Semantic-Metric Bayesian Risk Fields: Learning Robot Safety from Human Videos with a VLM Prior
作者: Timothy Chen, Marcus Dominguez-Kuhne, Aiden Swann, Xu Liu, Mac Schwager
分类: cs.RO
发布日期: 2025-12-09
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出基于VLM先验的语义-度量贝叶斯风险场,从人类视频中学习机器人安全策略。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 机器人安全 风险建模 贝叶斯方法 视觉-语言模型 人机协作 模仿学习 轨迹优化
📋 核心要点
- 现有方法难以捕捉人类对风险的连续、上下文相关和空间依赖的理解,导致机器人行为不自然。
- 论文提出一种基于贝叶斯公式的风险建模方法,利用视觉-语言模型(VLM)提供先验知识,并学习似然函数来调整风险估计。
- 实验表明,该框架能够生成与人类偏好一致的上下文风险,并成功应用于机器人规划和轨迹优化任务中。
📝 摘要(中文)
本文提出了一种从人类演示视频中提取隐式人类风险模型的框架。该框架引入了一种新颖的、语义条件化的、空间变化的风险参数化方法,并利用预训练的视觉-语言模型(VLM)的常识进行监督。风险通过贝叶斯公式定义,VLM提供先验知识。为了使风险估计更符合人类的认知,使用似然函数调节先验,产生相对的度量风险。具体来说,似然函数是一个学习到的ViT,将预训练的特征映射到像素对齐的风险值。该流程以RGB图像和查询对象字符串作为输入,生成像素密集的风险图像。这些图像可用作机器人规划任务中的值预测器,或投影到3D空间中用于传统的轨迹优化,从而产生类似人类的运动。该模型能够泛化到新的对象和环境,并可扩展到更大的训练数据集。贝叶斯框架能够使模型快速适应新的观察或常识规则。实验结果表明,该框架产生的上下文风险与人类偏好一致,并展示了该模型在视觉运动规划和轨迹优化中的应用。
🔬 方法详解
问题定义:现有机器人安全方法通常将安全性视为二元信号,忽略了人类对风险的理解是连续的、依赖于上下文和空间的。这导致机器人的行为在复杂环境中显得不自然,无法很好地与人类协作。因此,需要一种能够学习人类风险感知并将其融入机器人决策过程的方法。
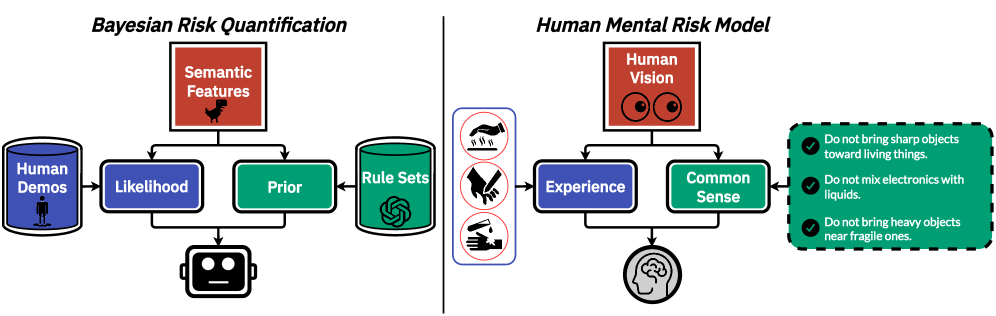
核心思路:论文的核心思路是利用贝叶斯框架,结合视觉-语言模型(VLM)的先验知识和从人类演示视频中学习到的似然函数,来建模人类对风险的理解。VLM提供关于场景中物体和关系的常识性知识,而似然函数则根据观察到的安全行为调整风险估计,使其更符合人类的偏好。
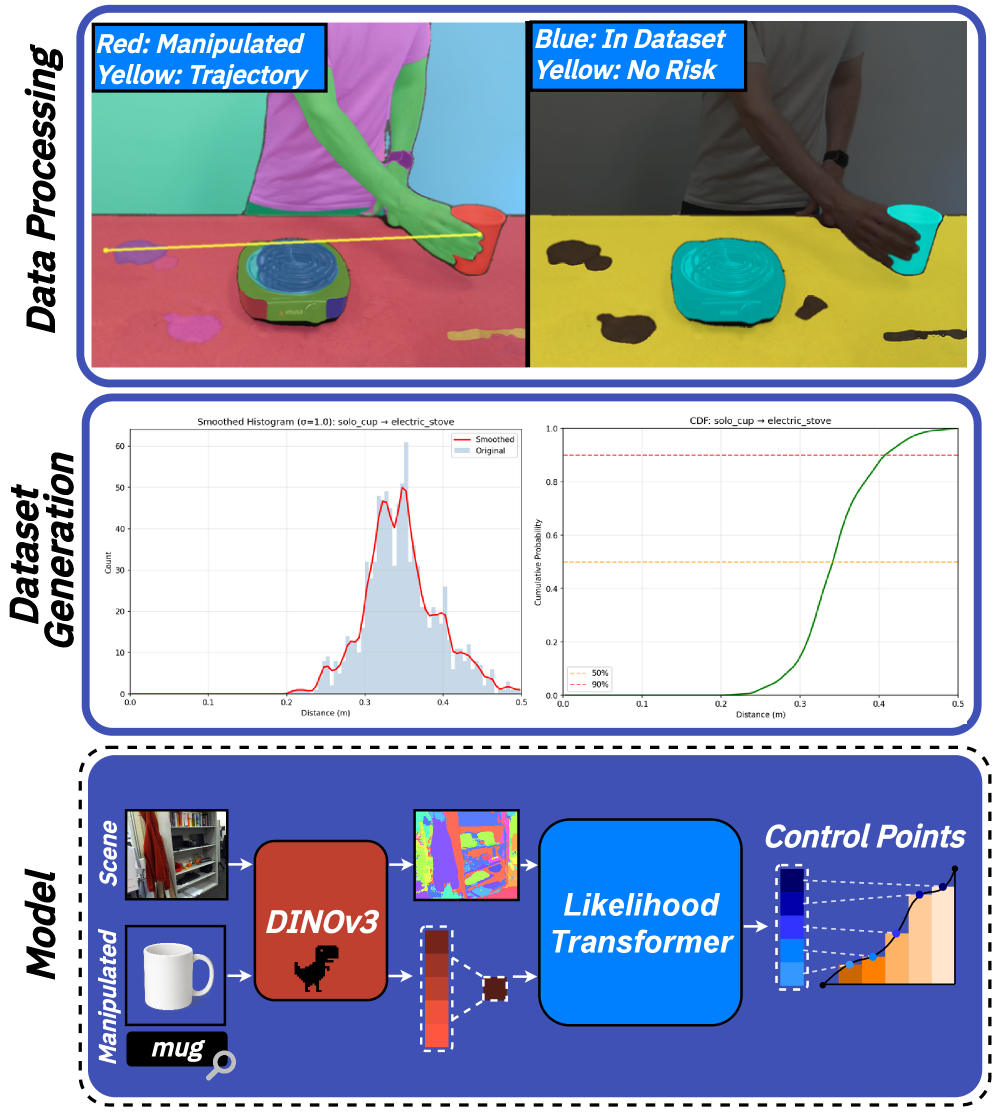
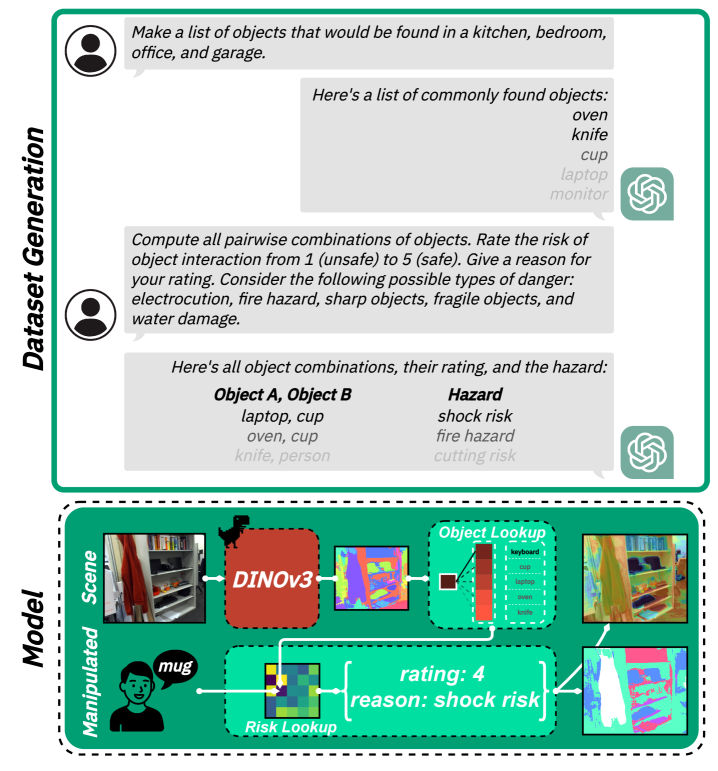
技术框架:该框架主要包含以下几个模块:1) VLM先验模块:使用预训练的VLM(例如CLIP)提取图像的语义特征,作为风险估计的先验知识。2) 似然函数学习模块:使用一个ViT网络,将VLM提取的特征映射到像素级别的风险值。该网络通过监督学习,从人类演示视频中学习人类的安全行为。3) 贝叶斯融合模块:将VLM先验和学习到的似然函数进行贝叶斯融合,得到最终的风险估计。4) 应用模块:将风险估计应用于机器人规划和轨迹优化任务中,指导机器人做出更安全、更符合人类习惯的决策。
关键创新:该论文的关键创新在于:1) 语义-度量风险场:提出了一种新的风险表示方法,将语义信息(来自VLM)和度量信息(来自视觉观察)结合起来,能够更全面地描述风险。2) 贝叶斯风险建模:使用贝叶斯框架来建模风险,能够有效地融合先验知识和观察数据,并能够快速适应新的信息。3) 从人类视频中学习风险:通过监督学习,从人类演示视频中学习人类的安全行为,避免了手动设计风险模型的困难。
关键设计:1) VLM选择:选择CLIP作为VLM,因为它具有强大的视觉和语言理解能力,能够提取丰富的语义特征。2) ViT网络结构:使用ViT作为似然函数,因为它具有强大的特征提取能力和全局感受野。3) 损失函数:使用像素级别的交叉熵损失函数来训练ViT网络,鼓励网络预测的风险值与人类行为一致。4) 贝叶斯融合方法:使用简单的加权平均方法来融合VLM先验和似然函数,权重可以通过交叉验证来确定。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该框架能够生成与人类偏好一致的上下文风险。例如,在包含儿童和玩具的场景中,该模型能够预测儿童和玩具周围的风险较高。此外,该模型在机器人规划和轨迹优化任务中取得了良好的效果,能够生成更安全、更符合人类习惯的机器人运动轨迹。与传统的轨迹优化方法相比,该方法能够显著提高机器人的安全性。
🎯 应用场景
该研究成果可应用于各种机器人应用场景,例如:人机协作、自动驾驶、家庭服务机器人等。通过学习人类的风险感知,机器人可以更好地理解环境,做出更安全、更符合人类习惯的决策,从而提高人机协作的效率和安全性。此外,该方法还可以用于评估现有环境的安全性,例如,评估道路的交通风险,为城市规划提供参考。
📄 摘要(原文)
Humans interpret safety not as a binary signal but as a continuous, context- and spatially-dependent notion of risk. While risk is subjective, humans form rational mental models that guide action selection in dynamic environments. This work proposes a framework for extracting implicit human risk models by introducing a novel, semantically-conditioned and spatially-varying parametrization of risk, supervised directly from safe human demonstration videos and VLM common sense. Notably, we define risk through a Bayesian formulation. The prior is furnished by a pretrained vision-language model. In order to encourage the risk estimate to be more human aligned, a likelihood function modulates the prior to produce a relative metric of risk. Specifically, the likelihood is a learned ViT that maps pretrained features, to pixel-aligned risk values. Our pipeline ingests RGB images and a query object string, producing pixel-dense risk images. These images that can then be used as value-predictors in robot planning tasks or be projected into 3D for use in conventional trajectory optimization to produce human-like motion. This learned mapping enables generalization to novel objects and contexts, and has the potential to scale to much larger training datasets. In particular, the Bayesian framework that is introduced enables fast adaptation of our model to additional observations or common sense rules. We demonstrate that our proposed framework produces contextual risk that aligns with human preferences. Additionally, we illustrate several downstream applications of the model; as a value learner for visuomotor planners or in conjunction with a classical trajectory optimization algorithm. Our results suggest that our framework is a significant step toward enabling autonomous systems to internalize human-like risk. Code and results can be found at https://riskbayesian.github.io/bayesian_risk/.