ShelfAware: Real-Time Visual-Inertial Semantic Localization in Quasi-Static Environments with Low-Cost Sensors
作者: Shivendra Agrawal, Jake Brawer, Ashutosh Naik, Alessandro Roncone, Bradley Hayes
分类: cs.RO, cs.AI
发布日期: 2025-12-09
备注: 8 pages
💡 一句话要点
ShelfAware:利用低成本传感器在准静态环境中进行实时视觉惯性语义定位
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 视觉惯性定位 语义SLAM 粒子滤波 准静态环境 机器人导航
📋 核心要点
- 现有视觉定位方法在准静态环境中面临挑战,如重复几何结构和动态杂波导致定位精度下降。
- ShelfAware提出了一种基于语义粒子滤波的全局定位方法,将场景语义视为对象类别的统计证据。
- 实验表明,ShelfAware在零售环境中实现了96%的定位成功率,优于MCL和AMCL,并保持了稳定的跟踪。
📝 摘要(中文)
许多室内工作空间是准静态的:全局布局稳定,但局部语义不断变化,产生重复的几何结构、动态杂波和感知噪声,这使得基于视觉的定位失效。我们提出了ShelfAware,一种用于鲁棒全局定位的语义粒子滤波器,它将场景语义视为对象类别上的统计证据,而不是固定的地标。ShelfAware融合了深度似然与以类别为中心的语义相似性,并使用预先计算的语义视点库在MCL内部执行逆语义提议,从而在低成本、纯视觉硬件上实现快速、有针对性的假设生成。在语义密集的零售环境中,跨越四种条件(车载、可穿戴、动态障碍物和稀疏语义)的100次全局定位试验中,ShelfAware实现了96%的成功率(而MCL为22%,AMCL为10%),平均收敛时间为1.91秒,在所有条件下都获得了最低的平移RMSE,并在80%的测试序列中保持了稳定的跟踪,所有这些都在消费级笔记本电脑平台上实时运行。通过在类别级别对语义进行分布建模并利用逆提议,ShelfAware解决了准静态域中常见的几何混叠和语义漂移问题。由于该方法只需要视觉传感器和VIO,因此它可以作为仓库、实验室和零售环境中移动机器人的无基础设施构建块进行集成;作为一个代表性的应用,它还支持为视力障碍人士创建辅助设备,提供随时启动的共享控制辅助导航。
🔬 方法详解
问题定义:论文旨在解决准静态环境中,由于重复几何结构、动态杂波和感知噪声导致的视觉定位鲁棒性问题。现有方法,如MCL和AMCL,在这些环境中容易出现几何混叠和语义漂移,导致定位失败。
核心思路:ShelfAware的核心思路是将场景语义信息融入到粒子滤波定位框架中,将场景语义视为对象类别的概率分布,而不是固定的地标。通过融合深度信息和语义相似性,并利用逆语义提议,实现更准确和鲁棒的全局定位。
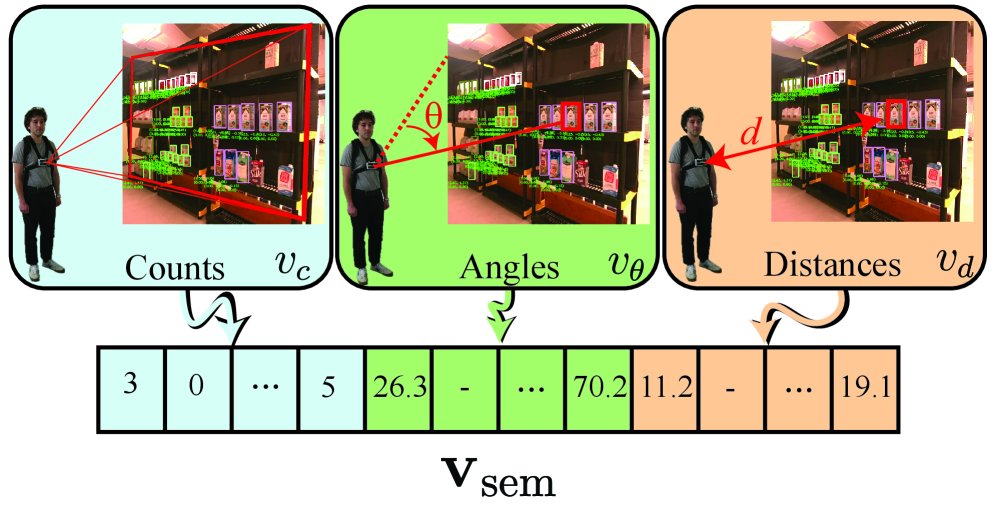
技术框架:ShelfAware的整体框架是一个基于粒子滤波的定位系统,主要包含以下模块:1) 视觉惯性里程计(VIO):用于估计相机的位姿。2) 深度似然计算:利用深度图像计算每个粒子与观测到的深度信息的匹配程度。3) 语义相似性计算:利用图像语义分割结果,计算每个粒子与观测到的语义信息的匹配程度。4) 逆语义提议:利用预先计算的语义视点库,生成新的粒子,加速收敛。5) 粒子滤波更新:根据深度似然和语义相似性,更新粒子的权重。
关键创新:ShelfAware的关键创新在于:1) 将场景语义建模为对象类别的概率分布,而不是固定的地标,从而提高了对动态环境的鲁棒性。2) 提出了逆语义提议方法,利用预先计算的语义视点库,快速生成高质量的粒子,加速了定位收敛。3) 将深度信息和语义信息融合到粒子滤波框架中,提高了定位的准确性和鲁棒性。
关键设计:ShelfAware的关键设计包括:1) 使用Mask R-CNN进行语义分割,提取图像中的对象类别信息。2) 使用预先构建的语义视点库,包含不同视角的场景语义信息。3) 设计了深度似然和语义相似性度量函数,用于评估粒子与观测信息的匹配程度。4) 采用自适应粒子重采样策略,避免粒子退化。
🖼️ 关键图片


📊 实验亮点
ShelfAware在零售环境中进行了大量实验,结果表明:1) 在100次全局定位试验中,ShelfAware实现了96%的成功率,而MCL为22%,AMCL为10%。2) ShelfAware的平均收敛时间为1.91秒。3) ShelfAware在所有测试条件下都获得了最低的平移RMSE。4) ShelfAware在80%的测试序列中保持了稳定的跟踪。这些结果表明,ShelfAware在准静态环境中具有显著的优势。
🎯 应用场景
ShelfAware具有广泛的应用前景,包括:1) 仓库和零售环境中的移动机器人导航。2) 实验室环境中的机器人定位。3) 为视力障碍人士提供辅助导航。该研究的实际价值在于提供了一种低成本、高鲁棒性的定位解决方案,可以促进移动机器人在复杂室内环境中的应用。
📄 摘要(原文)
Many indoor workspaces are quasi-static: global layout is stable but local semantics change continually, producing repetitive geometry, dynamic clutter, and perceptual noise that defeat vision-based localization. We present ShelfAware, a semantic particle filter for robust global localization that treats scene semantics as statistical evidence over object categories rather than fixed landmarks. ShelfAware fuses a depth likelihood with a category-centric semantic similarity and uses a precomputed bank of semantic viewpoints to perform inverse semantic proposals inside MCL, yielding fast, targeted hypothesis generation on low-cost, vision-only hardware. Across 100 global-localization trials spanning four conditions (cart-mounted, wearable, dynamic obstacles, and sparse semantics) in a semantically dense, retail environment, ShelfAware achieves a 96% success rate (vs. 22% MCL and 10% AMCL) with a mean time-to-convergence of 1.91s, attains the lowest translational RMSE in all conditions, and maintains stable tracking in 80% of tested sequences, all while running in real time on a consumer laptop-class platform. By modeling semantics distributionally at the category level and leveraging inverse proposals, ShelfAware resolves geometric aliasing and semantic drift common to quasi-static domains. Because the method requires only vision sensors and VIO, it integrates as an infrastructure-free building block for mobile robots in warehouses, labs, and retail settings; as a representative application, it also supports the creation of assistive devices providing start-anytime, shared-control assistive navigation for people with visual impairments.