VLD: Visual Language Goal Distance for Reinforcement Learning Navigation
作者: Lazar Milikic, Manthan Patel, Jonas Frey
分类: cs.RO, cs.CV
发布日期: 2025-12-08
💡 一句话要点
VLD:视觉语言目标距离学习,用于强化学习导航
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 视觉导航 目标导向 自监督学习 视觉语言 机器人 距离预测
📋 核心要点
- 现有端到端导航策略训练方法存在sim-to-real差距或标注数据有限的问题。
- VLD通过解耦感知和策略学习,利用自监督学习大规模视频数据来预测目标距离。
- 实验表明,VLD在模拟环境中实现了良好的导航性能,并支持图像和文本等多种目标模态。
📝 摘要(中文)
本文提出了一种视觉语言距离(VLD)学习框架,用于解决机器人系统中基于图像数据端到端训练导航策略的难题。该框架将感知学习与策略学习解耦,首先在互联网规模的视频数据上训练一个自监督的目标距离预测器,该预测器可以泛化到基于图像和文本的目标。然后,利用该预测器提供的距离信号,通过强化学习(RL)训练导航策略。RL策略完全在模拟环境中训练,使用特权几何距离信号,并注入噪声来模拟距离预测器的不确定性。在部署时,策略使用VLD预测,继承大规模视觉训练中的语义目标信息,同时保留在模拟中学习到的鲁棒的低级导航行为。实验表明,VLD优于先前的时序距离方法,并在模拟中实现了具有竞争力的导航性能,同时支持灵活的目标模态。
🔬 方法详解
问题定义:现有基于图像的端到端强化学习导航方法,直接从像素预测动作,面临训练数据不足和泛化性差的问题,尤其是在真实机器人部署时,sim-to-real的差距显著。此外,获取带有动作标签的大量训练数据成本高昂。因此,需要一种可扩展的、能够利用无标签数据进行学习的导航方法。
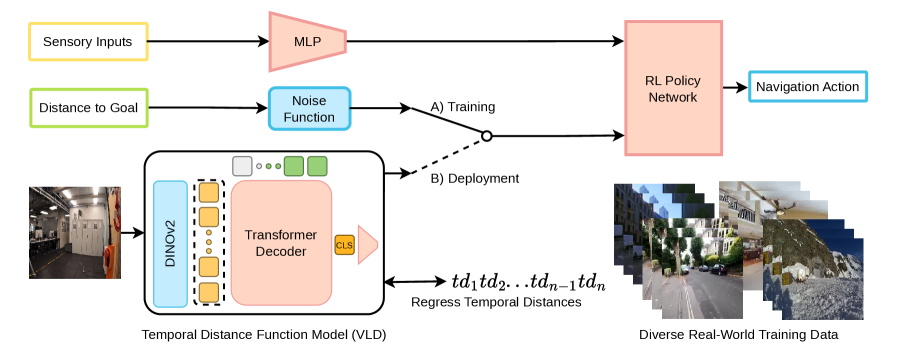
核心思路:论文的核心思路是将导航任务分解为两个阶段:首先,利用大规模无标签视频数据学习一个视觉语言目标距离预测器(VLD),该预测器能够估计当前状态与目标之间的距离。然后,利用该距离预测器作为奖励信号,在模拟环境中训练强化学习策略,策略的目标是最小化到目标的距离。这种解耦的方式使得策略学习不再依赖于原始像素输入,而是依赖于语义化的距离信息,从而提高了泛化能力和鲁棒性。
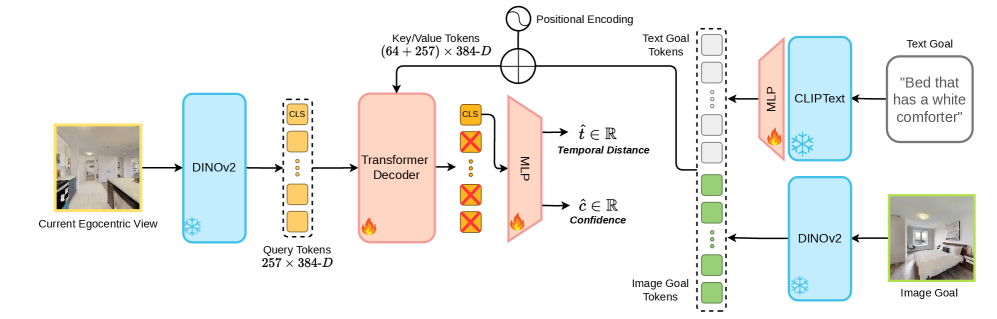
技术框架:VLD框架包含两个主要模块:1) 视觉语言目标距离预测器:该模块使用Transformer架构,输入当前帧的图像特征和目标描述(图像或文本),输出预测的距离。该模块通过自监督学习进行训练,利用视频中的时间信息作为监督信号,学习预测相邻帧之间的距离。2) 强化学习策略:该模块使用强化学习算法(如PPO)在模拟环境中进行训练,其目标是最小化到目标的距离。奖励函数基于VLD预测的距离,并加入噪声来模拟VLD预测的不确定性。
关键创新:论文的关键创新在于提出了视觉语言目标距离(VLD)的概念,并将其应用于强化学习导航。VLD将感知学习与策略学习解耦,使得策略学习不再依赖于原始像素输入,而是依赖于语义化的距离信息。此外,VLD利用大规模无标签视频数据进行自监督学习,从而提高了模型的泛化能力。
关键设计:VLD预测器使用Transformer架构,图像特征通过预训练的视觉模型(如ResNet)提取,文本特征通过预训练的文本模型(如BERT)提取。距离预测采用回归的方式,损失函数为均方误差。为了提高模型的鲁棒性,在训练过程中加入了数据增强和噪声注入。强化学习策略使用PPO算法,奖励函数为负的VLD预测距离,并加入噪声来鼓励探索。
🖼️ 关键图片
📊 实验亮点
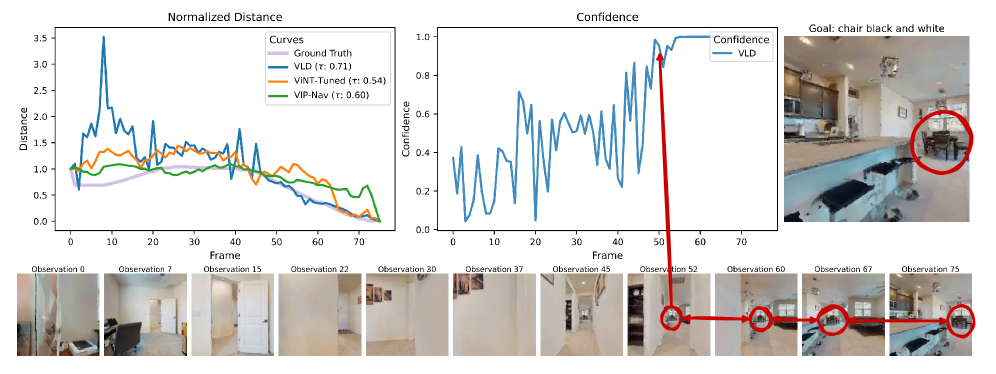
实验结果表明,VLD在模拟环境中实现了具有竞争力的导航性能,优于先前的时序距离方法,例如ViNT和VIP。VLD能够成功地利用图像和文本目标进行导航,并且在不同的模拟环境中具有良好的泛化能力。此外,实验还验证了VLD的鲁棒性,即使在存在噪声和干扰的情况下,VLD仍然能够提供准确的距离预测。
🎯 应用场景
该研究成果可应用于各种机器人导航场景,例如家庭服务机器人、自动驾驶汽车、物流机器人等。通过利用大规模无标签数据进行学习,可以降低对标注数据的依赖,提高机器人的泛化能力和鲁棒性。此外,VLD框架支持多种目标模态,使得机器人可以根据用户的图像或文本指令进行导航,提高了人机交互的灵活性。
📄 摘要(原文)
Training end-to-end policies from image data to directly predict navigation actions for robotic systems has proven inherently difficult. Existing approaches often suffer from either the sim-to-real gap during policy transfer or a limited amount of training data with action labels. To address this problem, we introduce Vision-Language Distance (VLD) learning, a scalable framework for goal-conditioned navigation that decouples perception learning from policy learning. Instead of relying on raw sensory inputs during policy training, we first train a self-supervised distance-to-goal predictor on internet-scale video data. This predictor generalizes across both image- and text-based goals, providing a distance signal that can be minimized by a reinforcement learning (RL) policy. The RL policy can be trained entirely in simulation using privileged geometric distance signals, with injected noise to mimic the uncertainty of the trained distance predictor. At deployment, the policy consumes VLD predictions, inheriting semantic goal information-"where to go"-from large-scale visual training while retaining the robust low-level navigation behaviors learned in simulation. We propose using ordinal consistency to assess distance functions directly and demonstrate that VLD outperforms prior temporal distance approaches, such as ViNT and VIP. Experiments show that our decoupled design achieves competitive navigation performance in simulation while supporting flexible goal modalities, providing an alternative and, most importantly, scalable path toward reliable, multimodal navigation policies.