Task adaptation of Vision-Language-Action model: 1st Place Solution for the 2025 BEHAVIOR Challenge
作者: Ilia Larchenko, Gleb Zarin, Akash Karnatak
分类: cs.RO, cs.AI, cs.CV, cs.LG
发布日期: 2025-12-07 (更新: 2025-12-21)
备注: 2025 NeurIPS Behavior Challenge 1st place solution
💡 一句话要点
针对BEHAVIOR挑战赛,提出基于相关噪声和混合注意力机制的视觉-语言-动作模型
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言-动作模型 BEHAVIOR挑战赛 流匹配 相关噪声 混合层注意力 机器人操作 长时程任务
📋 核心要点
- 现有方法在长时程家庭任务中,难以兼顾双手操作、导航和上下文感知决策,面临效率和动作平滑性挑战。
- 论文提出基于Pi0.5架构的视觉-语言-动作模型,引入相关噪声流匹配和混合层注意力机制,提升训练效率和动作连贯性。
- 该方法在BEHAVIOR挑战赛中获得第一名,在50个任务上实现了26%的q-score,验证了其有效性。
📝 摘要(中文)
本文提出了一种视觉-动作策略,该策略在2025年BEHAVIOR挑战赛中荣获第一名。该挑战赛是一个大规模基准,包含50个不同的长时程家庭任务,这些任务需要在逼真的照片级模拟环境中进行双手操作、导航和上下文感知的决策。在Pi0.5架构的基础上,我们引入了几项创新。我们的主要贡献是用于流匹配的相关噪声,它提高了训练效率,并实现了相关感知的图像修复,从而获得平滑的动作序列。我们还应用了可学习的混合层注意力机制和用于歧义消除的System 2阶段跟踪。训练采用多样本流匹配来减少方差,而推理则使用动作压缩和特定于挑战的校正规则。我们的方法在公共和私有排行榜上的所有50个任务中均实现了26%的q-score。
🔬 方法详解
问题定义:BEHAVIOR挑战赛旨在评估智能体在复杂家庭环境中完成长时程任务的能力,这些任务涉及双手操作、导航和上下文理解。现有方法在处理此类任务时,面临训练效率低、动作序列不平滑以及难以消除歧义等问题。尤其是在模拟环境中,如何让智能体学习到更鲁棒、更自然的动作策略是一个关键挑战。
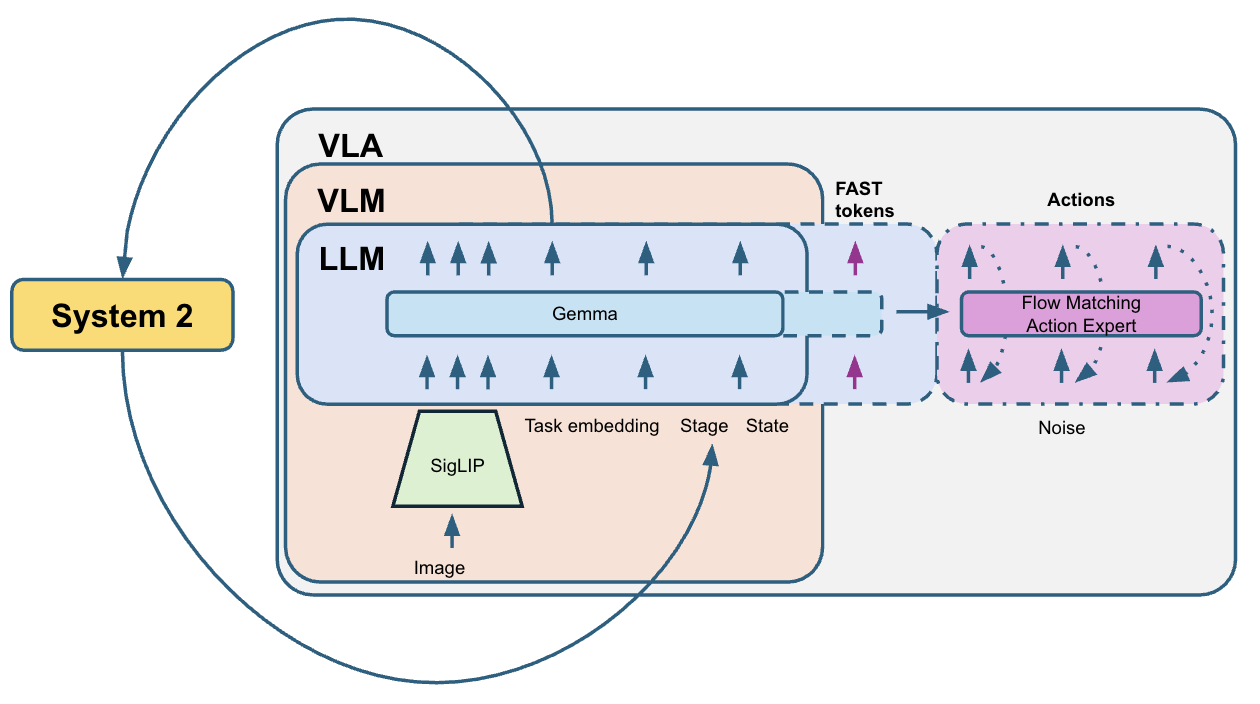
核心思路:本文的核心思路是通过引入相关噪声来改进流匹配训练,从而提高训练效率并生成更平滑的动作序列。此外,利用可学习的混合层注意力机制和System 2阶段跟踪来解决歧义问题,使智能体能够更好地理解任务目标和环境状态。
技术框架:该方法基于Pi0.5架构,整体框架包括视觉感知模块、语言理解模块、动作生成模块和环境交互模块。视觉感知模块负责从环境中提取视觉信息,语言理解模块负责解析任务指令,动作生成模块根据视觉和语言信息生成动作序列,环境交互模块负责将动作应用于模拟环境并获取反馈。System 2阶段跟踪用于在必要时进行更深入的推理和规划。
关键创新:最重要的技术创新点是相关噪声流匹配。传统的流匹配方法通常使用独立噪声,而本文提出的相关噪声能够更好地捕捉动作之间的依赖关系,从而生成更平滑的动作序列。此外,可学习的混合层注意力机制能够自适应地选择不同层级的特征,从而提高模型的表达能力。
关键设计:在训练过程中,采用多样本流匹配来减少方差,提高训练的稳定性。在推理过程中,使用动作压缩来减少动作序列的长度,提高推理效率。此外,还针对BEHAVIOR挑战赛的特定任务设计了一些校正规则,以进一步提高性能。具体参数设置和网络结构细节未在摘要中详细说明,属于未知信息。
🖼️ 关键图片


📊 实验亮点
该方法在2025年BEHAVIOR挑战赛中获得第一名,证明了其在复杂家庭环境任务中的有效性。在所有50个任务中,该方法在公共和私有排行榜上均实现了26%的q-score,显著优于其他参赛队伍,体现了相关噪声流匹配和混合层注意力机制的优越性。
🎯 应用场景
该研究成果可应用于机器人领域,尤其是在家庭服务机器人、工业自动化等场景中。通过提升机器人的操作能力和决策能力,使其能够更好地完成复杂任务,提高工作效率和生活质量。未来,该技术有望扩展到更多领域,如医疗、教育等。
📄 摘要(原文)
We present a vision-action policy that won 1st place in the 2025 BEHAVIOR Challenge - a large-scale benchmark featuring 50 diverse long-horizon household tasks in photo-realistic simulation, requiring bimanual manipulation, navigation, and context-aware decision making. Building on the Pi0.5 architecture, we introduce several innovations. Our primary contribution is correlated noise for flow matching, which improves training efficiency and enables correlation-aware inpainting for smooth action sequences. We also apply learnable mixed-layer attention and System 2 stage tracking for ambiguity resolution. Training employs multi-sample flow matching to reduce variance, while inference uses action compression and challenge-specific correction rules. Our approach achieves 26% q-score across all 50 tasks on both public and private leaderboards.