Scene-agnostic Hierarchical Bimanual Task Planning via Visual Affordance Reasoning
作者: Kwang Bin Lee, Jiho Kang, Sung-Hee Lee
分类: cs.RO
发布日期: 2025-12-10
备注: 8 pages, 4 figures
💡 一句话要点
提出基于视觉可供性的场景无关分层双臂任务规划框架
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 双臂机器人 任务规划 视觉可供性 场景无关 具身智能
📋 核心要点
- 现有机器人任务规划器主要为单臂操作,难以应对双臂操作中固有的空间、几何和协调挑战。
- 提出一个统一的框架,通过视觉点接地、双臂子目标规划器和交互点驱动的双臂提示三个模块,实现场景无关的双臂任务规划。
- 实验表明,该方法能够生成连贯、可行且紧凑的双手规划,并推广到杂乱场景,无需重新训练。
📝 摘要(中文)
具身智能体在开放环境中操作时,需要将高层指令转化为可执行的行为,这通常需要双手协调使用。虽然最近的基础模型提供了强大的语义推理能力,但现有的机器人任务规划器主要还是单臂操作,无法解决场景无关设置中双臂操作固有的空间、几何和协调挑战。本文提出了一个统一的场景无关双臂任务规划框架,将高层推理与3D接地的双手执行联系起来。该方法集成了三个关键模块:视觉点接地(VPG)、双臂子目标规划器(BSP)和交互点驱动的双臂提示(IPBP)。实验表明,该方法能够生成连贯、可行且紧凑的双手规划,并推广到杂乱的场景,无需重新训练,展示了双臂任务中鲁棒的场景无关可供性推理。
🔬 方法详解
问题定义:论文旨在解决在复杂、未知的场景中,如何让机器人有效地进行双臂协同操作的任务规划问题。现有方法主要集中在单臂操作,或者需要大量的场景特定训练数据,难以泛化到新的环境。痛点在于缺乏一种能够理解场景语义、推理双臂交互关系,并生成可行操作序列的通用框架。
核心思路:论文的核心思路是将高层语义推理与3D空间中的双臂操作相结合。通过视觉感知理解场景,提取关键交互点,然后利用这些信息规划出协调的双手子目标,最后将这些子目标转化为具体的动作序列。这种分层规划的方式能够有效地降低问题的复杂度,并提高泛化能力。
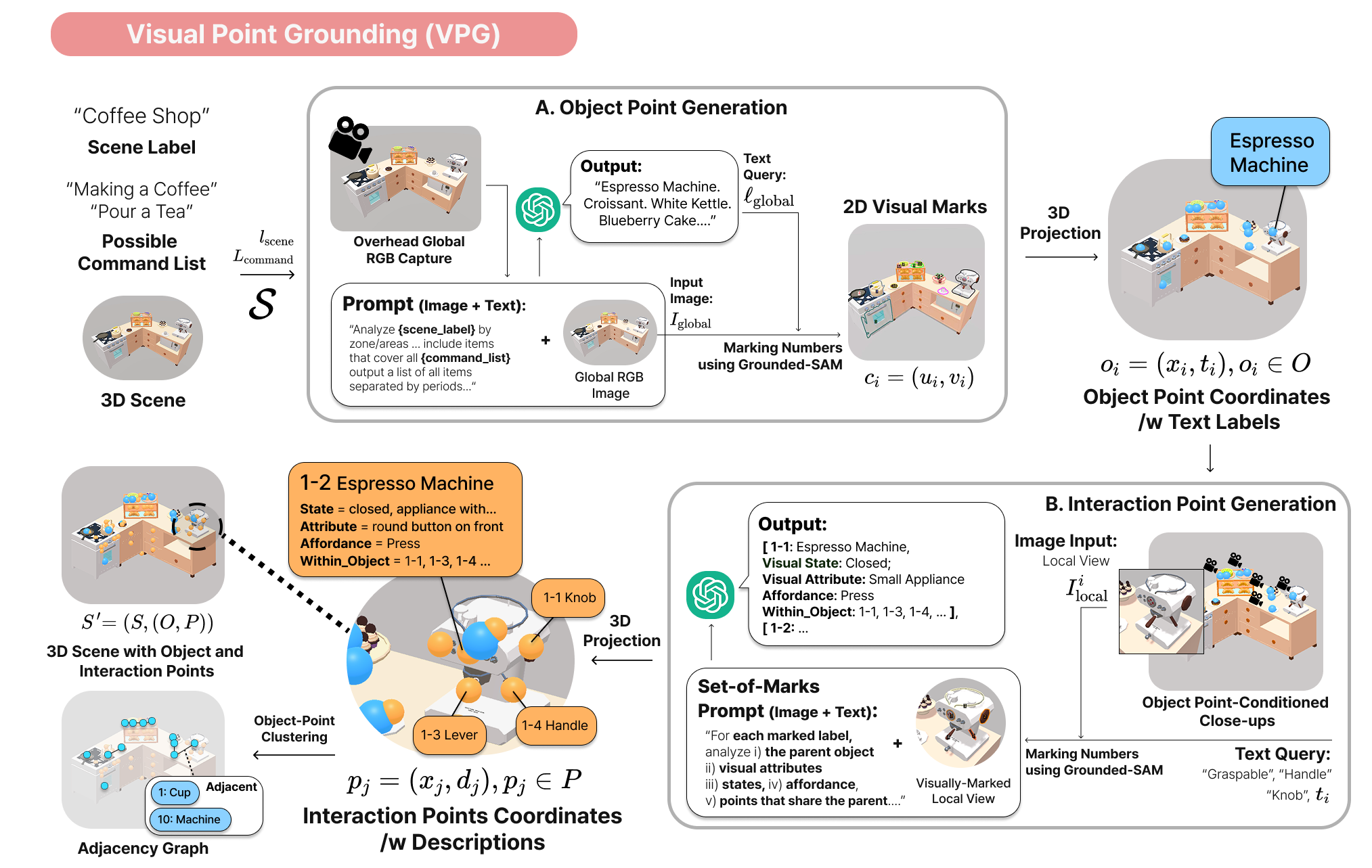
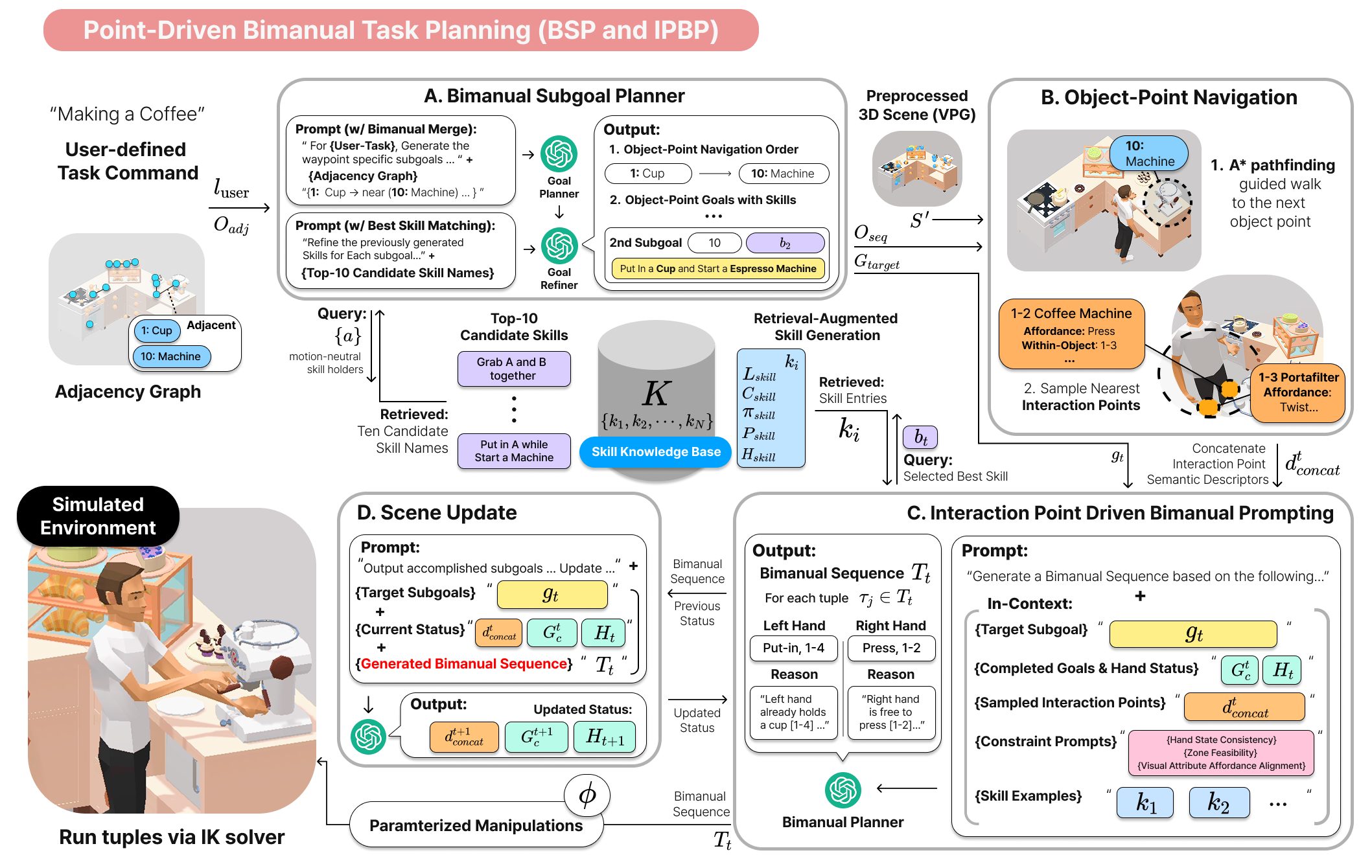
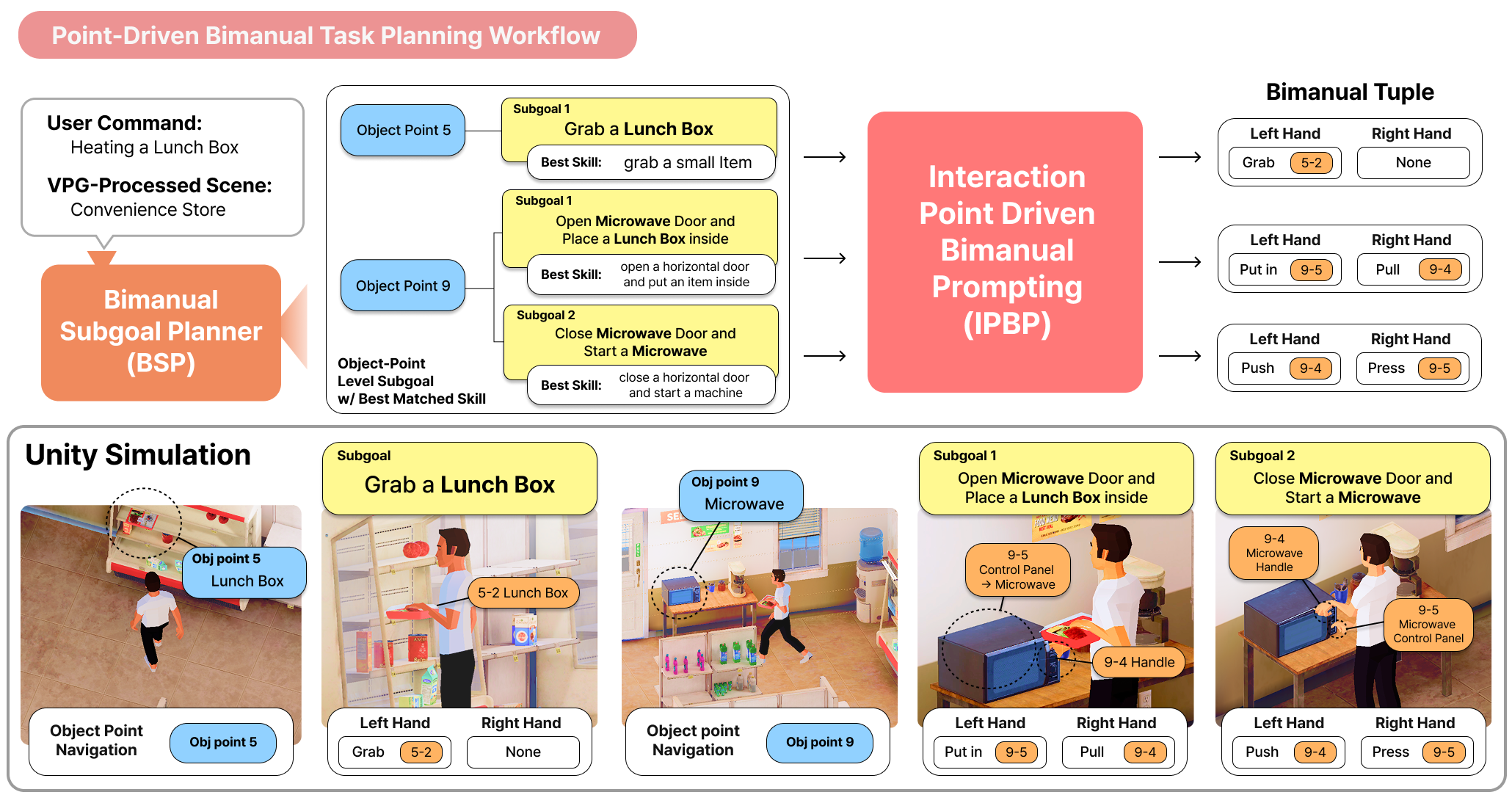
技术框架:整体框架包含三个主要模块:1) 视觉点接地(VPG):分析场景图像,检测相关对象,并生成世界坐标系下的交互点。2) 双臂子目标规划器(BSP):基于空间邻接性和跨对象可达性,生成紧凑、运动中性的子目标,利用双手协调操作的机会。3) 交互点驱动的双臂提示(IPBP):将子目标与结构化的技能库绑定,实例化同步的单臂或双臂动作序列,满足手部状态和可供性约束。
关键创新:最重要的创新在于将视觉可供性推理与双臂任务规划相结合,提出了一个场景无关的通用框架。与现有方法相比,该方法不需要针对特定场景进行训练,能够直接应用于新的环境。此外,双臂子目标规划器能够有效地利用双手协调操作的优势,生成更高效的任务规划。
关键设计:VPG模块使用深度学习模型进行物体检测和关键点预测。BSP模块采用启发式搜索算法,根据空间关系和可达性约束生成子目标。IPBP模块使用提示学习的方式,将子目标与技能库中的动作序列进行匹配。具体的损失函数和网络结构等细节在论文中进行了详细描述(未知)。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法能够生成连贯、可行且紧凑的双手规划,并且能够推广到杂乱的场景,无需重新训练。这表明该方法具有很强的场景泛化能力。具体的性能数据和对比基线在论文中进行了详细描述(未知)。
🎯 应用场景
该研究成果可应用于各种需要双臂协同操作的机器人应用场景,例如:家庭服务机器人、工业自动化、医疗辅助机器人等。通过该框架,机器人可以更好地理解人类指令,并在复杂环境中完成各种任务,提高工作效率和安全性。未来,该技术有望进一步扩展到更多类型的机器人和更复杂的任务。
📄 摘要(原文)
Embodied agents operating in open environments must translate high-level instructions into grounded, executable behaviors, often requiring coordinated use of both hands. While recent foundation models offer strong semantic reasoning, existing robotic task planners remain predominantly unimanual and fail to address the spatial, geometric, and coordination challenges inherent to bimanual manipulation in scene-agnostic settings. We present a unified framework for scene-agnostic bimanual task planning that bridges high-level reasoning with 3D-grounded two-handed execution. Our approach integrates three key modules. Visual Point Grounding (VPG) analyzes a single scene image to detect relevant objects and generate world-aligned interaction points. Bimanual Subgoal Planner (BSP) reasons over spatial adjacency and cross-object accessibility to produce compact, motion-neutralized subgoals that exploit opportunities for coordinated two-handed actions. Interaction-Point-Driven Bimanual Prompting (IPBP) binds these subgoals to a structured skill library, instantiating synchronized unimanual or bimanual action sequences that satisfy hand-state and affordance constraints. Together, these modules enable agents to plan semantically meaningful, physically feasible, and parallelizable two-handed behaviors in cluttered, previously unseen scenes. Experiments show that it produces coherent, feasible, and compact two-handed plans, and generalizes to cluttered scenes without retraining, demonstrating robust scene-agnostic affordance reasoning for bimanual tasks.