Robust Finetuning of Vision-Language-Action Robot Policies via Parameter Merging
作者: Yajat Yadav, Zhiyuan Zhou, Andrew Wagenmaker, Karl Pertsch, Sergey Levine
分类: cs.RO, cs.AI
发布日期: 2025-12-09 (更新: 2025-12-18)
💡 一句话要点
提出基于参数融合的视觉-语言-动作机器人策略微调方法,提升泛化能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人策略 微调 参数融合 泛化能力 终身学习
📋 核心要点
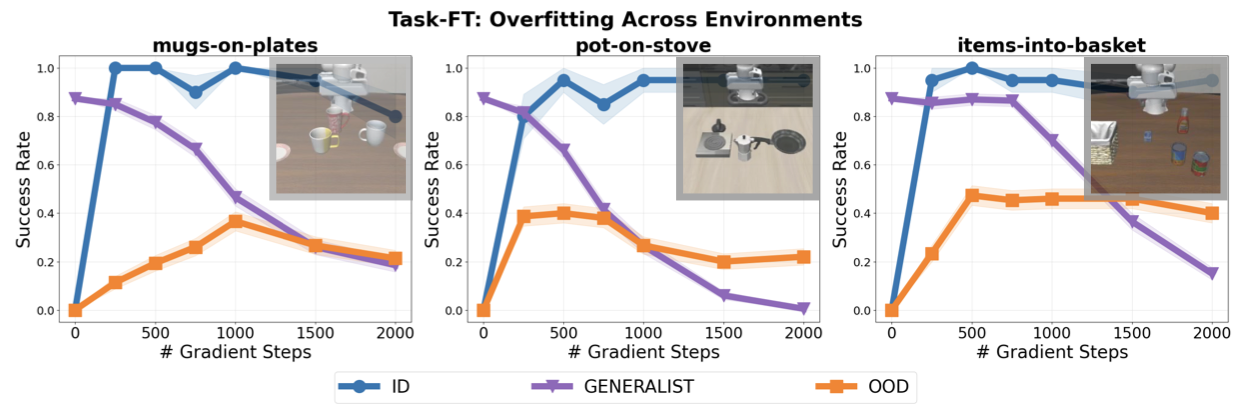
- 通用机器人策略微调时易过拟合,丧失原有泛化能力,无法适应新任务的变体。
- 提出一种基于参数融合的微调策略,通过插值微调模型和预训练模型的权重,保留泛化能力。
- 实验表明,该方法在模拟和真实环境中均优于单独的预训练和微调模型,并支持终身学习。
📝 摘要(中文)
通用机器人策略通过在大型多样数据集上训练,展现了跨多种行为的泛化能力,使得单个策略能够在不同的真实世界环境中行动。然而,它们在新任务上仍然表现不足。当在有限的新任务演示数据上进行微调时,这些策略通常会过度拟合特定演示,不仅失去解决各种通用任务的能力,也无法在新任务本身中泛化。本文旨在开发一种方法,在微调期间保留通用策略的泛化能力,从而使单个策略能够稳健地将新技能纳入其能力范围。我们的目标是使单个策略既能泛化到新任务的变体,又能保留从预训练中获得的广泛能力。我们表明,这可以通过一种简单而有效的策略来实现:将微调模型的权重与预训练模型的权重进行插值。通过广泛的模拟和真实世界实验,我们表明这种模型融合产生了一个单一的模型,该模型继承了基础模型的通用能力,并学会稳健地解决新任务,优于预训练和微调模型在新任务的分布外变体上的表现。此外,我们表明模型融合性能随预训练数据量的增加而扩展,并能够在终身学习环境中持续获取新技能,而不会牺牲先前学习的通用能力。
🔬 方法详解
问题定义:现有通用机器人策略在面对新任务时,即使经过微调,也容易出现过拟合现象。具体表现为:在新任务的特定演示数据上表现良好,但在该任务的变体上泛化能力不足,并且会遗忘预训练阶段学习到的通用技能。因此,核心问题是如何在微调过程中保持策略的泛化能力和通用性。
核心思路:论文的核心思路是通过模型融合(Model Merging)来解决上述问题。具体而言,将微调后的模型权重与预训练模型的权重进行插值,从而在学习新任务的同时,保留预训练模型所具备的通用知识和泛化能力。这种方法避免了完全依赖微调模型,而是将微调视为对预训练模型的微小调整。
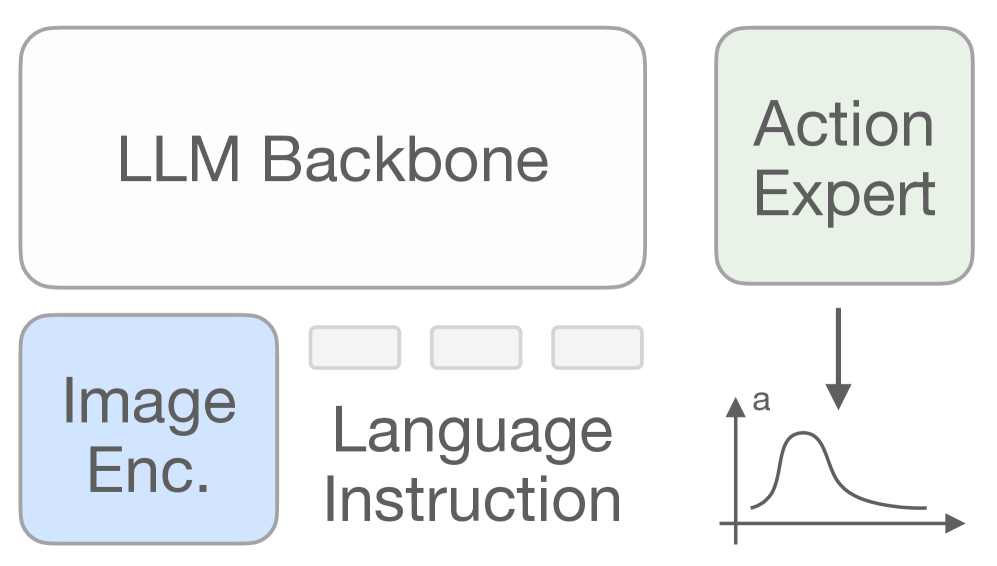
技术框架:该方法的技术框架非常简洁。首先,使用大规模数据集预训练一个通用的机器人策略模型。然后,在少量新任务的演示数据上对该模型进行微调,得到一个针对新任务的微调模型。最后,将预训练模型的权重和微调模型的权重进行线性插值,得到最终的模型。插值系数是一个超参数,用于控制预训练模型和微调模型对最终模型的影响程度。
关键创新:该方法最重要的创新点在于其简单性和有效性。通过简单的参数融合,即可显著提升微调后模型的泛化能力,使其既能适应新任务,又能保留原有的通用技能。这种方法避免了复杂的正则化技术或架构设计,易于实现和应用。
关键设计:关键设计在于权重插值的比例。论文中,插值系数(即预训练模型权重的比例)是一个重要的超参数,需要根据具体任务进行调整。此外,论文还探讨了预训练数据量对模型融合效果的影响,发现预训练数据越多,模型融合的效果越好。损失函数方面,微调阶段通常使用行为克隆损失或类似的监督学习损失。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法在模拟和真实机器人环境中均取得了显著的性能提升。具体而言,在分布外(out-of-distribution)的新任务变体上,该方法的性能优于单独的预训练模型和微调模型。此外,实验还证明了模型融合的性能随着预训练数据量的增加而提升,并且该方法能够支持机器人在终身学习环境中持续获取新技能。
🎯 应用场景
该研究成果可应用于各种机器人任务,例如家庭服务机器人、工业机器人和自动驾驶汽车。通过该方法,机器人可以快速适应新的环境和任务,而无需从头开始训练,从而降低了开发成本和部署时间。此外,该方法还支持机器人的终身学习,使其能够不断积累知识和技能。
📄 摘要(原文)
Generalist robot policies, trained on large and diverse datasets, have demonstrated the ability to generalize across a wide spectrum of behaviors, enabling a single policy to act in varied real-world environments. However, they still fall short on new tasks not covered in the training data. When finetuned on limited demonstrations of a new task, these policies often overfit to the specific demonstrations--not only losing their prior abilities to solve a wide variety of generalist tasks but also failing to generalize within the new task itself. In this work, we aim to develop a method that preserves the generalization capabilities of the generalist policy during finetuning, allowing a single policy to robustly incorporate a new skill into its repertoire. Our goal is a single policy that both learns to generalize to variations of the new task and retains the broad competencies gained from pretraining. We show that this can be achieved through a simple yet effective strategy: interpolating the weights of a finetuned model with that of the pretrained model. We show, across extensive simulated and real-world experiments, that such model merging produces a single model that inherits the generalist abilities of the base model and learns to solve the new task robustly, outperforming both the pretrained and finetuned model on out-of-distribution variations of the new task. Moreover, we show that model merging performance scales with the amount of pretraining data, and enables continual acquisition of new skills in a lifelong learning setting, without sacrificing previously learned generalist abilities.