VideoVLA: Video Generators Can Be Generalizable Robot Manipulators
作者: Yichao Shen, Fangyun Wei, Zhiying Du, Yaobo Liang, Yan Lu, Jiaolong Yang, Nanning Zheng, Baining Guo
分类: cs.RO, cs.AI, cs.CV
发布日期: 2025-12-07
备注: Project page: https://videovla-nips2025.github.io
期刊: The Thirty-ninth Annual Conference on Neural Information Processing Systems(NeurIPS2025)
💡 一句话要点
VideoVLA:利用视频生成模型实现通用机器人操作
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人操作 视觉语言动作模型 视频生成模型 扩散模型 多模态学习
📋 核心要点
- 现有VLA模型在泛化到新任务、对象和环境方面存在局限性,难以适应开放世界。
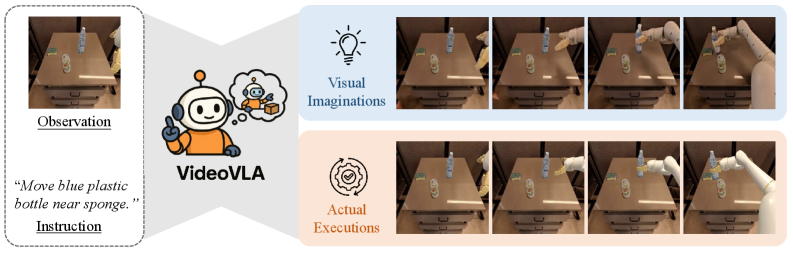
- VideoVLA将大型视频生成模型转化为机器人VLA操作器,通过预测动作序列和未来视觉结果实现泛化。
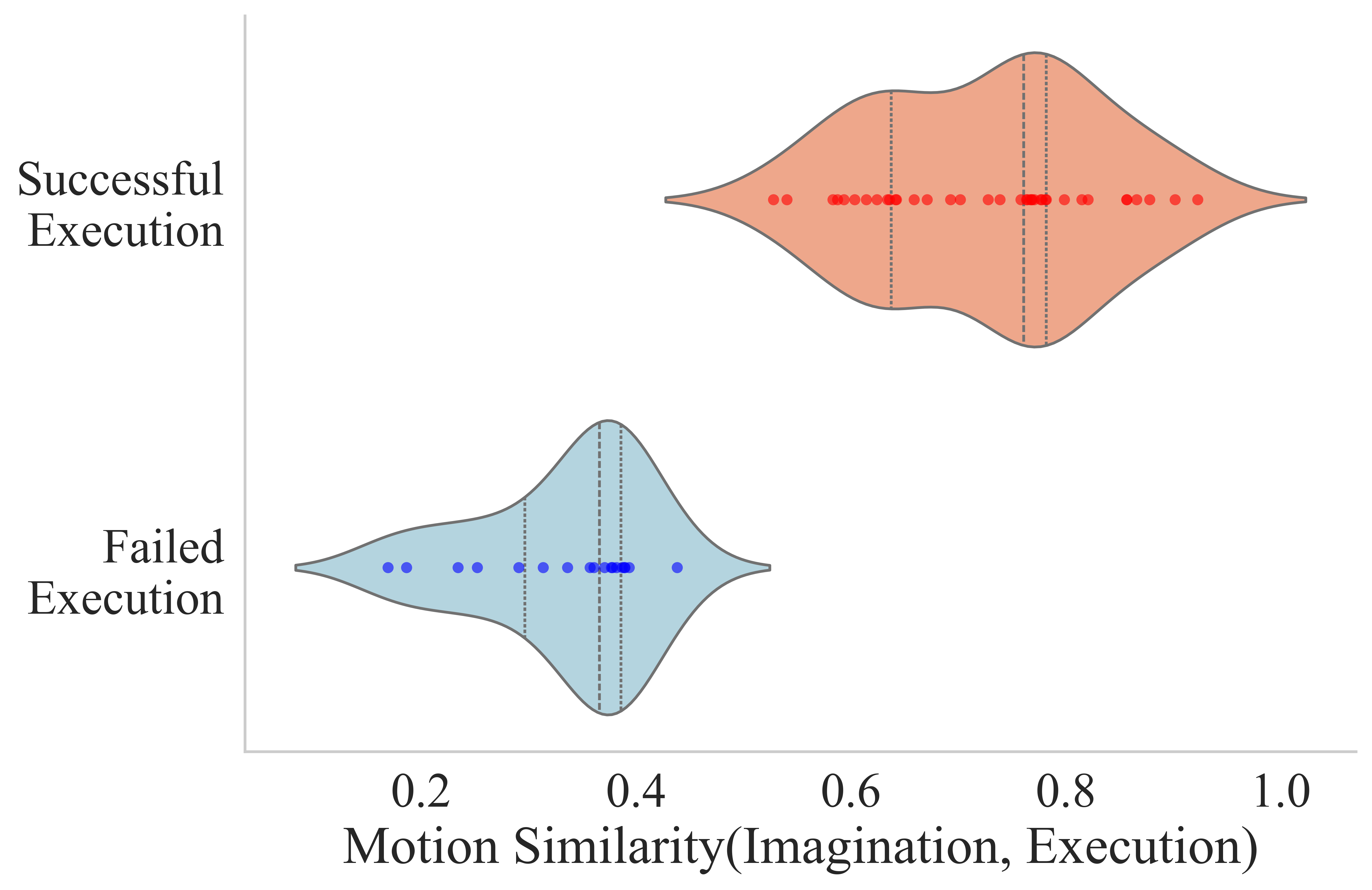
- 实验表明,高质量的视觉预测与可靠的动作预测和任务成功相关,验证了该方法的有效性。
📝 摘要(中文)
机器人操作中的泛化能力对于在开放世界环境中部署机器人以及推进通用人工智能至关重要。现有的视觉-语言-动作(VLA)模型利用大型预训练理解模型进行感知和指令跟随,但它们泛化到新任务、新对象和新环境的能力仍然有限。本文提出了VideoVLA,一种简单的方法,探索了将大型视频生成模型转化为机器人VLA操作器的潜力。给定语言指令和图像,VideoVLA预测动作序列以及未来的视觉结果。VideoVLA建立在多模态扩散Transformer之上,联合建模视频、语言和动作模态,并使用预训练的视频生成模型进行联合视觉和动作预测。实验表明,高质量的想象未来与可靠的动作预测和任务成功相关,突出了视觉想象在操作中的重要性。VideoVLA展示了强大的泛化能力,包括模仿其他机器人的技能和处理新对象。这种双重预测策略——预测动作及其视觉结果——探索了机器人学习中的范式转变,并释放了操作系统的泛化能力。
🔬 方法详解
问题定义:现有机器人操作模型,特别是VLA模型,在面对新的任务、物体和环境时,泛化能力不足。它们依赖于特定任务的训练数据,难以适应开放世界环境中的复杂性和变化。现有方法的痛点在于缺乏对未来状态的预测和规划能力,导致难以做出合理的动作决策。
核心思路:VideoVLA的核心思路是将大型视频生成模型的能力迁移到机器人操作任务中。通过让模型预测执行动作后的未来视觉状态,从而赋予机器人“想象”能力,使其能够更好地理解指令并规划动作。这种方法将动作预测与视觉预测相结合,形成一个闭环反馈系统。
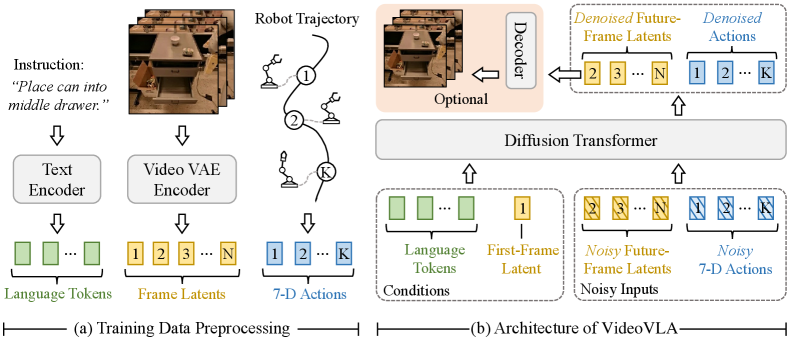
技术框架:VideoVLA基于多模态扩散Transformer架构,联合建模视频、语言和动作三种模态。该框架包含以下主要模块:1) 语言编码器:将语言指令编码为向量表示。2) 视觉编码器:将当前环境的图像编码为向量表示。3) 扩散Transformer:基于语言和视觉编码,预测未来的视频帧和相应的动作序列。4) 动作执行器:将预测的动作序列转化为机器人控制指令。
关键创新:VideoVLA最重要的技术创新点在于将视频生成模型应用于机器人操作任务,并采用双重预测策略,即同时预测动作和视觉结果。这种方法使得模型能够更好地理解指令的意图,并规划出更合理的动作序列。与现有方法相比,VideoVLA不再仅仅依赖于对动作的直接预测,而是通过预测未来状态来指导动作决策,从而提高了泛化能力。
关键设计:VideoVLA的关键设计包括:1) 使用预训练的视频生成模型作为视觉预测的基础,从而利用了大规模视频数据的先验知识。2) 采用扩散模型进行视频生成,能够生成高质量、多样化的未来视觉状态。3) 设计合适的损失函数,鼓励模型预测的动作与视觉结果保持一致性。4) 通过调整Transformer的结构和参数,优化模型的性能。
🖼️ 关键图片
📊 实验亮点
VideoVLA在多个机器人操作任务上取得了显著的性能提升,展示了强大的泛化能力。例如,在模仿其他机器人技能的任务中,VideoVLA能够成功地学习并执行新的动作序列。在处理新对象的任务中,VideoVLA能够根据对象的形状和属性,规划出合适的抓取和操作策略。实验结果表明,VideoVLA的性能优于现有的VLA模型,并且能够更好地适应开放世界环境。
🎯 应用场景
VideoVLA具有广泛的应用前景,包括:1) 智能家居:机器人可以根据用户的语音指令完成各种家务任务。2) 工业自动化:机器人可以灵活地适应生产线的变化,完成不同的装配和搬运任务。3) 医疗辅助:机器人可以协助医生进行手术和康复治疗。该研究的实际价值在于提高了机器人的智能化水平和泛化能力,为实现通用机器人奠定了基础。未来,VideoVLA有望推动机器人技术在更多领域得到应用。
📄 摘要(原文)
Generalization in robot manipulation is essential for deploying robots in open-world environments and advancing toward artificial general intelligence. While recent Vision-Language-Action (VLA) models leverage large pre-trained understanding models for perception and instruction following, their ability to generalize to novel tasks, objects, and settings remains limited. In this work, we present VideoVLA, a simple approach that explores the potential of transforming large video generation models into robotic VLA manipulators. Given a language instruction and an image, VideoVLA predicts an action sequence as well as the future visual outcomes. Built on a multi-modal Diffusion Transformer, VideoVLA jointly models video, language, and action modalities, using pre-trained video generative models for joint visual and action forecasting. Our experiments show that high-quality imagined futures correlate with reliable action predictions and task success, highlighting the importance of visual imagination in manipulation. VideoVLA demonstrates strong generalization, including imitating other embodiments' skills and handling novel objects. This dual-prediction strategy - forecasting both actions and their visual consequences - explores a paradigm shift in robot learning and unlocks generalization capabilities in manipulation systems.