Generalizable Collaborative Search-and-Capture in Cluttered Environments via Path-Guided MAPPO and Directional Frontier Allocation
作者: Jialin Ying, Zhihao Li, Zicheng Dong, Guohua Wu, Yihuan Liao
分类: cs.RO, cs.LG, cs.MA
发布日期: 2025-12-10
备注: 7 pages, 7 figures
💡 一句话要点
提出PGF-MAPPO,解决复杂环境下协作搜索捕获任务中探索效率低和泛化性差的问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 多智能体强化学习 协作搜索 路径规划 前沿探索 零样本泛化
📋 核心要点
- 复杂环境下的协作搜索捕获任务因奖励稀疏和视野受限而极具挑战,传统MARL方法探索效率低且泛化性差。
- PGF-MAPPO框架结合拓扑规划和反应式控制,利用A*势场进行奖励塑造,并引入方向性前沿分配加速覆盖。
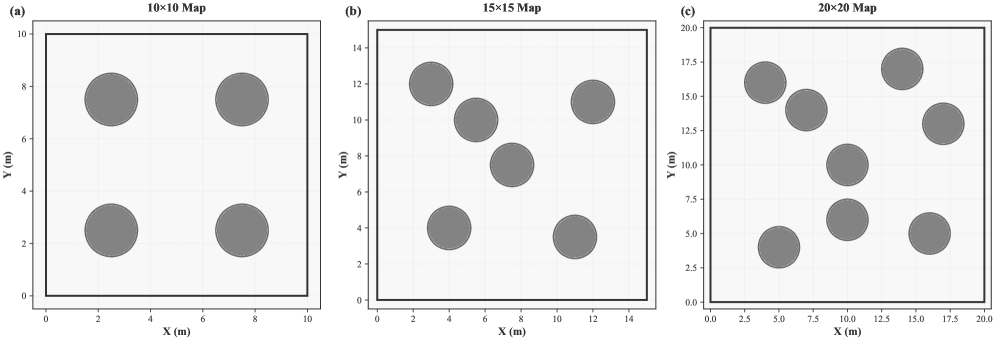
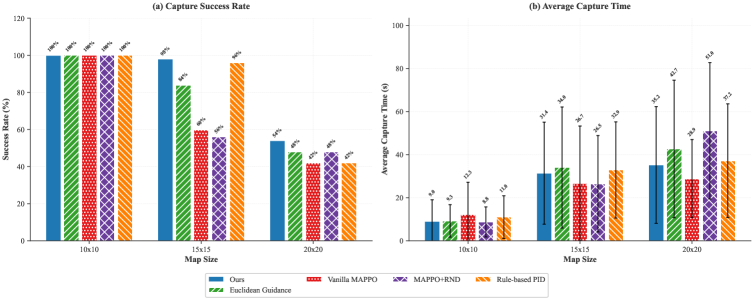
- 实验表明,PGF-MAPPO在捕获效率上优于基线方法,且在小地图上训练的策略能有效泛化到更大的未见地图。
📝 摘要(中文)
本文提出了一种名为PGF-MAPPO(Path-Guided Frontier MAPPO)的层级框架,用于解决复杂环境中协作追逐逃逸问题,该问题面临稀疏奖励和有限视野(FOV)的挑战。标准多智能体强化学习(MARL)通常存在探索效率低且难以扩展到大型场景的问题。PGF-MAPPO将基于A*的拓扑规划与反应式控制相结合,利用势场进行密集奖励塑造,以解决局部最小值和稀疏奖励问题。此外,引入了方向性前沿分配,结合最远点采样(FPS)和几何角度抑制,以增强空间分散性并加速覆盖。该架构采用参数共享的去中心化评论家,保持O(1)的模型复杂度,适用于机器人集群。实验表明,PGF-MAPPO在捕获效率方面优于速度更快的逃逸者。在10x10地图上训练的策略能够零样本泛化到未见过的20x20环境中,显著优于基于规则和基于学习的基线方法。
🔬 方法详解
问题定义:论文旨在解决复杂环境中多智能体协作搜索和捕获的问题,尤其是在奖励稀疏和视野受限的情况下。现有的多智能体强化学习方法通常面临探索效率低下,难以收敛到最优策略,并且难以泛化到更大的或未知的环境中。此外,传统的基于规则的方法虽然简单,但在复杂环境中表现不佳。
核心思路:论文的核心思路是将拓扑规划与反应式控制相结合,构建一个层级框架。通过A*算法生成潜在的路径,并利用势场进行奖励塑造,从而引导智能体进行更有效的探索。同时,通过方向性前沿分配策略,鼓励智能体探索未知的区域,避免陷入局部最优。
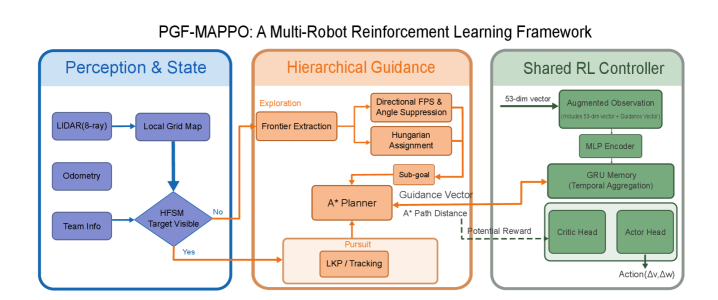
技术框架:PGF-MAPPO框架主要包含以下几个模块:1) 基于A*的路径规划器,用于生成从当前位置到目标区域的潜在路径;2) 势场奖励塑造模块,根据智能体与路径的距离生成密集的奖励信号;3) 方向性前沿分配模块,用于选择具有代表性的前沿探索点;4) 基于MAPPO的强化学习策略,用于学习智能体的控制策略。整个框架采用层级结构,高层规划器负责生成全局路径,底层控制器负责执行局部动作。
关键创新:论文的关键创新在于将拓扑规划与强化学习相结合,并提出了方向性前沿分配策略。与传统的MARL方法相比,PGF-MAPPO能够更有效地探索环境,并避免陷入局部最优。方向性前沿分配策略通过结合最远点采样和几何角度抑制,能够更好地覆盖环境,并加速学习过程。此外,参数共享的去中心化评论家设计降低了模型复杂度,使其更适用于大规模机器人集群。
关键设计:A*算法用于生成从智能体当前位置到目标区域的路径,势场奖励函数根据智能体与路径的距离进行设计,距离越近奖励越高。方向性前沿分配策略通过计算每个前沿点与其他前沿点的距离和角度,选择具有代表性的前沿点。MAPPO算法采用参数共享的去中心化评论家,每个智能体都有自己的策略网络和价值网络。损失函数包括策略梯度损失、价值函数损失和熵正则化项。
🖼️ 关键图片
📊 实验亮点
实验结果表明,PGF-MAPPO在捕获效率方面显著优于基线方法。在10x10地图上训练的策略能够零样本泛化到未见过的20x20环境中,表明该方法具有良好的泛化能力。与基于规则和基于学习的基线方法相比,PGF-MAPPO在各种复杂环境中均表现出更强的鲁棒性和适应性。
🎯 应用场景
该研究成果可应用于多种场景,如搜救行动、环境监测、自主巡逻和资源勘探等。在这些场景中,多个智能体需要协同工作,在复杂和未知的环境中进行搜索和捕获。该方法能够提高搜索效率和覆盖范围,降低人工干预的需求,具有重要的实际应用价值和潜力。
📄 摘要(原文)
Collaborative pursuit-evasion in cluttered environments presents significant challenges due to sparse rewards and constrained Fields of View (FOV). Standard Multi-Agent Reinforcement Learning (MARL) often suffers from inefficient exploration and fails to scale to large scenarios. We propose PGF-MAPPO (Path-Guided Frontier MAPPO), a hierarchical framework bridging topological planning with reactive control. To resolve local minima and sparse rewards, we integrate an A*-based potential field for dense reward shaping. Furthermore, we introduce Directional Frontier Allocation, combining Farthest Point Sampling (FPS) with geometric angle suppression to enforce spatial dispersion and accelerate coverage. The architecture employs a parameter-shared decentralized critic, maintaining O(1) model complexity suitable for robotic swarms. Experiments demonstrate that PGF-MAPPO achieves superior capture efficiency against faster evaders. Policies trained on 10x10 maps exhibit robust zero-shot generalization to unseen 20x20 environments, significantly outperforming rule-based and learning-based baselines.