VLSA: Vision-Language-Action Models with Plug-and-Play Safety Constraint Layer
作者: Songqiao Hu, Zeyi Liu, Shuang Liu, Jun Cen, Zihan Meng, Xiao He
分类: cs.RO, eess.SY
发布日期: 2025-12-09
备注: 20 pages, 14 figures
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出AEGIS架构,通过可插拔安全约束层提升VLA模型在机器人操作中的安全性。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言动作模型 机器人安全 控制屏障函数 可插拔架构 安全约束 机器人操作 碰撞避免
📋 核心要点
- VLA模型在复杂环境中部署面临安全挑战,尤其是在避免碰撞方面。
- AEGIS架构通过可插拔的安全约束层,在保证任务完成的同时,提升安全性。
- SafeLIBERO基准测试表明,AEGIS在避障率和任务成功率上均有显著提升。
📝 摘要(中文)
视觉-语言-动作(VLA)模型在各种机器人操作任务中表现出卓越的泛化能力。然而,由于需要同时满足任务要求和安全保证,特别是在防止物理交互过程中潜在碰撞方面,将这些模型部署在非结构化环境中仍然具有挑战性。本文提出了一种名为AEGIS的视觉-语言-安全动作(VLSA)架构,它包含一个通过控制屏障函数构建的可插拔安全约束(SC)层。AEGIS直接与现有的VLA模型集成,以提高安全性并提供理论保证,同时保持其原始的指令遵循性能。为了评估该架构的有效性,我们构建了一个全面的安全关键基准SafeLIBERO,涵盖了不同程度空间复杂性和障碍物干预的独特操作场景。大量实验表明,我们的方法优于最先进的基线。值得注意的是,AEGIS在避障率方面提高了59.16%,同时显著提高了任务执行成功率17.25%。为了方便重现和未来的研究,我们将代码、模型和基准数据集公开在https://vlsa-aegis.github.io/。
🔬 方法详解
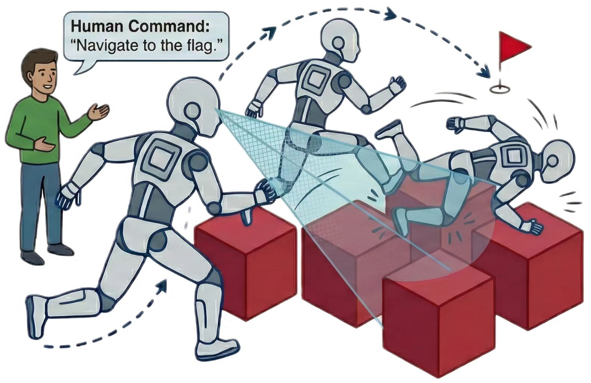
问题定义:现有的视觉-语言-动作(VLA)模型在机器人操作任务中表现出色,但缺乏足够的安全保障,尤其是在非结构化环境中,容易发生碰撞等安全问题。这些模型难以在保证任务完成的同时,避免与环境中的障碍物发生碰撞,限制了其在实际场景中的应用。
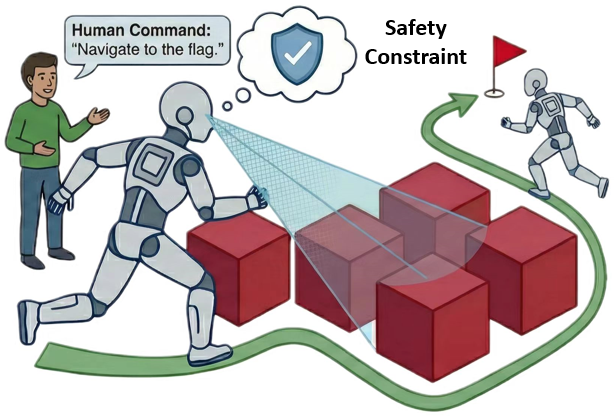
核心思路:论文的核心思路是引入一个可插拔的安全约束(SC)层,该层基于控制屏障函数(Control Barrier Functions, CBF)构建,能够对VLA模型产生的动作进行安全约束,确保机器人在执行任务的过程中不会发生碰撞。这种设计允许在不修改原有VLA模型结构的前提下,提升其安全性。
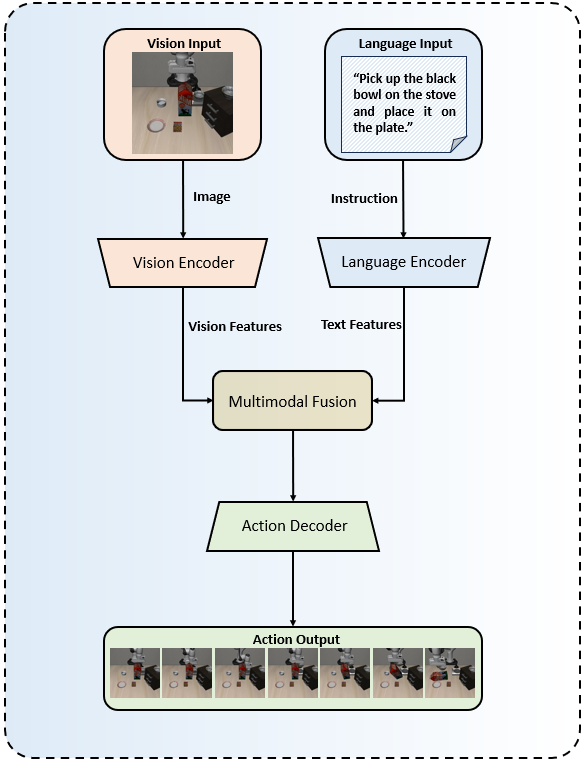
技术框架:AEGIS架构包含两个主要部分:现有的VLA模型和一个可插拔的安全约束(SC)层。VLA模型负责根据视觉和语言输入生成动作指令,SC层则接收VLA模型的输出,并根据环境信息(如障碍物位置)进行安全评估。如果VLA模型的输出可能导致碰撞,SC层会对其进行修正,生成一个安全的动作指令。整个过程可以看作是一个串联的结构,VLA模型提供原始动作,SC层进行安全校正。
关键创新:该论文的关键创新在于提出了一个可插拔的安全约束层,该层能够与现有的VLA模型无缝集成,无需重新训练或修改VLA模型的结构。这种设计使得AEGIS架构具有很强的通用性和灵活性,可以应用于各种不同的VLA模型。此外,基于控制屏障函数构建安全约束层,为安全性提供了理论保证。
关键设计:安全约束层基于控制屏障函数(CBF)构建,CBF是一种用于保证系统安全性的数学工具。SC层通过优化一个二次规划问题(Quadratic Programming, QP)来修正VLA模型的输出,目标是在满足CBF约束的前提下,尽可能地接近VLA模型的原始输出。QP问题的目标函数通常是VLA模型输出与修正后动作之间的距离,约束条件则是CBF函数的值大于等于零,确保安全性。具体参数设置包括CBF函数的参数(如安全距离、衰减系数等)以及QP求解器的参数。
🖼️ 关键图片
📊 实验亮点
实验结果表明,AEGIS架构在SafeLIBERO基准测试中表现出色,避障率提高了59.16%,任务执行成功率提高了17.25%。与现有的最先进基线方法相比,AEGIS在安全性和任务完成度方面均取得了显著的提升,验证了该方法的有效性。
🎯 应用场景
该研究成果可广泛应用于各种需要安全保障的机器人操作任务中,例如:家庭服务机器人、工业机器人、医疗机器人等。通过AEGIS架构,可以提升机器人在复杂环境中的安全性和可靠性,降低事故发生的风险,从而加速机器人在实际场景中的应用。
📄 摘要(原文)
Vision-Language-Action (VLA) models have demonstrated remarkable capabilities in generalizing across diverse robotic manipulation tasks. However, deploying these models in unstructured environments remains challenging due to the critical need for simultaneous task compliance and safety assurance, particularly in preventing potential collisions during physical interactions. In this work, we introduce a Vision-Language-Safe Action (VLSA) architecture, named AEGIS, which contains a plug-and-play safety constraint (SC) layer formulated via control barrier functions. AEGIS integrates directly with existing VLA models to improve safety with theoretical guarantees, while maintaining their original instruction-following performance. To evaluate the efficacy of our architecture, we construct a comprehensive safety-critical benchmark SafeLIBERO, spanning distinct manipulation scenarios characterized by varying degrees of spatial complexity and obstacle intervention. Extensive experiments demonstrate the superiority of our method over state-of-the-art baselines. Notably, AEGIS achieves a 59.16% improvement in obstacle avoidance rate while substantially increasing the task execution success rate by 17.25%. To facilitate reproducibility and future research, we make our code, models, and the benchmark datasets publicly available at https://vlsa-aegis.github.io/.