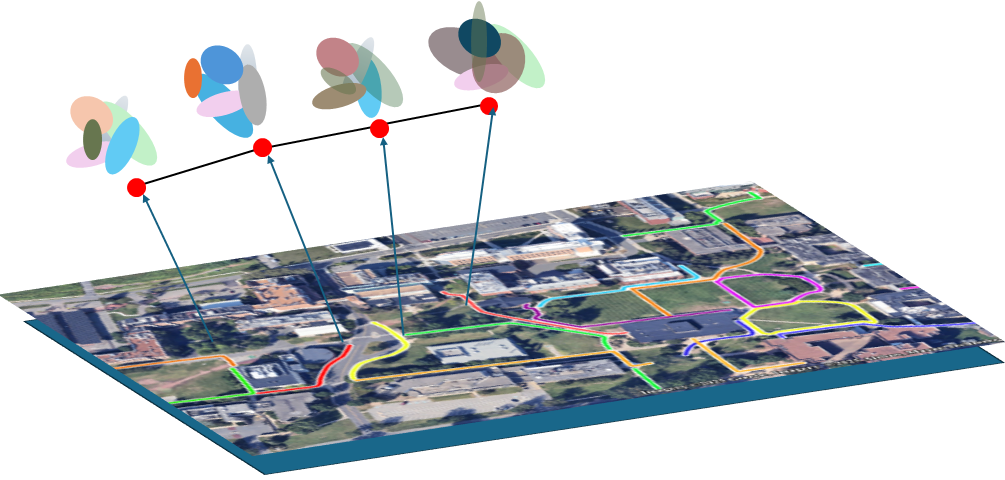
核心思路:YOPO-Nav的核心思路是利用单次探索视频构建一个轻量级的环境表示,即3DGS图。该图由一系列局部3DGS模型组成,每个模型对应于视频中的一个关键帧。在导航过程中,机器人通过视觉对齐找到当前位置对应的3DGS模型,并预测下一步动作,从而引导机器人沿着已探索的轨迹前进。
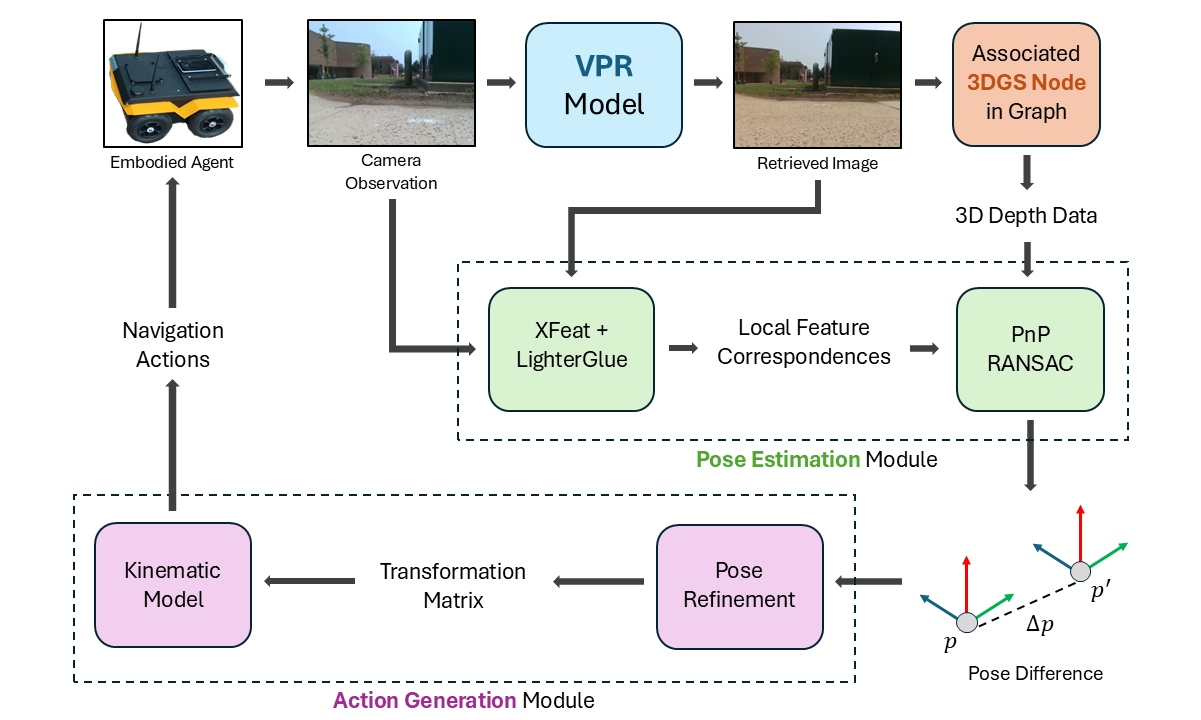
技术框架:YOPO-Nav的整体框架包含两个主要模块:视觉位置识别(VPR)模块和局部3DGS导航模块。VPR模块负责粗略定位,即找到当前帧在3DGS图中的对应节点。局部3DGS导航模块则负责精确定位和动作预测。该模块首先将当前帧与对应的3DGS模型对齐,然后计算到目标位置的相对姿态,最后根据相对姿态生成控制指令。
关键创新:YOPO-Nav的关键创新在于使用3DGS作为环境表示。3DGS是一种基于高斯球的场景表示方法,具有渲染速度快、存储空间小的优点。与传统的点云或网格模型相比,3DGS更适合于大规模场景的表示和实时渲染。此外,YOPO-Nav的分层导航策略也提高了导航的效率和鲁棒性。
关键设计:YOPO-Nav使用预训练的视觉位置识别模型进行粗略定位。局部3DGS模型通过优化高斯球的参数来拟合局部场景。导航过程中,使用基于梯度的优化方法将当前帧与3DGS模型对齐。动作预测模块使用一个小型神经网络,根据相对姿态预测控制指令。
🖼️ 关键图片
📊 实验亮点
YOPO-Nav在YOPO-Campus数据集上进行了评估,该数据集包含超过6公里的机器人轨迹。实验结果表明,YOPO-Nav在图像目标导航任务中取得了优异的性能,超过了现有的视觉导航方法。具体来说,YOPO-Nav在导航成功率和导航效率方面均有显著提升,证明了该方法在真实场景中的有效性。
🎯 应用场景
YOPO-Nav在机器人导航领域具有广泛的应用前景,例如家庭服务机器人、仓库物流机器人、以及户外巡检机器人等。该方法可以使机器人在无需预先构建地图的情况下,仅通过观看探索视频即可实现自主导航,大大降低了部署成本和维护难度。此外,该方法还可以应用于增强现实和虚拟现实等领域,为用户提供更加沉浸式的体验。
📄 摘要(原文)
Visual navigation has emerged as a practical alternative to traditional robotic navigation pipelines that rely on detailed mapping and path planning. However, constructing and maintaining 3D maps is often computationally expensive and memory-intensive. We address the problem of visual navigation when exploration videos of a large environment are available. The videos serve as a visual reference, allowing a robot to retrace the explored trajectories without relying on metric maps. Our proposed method, YOPO-Nav (You Only Pass Once), encodes an environment into a compact spatial representation composed of interconnected local 3D Gaussian Splatting (3DGS) models. During navigation, the framework aligns the robot's current visual observation with this representation and predicts actions that guide it back toward the demonstrated trajectory. YOPO-Nav employs a hierarchical design: a visual place recognition (VPR) module provides coarse localization, while the local 3DGS models refine the goal and intermediate poses to generate control actions. To evaluate our approach, we introduce the YOPO-Campus dataset, comprising 4 hours of egocentric video and robot controller inputs from over 6 km of human-teleoperated robot trajectories. We benchmark recent visual navigation methods on trajectories from YOPO-Campus using a Clearpath Jackal robot. Experimental results show YOPO-Nav provides excellent performance in image-goal navigation for real-world scenes on a physical robot. The dataset and code will be made publicly available for visual navigation and scene representation research.