COVLM-RL: Critical Object-Oriented Reasoning for Autonomous Driving Using VLM-Guided Reinforcement Learning
作者: Lin Li, Yuxin Cai, Jianwu Fang, Jianru Xue, Chen Lv
分类: cs.RO
发布日期: 2025-12-10
备注: 8 pages, 5 figures
💡 一句话要点
提出COVLM-RL框架,利用VLM引导强化学习解决自动驾驶泛化性问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自动驾驶 强化学习 视觉语言模型 关键对象推理 思维链 泛化能力 可解释性
📋 核心要点
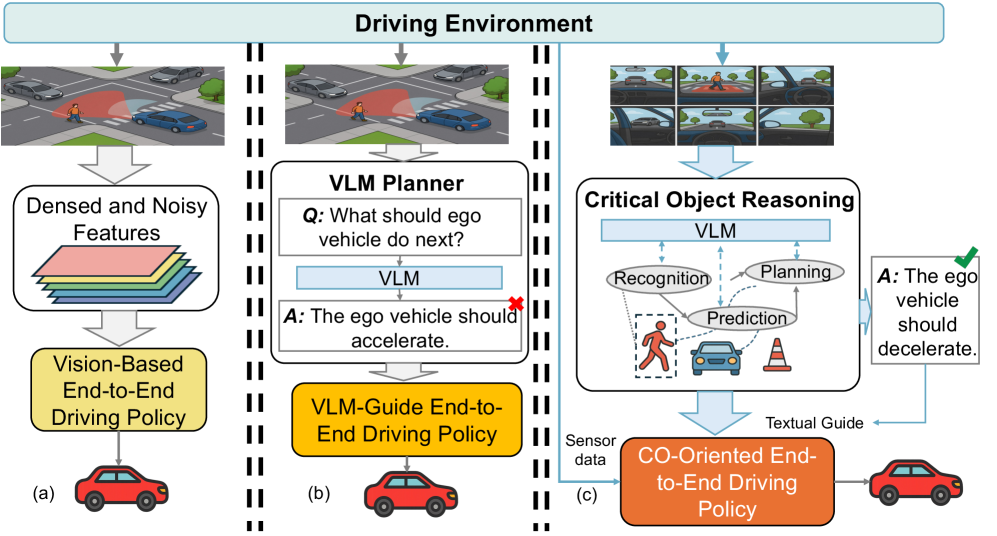
- 现有端到端自动驾驶方法在泛化性、训练效率和可解释性方面存在不足,尤其是在新场景下的鲁棒性较差。
- COVLM-RL框架结合关键对象推理和VLM引导的强化学习,利用VLM生成语义决策先验,注入任务相关知识。
- 实验结果表明,COVLM-RL在CARLA模拟器中显著提高了成功率,尤其是在未见过的环境中,泛化能力突出。
📝 摘要(中文)
端到端自动驾驶框架在泛化性、训练效率和可解释性方面面临持续挑战。现有方法通过大规模数据集上的监督学习利用视觉-语言模型(VLM)来改进推理,但在新场景中缺乏鲁棒性。而基于强化学习(RL)的方法虽然增强了适应性,但数据效率低且缺乏透明的决策过程。为了解决这些限制,我们提出了COVLM-RL,一种新颖的端到端驾驶框架,它将关键对象导向(CO)推理与VLM引导的RL相结合。具体来说,我们设计了一种思维链(CoT)提示策略,使VLM能够推理关键交通元素并生成高级语义决策,有效地将多视图视觉输入转换为结构化的语义决策先验。这些先验降低了输入维度,并将任务相关知识注入到RL循环中,从而加速训练并提高策略的可解释性。为了弥合高级语义指导与连续低级控制之间的差距,我们引入了一致性损失,以鼓励VLM的语义计划与RL代理的控制输出之间的一致性,从而增强可解释性和训练稳定性。在CARLA模拟器中进行的实验表明,COVLM-RL在已训练的驾驶环境中将成功率提高了30%,在以前未见过的环境中提高了50%,突显了其强大的泛化能力。
🔬 方法详解
问题定义:端到端自动驾驶系统难以泛化到新的、未知的驾驶场景。现有的基于视觉-语言模型(VLM)的方法虽然可以通过监督学习提高推理能力,但在新场景下的鲁棒性不足。而基于强化学习(RL)的方法虽然具有适应性,但数据效率低,训练成本高,且决策过程缺乏透明性,难以解释。
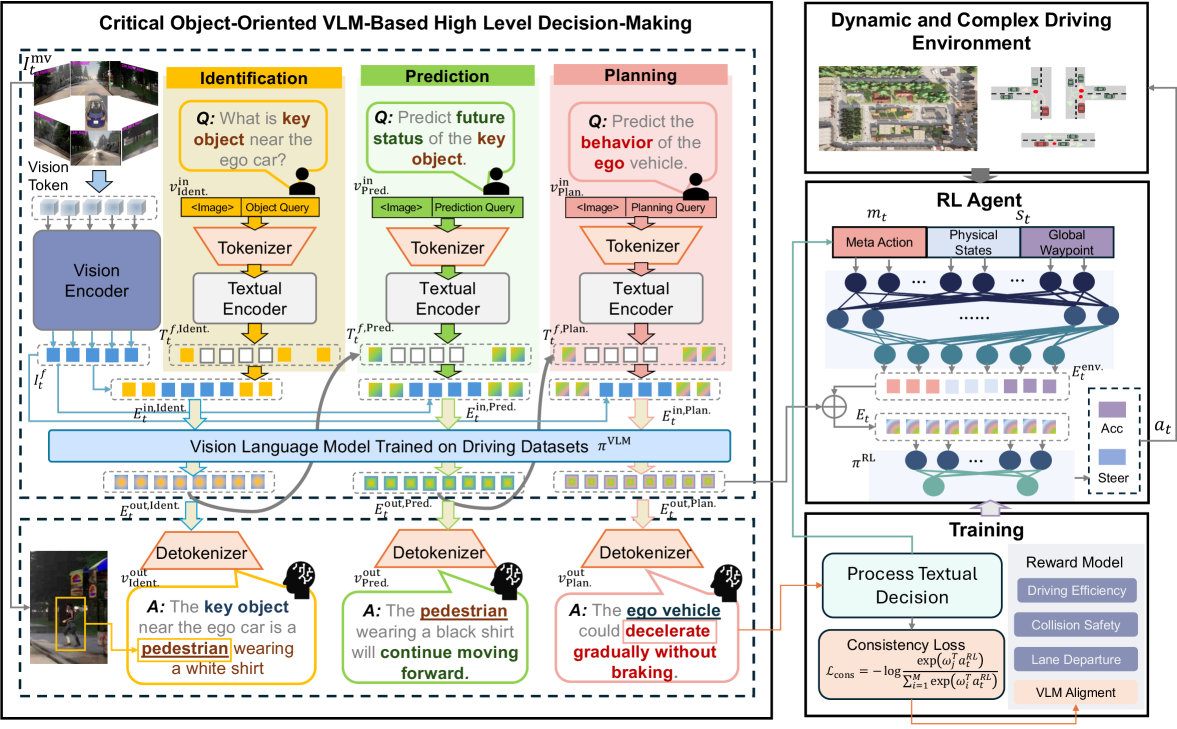
核心思路:COVLM-RL的核心思路是将VLM的语义推理能力与RL的自适应控制能力相结合。通过VLM对关键交通元素进行推理,生成高层次的语义决策先验,从而指导RL agent的学习过程,提高训练效率和泛化能力。同时,通过一致性损失,保证VLM的语义计划与RL agent的控制输出之间的一致性,提高决策的可解释性。
技术框架:COVLM-RL框架主要包含以下几个模块:1) 多视图视觉输入模块:接收来自多个摄像头的视觉信息。2) VLM推理模块:利用Chain-of-Thought (CoT) 提示策略,使VLM能够推理关键交通元素并生成高级语义决策。3) RL agent模块:基于接收到的语义决策先验和环境信息,学习控制策略。4) 一致性损失模块:计算VLM的语义计划与RL agent的控制输出之间的一致性损失,用于优化训练过程。
关键创新:COVLM-RL的关键创新在于:1) 提出了将VLM的语义推理能力与RL的自适应控制能力相结合的框架。2) 设计了Chain-of-Thought (CoT) 提示策略,使VLM能够有效地推理关键交通元素。3) 引入了一致性损失,保证VLM的语义计划与RL agent的控制输出之间的一致性,提高决策的可解释性。
关键设计:VLM推理模块使用了Chain-of-Thought (CoT) 提示策略,引导VLM逐步推理关键交通元素,例如车辆、行人、交通信号灯等。一致性损失函数的设计旨在衡量VLM生成的语义计划与RL agent的控制输出之间的差异,例如,VLM预测应该减速,而RL agent输出了加速指令,则会产生较大的损失。RL agent的网络结构采用常见的Actor-Critic结构,Actor网络负责输出控制指令,Critic网络负责评估当前状态的价值。
🖼️ 关键图片

📊 实验亮点
实验结果表明,COVLM-RL在CARLA模拟器中取得了显著的性能提升。在已训练的驾驶环境中,COVLM-RL的成功率提高了30%。更重要的是,在以前未见过的环境中,COVLM-RL的成功率提高了50%,这充分证明了其强大的泛化能力。这些结果表明,COVLM-RL能够有效地利用VLM的语义推理能力来指导RL agent的学习,从而提高自动驾驶系统的性能。
🎯 应用场景
COVLM-RL框架具有广泛的应用前景,可应用于各种自动驾驶场景,例如城市道路、高速公路和停车场等。该框架能够提高自动驾驶系统的泛化能力、训练效率和可解释性,使其在复杂和动态的交通环境中更加安全可靠。此外,该研究思路也可以推广到其他机器人控制任务中,例如无人机导航和机器人操作等。
📄 摘要(原文)
End-to-end autonomous driving frameworks face persistent challenges in generalization, training efficiency, and interpretability. While recent methods leverage Vision-Language Models (VLMs) through supervised learning on large-scale datasets to improve reasoning, they often lack robustness in novel scenarios. Conversely, reinforcement learning (RL)-based approaches enhance adaptability but remain data-inefficient and lack transparent decision-making. % contribution To address these limitations, we propose COVLM-RL, a novel end-to-end driving framework that integrates Critical Object-oriented (CO) reasoning with VLM-guided RL. Specifically, we design a Chain-of-Thought (CoT) prompting strategy that enables the VLM to reason over critical traffic elements and generate high-level semantic decisions, effectively transforming multi-view visual inputs into structured semantic decision priors. These priors reduce the input dimensionality and inject task-relevant knowledge into the RL loop, accelerating training and improving policy interpretability. However, bridging high-level semantic guidance with continuous low-level control remains non-trivial. To this end, we introduce a consistency loss that encourages alignment between the VLM's semantic plans and the RL agent's control outputs, enhancing interpretability and training stability. Experiments conducted in the CARLA simulator demonstrate that COVLM-RL significantly improves the success rate by 30\% in trained driving environments and by 50\% in previously unseen environments, highlighting its strong generalization capability.