An Introduction to Deep Reinforcement and Imitation Learning
作者: Pedro Santana
分类: cs.RO, cs.LG
发布日期: 2025-12-08 (更新: 2025-12-11)
💡 一句话要点
深度强化学习与模仿学习入门教程,聚焦具身智能体控制
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 深度强化学习 模仿学习 具身智能体 机器人控制 序列决策
📋 核心要点
- 具身智能体控制面临序列决策难题,传统手动设计控制器方法难以应对复杂任务。
- 论文采用深度强化学习和模仿学习,分别通过奖励信号和专家演示来优化智能体行为。
- 教程聚焦核心算法和技术,如PPO、REINFORCE、DAgger和GAIL,注重深入理解而非全面覆盖。
📝 摘要(中文)
具身智能体,如机器人和虚拟角色,必须持续选择动作以有效地执行任务,从而解决复杂的序列决策问题。鉴于手动设计此类控制器的难度,基于学习的方法已经成为有希望的替代方案,其中最值得注意的是深度强化学习(DRL)和深度模仿学习(DIL)。DRL利用奖励信号来优化行为,而DIL使用专家演示来指导学习。本文档介绍了具身智能体背景下的DRL和DIL,采用了一种简洁的、深度优先的方法来介绍相关文献。它是自包含的,在需要时介绍所有必要的数学和机器学习概念。它并非旨在对该领域进行综述;相反,它侧重于一小部分基础算法和技术,优先考虑深入理解而非广泛覆盖。材料范围从马尔可夫决策过程到用于DRL的REINFORCE和近端策略优化(PPO),以及用于DIL的从行为克隆到数据集聚合(DAgger)和生成对抗模仿学习(GAIL)。
🔬 方法详解
问题定义:具身智能体需要在复杂环境中学习有效的控制策略,以完成特定任务。传统的手动设计控制器方法难以适应环境变化和任务复杂性,需要耗费大量人力和时间,且难以保证控制效果的最优性。因此,如何让智能体自主学习控制策略成为一个重要的研究问题。
核心思路:论文的核心思路是利用深度强化学习(DRL)和深度模仿学习(DIL)两种方法,使智能体能够通过与环境交互或学习专家演示来自动获取控制策略。DRL通过最大化累积奖励来优化策略,而DIL则通过模仿专家行为来学习策略。
技术框架:该教程涵盖了DRL和DIL领域的核心算法。DRL部分主要介绍了马尔可夫决策过程(MDP)、REINFORCE算法和近端策略优化(PPO)算法。DIL部分主要介绍了行为克隆(BC)、数据集聚合(DAgger)和生成对抗模仿学习(GAIL)算法。整体框架是从基础概念到高级算法的逐步深入,旨在帮助读者理解DRL和DIL的基本原理和应用。
关键创新:该教程的关键创新在于其简洁和深度优先的教学方法。它没有试图全面覆盖DRL和DIL领域的所有算法,而是选择了一小部分基础算法和技术进行深入讲解,并通过自包含的方式介绍了所有必要的数学和机器学习概念,使得读者能够更容易理解和掌握这些算法的原理和应用。
关键设计:在DRL部分,PPO算法的关键设计在于其裁剪的替代目标函数,该函数通过限制策略更新的幅度来提高训练的稳定性。在DIL部分,GAIL算法的关键设计在于使用生成对抗网络来学习专家策略的隐式表示,从而避免了显式地建模奖励函数。
🖼️ 关键图片
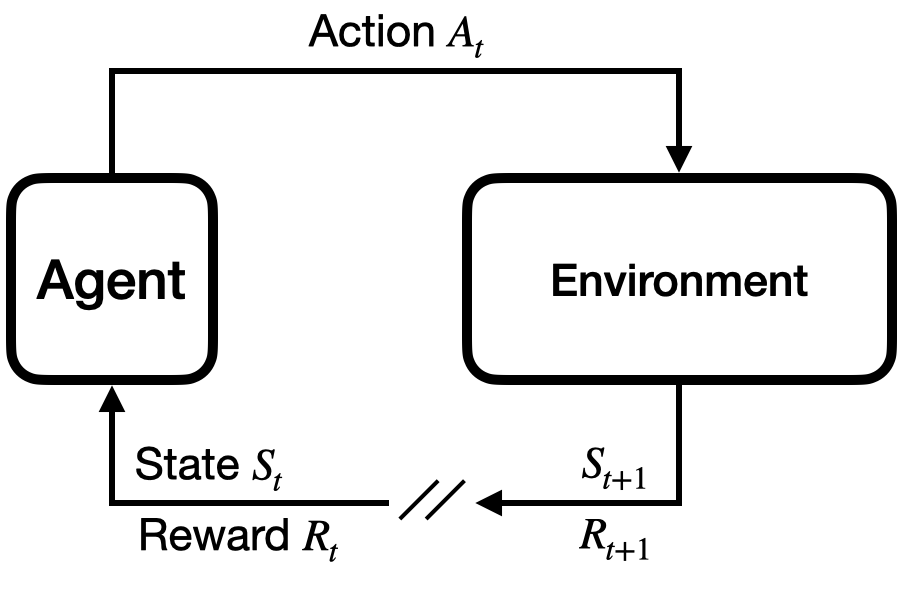
📊 实验亮点
该教程重点介绍了PPO、REINFORCE、DAgger和GAIL等经典算法,并提供了详细的理论解释和代码示例。虽然没有提供具体的实验数据,但通过对这些算法的深入讲解,读者可以更好地理解其原理和应用,并能够将其应用于实际问题中。教程强调了对基础算法的深入理解,而非对所有算法的泛泛而谈。
🎯 应用场景
该研究成果可广泛应用于机器人控制、自动驾驶、游戏AI等领域。通过深度强化学习和模仿学习,可以训练智能体在复杂环境中自主完成各种任务,例如机器人导航、物体抓取、自动驾驶车辆的路径规划等,从而提高生产效率和安全性,并为人们的生活带来便利。
📄 摘要(原文)
Embodied agents, such as robots and virtual characters, must continuously select actions to execute tasks effectively, solving complex sequential decision-making problems. Given the difficulty of designing such controllers manually, learning-based approaches have emerged as promising alternatives, most notably Deep Reinforcement Learning (DRL) and Deep Imitation Learning (DIL). DRL leverages reward signals to optimize behavior, while DIL uses expert demonstrations to guide learning. This document introduces DRL and DIL in the context of embodied agents, adopting a concise, depth-first approach to the literature. It is self-contained, presenting all necessary mathematical and machine learning concepts as they are needed. It is not intended as a survey of the field; rather, it focuses on a small set of foundational algorithms and techniques, prioritizing in-depth understanding over broad coverage. The material ranges from Markov Decision Processes to REINFORCE and Proximal Policy Optimization (PPO) for DRL, and from Behavioral Cloning to Dataset Aggregation (DAgger) and Generative Adversarial Imitation Learning (GAIL) for DIL.