Ground Slow, Move Fast: A Dual-System Foundation Model for Generalizable Vision-and-Language Navigation
作者: Meng Wei, Chenyang Wan, Jiaqi Peng, Xiqian Yu, Yuqiang Yang, Delin Feng, Wenzhe Cai, Chenming Zhu, Tai Wang, Jiangmiao Pang, Xihui Liu
分类: cs.RO
发布日期: 2025-12-09
💡 一句话要点
提出DualVLN双系统模型,提升视觉-语言导航的泛化性和实时性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言导航 双系统模型 全局规划 局部控制 扩散Transformer 机器人导航 多模态融合
📋 核心要点
- 现有VLN方法依赖端到端pipeline,易产生碎片化运动,延迟高,难以应对动态障碍物等真实世界挑战。
- DualVLN采用双系统架构,VLM负责全局规划,Diffusion Transformer负责局部控制,解耦训练提升泛化性。
- 实验表明,DualVLN在VLN基准测试中表现优异,并在真实动态环境中展现出鲁棒的长程规划和实时适应性。
📝 摘要(中文)
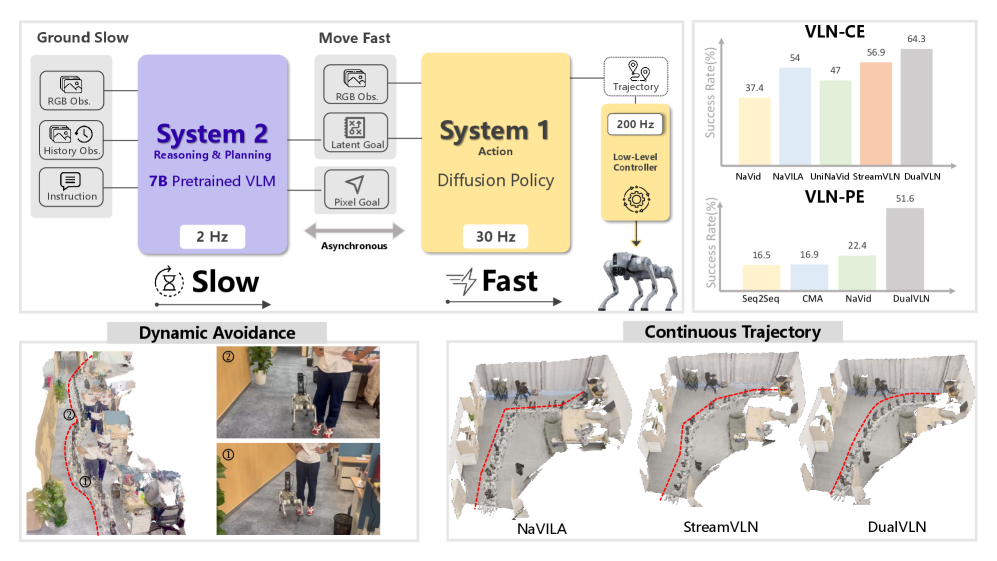
本文提出DualVLN,一种双系统视觉-语言导航(VLN)基础模型,它协同整合了高层推理和低层动作执行。系统2,一个基于VLM的全局规划器,通过图像相关的推理“缓慢地定位”,预测中期航路点目标。系统1,一个轻量级的、多模态条件扩散Transformer策略,通过利用来自系统2的显式像素目标和潜在特征来“快速移动”,生成平滑而准确的轨迹。这种双系统设计实现了在复杂、动态环境中鲁棒的实时控制和自适应的局部决策。通过解耦训练,VLM保留了其泛化能力,而系统1实现了可解释且有效的局部导航。DualVLN在所有VLN基准测试中均优于现有方法,并且真实世界的实验证明了在动态环境中鲁棒的长程规划和实时适应性。
🔬 方法详解
问题定义:现有的视觉-语言导航(VLN)方法通常采用端到端的pipeline,直接将视觉和语言输入映射到短视距的离散动作。这种方法容易产生不连贯的运动,导致较高的延迟,并且难以应对真实世界中动态障碍物等复杂情况。因此,如何提高VLN模型的泛化能力、实时性和鲁棒性,使其能够在复杂动态环境中进行有效的导航,是本文要解决的核心问题。
核心思路:DualVLN的核心思路是将VLN任务分解为高层推理和低层动作执行两个部分,分别由两个独立的系统负责。系统2(全局规划器)负责进行高层推理,根据视觉和语言输入,预测中期航路点目标。系统1(局部控制策略)则负责根据系统2提供的目标和自身的感知信息,生成平滑而准确的轨迹。这种双系统设计可以解耦训练,使VLM保持泛化能力,同时使局部控制策略更加高效和可解释。
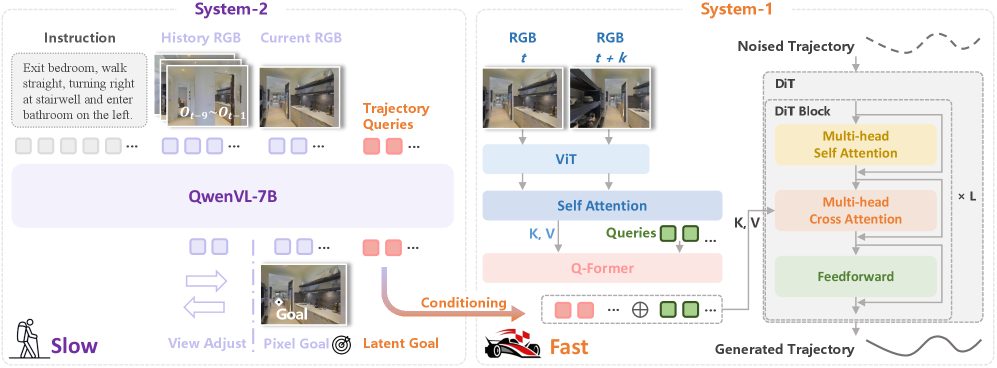
技术框架:DualVLN的整体架构包含两个主要模块:系统2(全局规划器)和系统1(局部控制策略)。系统2是一个基于VLM的全局规划器,它接收视觉和语言输入,通过图像相关的推理,预测中期航路点目标。系统1是一个轻量级的、多模态条件扩散Transformer策略,它接收来自系统2的显式像素目标和潜在特征,以及自身的感知信息,生成平滑而准确的轨迹。这两个系统协同工作,共同完成VLN任务。
关键创新:DualVLN最重要的技术创新点在于其双系统架构,它将高层推理和低层动作执行解耦,分别由VLM和Diffusion Transformer负责。这种设计可以充分利用VLM的泛化能力和Diffusion Transformer的生成能力,从而提高VLN模型的性能和鲁棒性。此外,DualVLN还采用了多模态条件扩散Transformer策略,可以有效地融合来自不同模态的信息,从而生成更加准确的轨迹。
关键设计:系统2使用预训练的VLM作为全局规划器,通过微调使其能够预测中期航路点目标。系统1使用Diffusion Transformer作为局部控制策略,其损失函数包括轨迹预测损失和目标对齐损失。为了提高训练效率,DualVLN采用了解耦训练策略,首先训练系统2,然后固定系统2的参数,训练系统1。在推理阶段,两个系统协同工作,共同完成VLN任务。
🖼️ 关键图片

📊 实验亮点
DualVLN在所有VLN基准测试中均优于现有方法,例如在R2R数据集上,其成功率和SPL指标均显著高于现有最佳模型。在真实世界的实验中,DualVLN展现出鲁棒的长程规划和实时适应性,能够有效地应对动态障碍物等复杂情况。这些实验结果充分证明了DualVLN的有效性和优越性。
🎯 应用场景
DualVLN具有广泛的应用前景,例如:服务型机器人可以在家庭、办公室等环境中自主导航;自动驾驶汽车可以在城市道路上安全行驶;无人机可以进行自主巡检和物流配送。该研究成果有助于推动机器人、自动驾驶和无人机等领域的发展,提高其智能化水平和服务能力。
📄 摘要(原文)
While recent large vision-language models (VLMs) have improved generalization in vision-language navigation (VLN), existing methods typically rely on end-to-end pipelines that map vision-language inputs directly to short-horizon discrete actions. Such designs often produce fragmented motions, incur high latency, and struggle with real-world challenges like dynamic obstacle avoidance. We propose DualVLN, the first dual-system VLN foundation model that synergistically integrates high-level reasoning with low-level action execution. System 2, a VLM-based global planner, "grounds slowly" by predicting mid-term waypoint goals via image-grounded reasoning. System 1, a lightweight, multi-modal conditioning Diffusion Transformer policy, "moves fast" by leveraging both explicit pixel goals and latent features from System 2 to generate smooth and accurate trajectories. The dual-system design enables robust real-time control and adaptive local decision-making in complex, dynamic environments. By decoupling training, the VLM retains its generalization, while System 1 achieves interpretable and effective local navigation. DualVLN outperforms prior methods across all VLN benchmarks and real-world experiments demonstrate robust long-horizon planning and real-time adaptability in dynamic environments.