Dynamic Visual SLAM using a General 3D Prior
作者: Xingguang Zhong, Liren Jin, Marija Popović, Jens Behley, Cyrill Stachniss
分类: cs.RO, cs.CV
发布日期: 2025-12-07
备注: 8 pages
💡 一句话要点
提出一种利用通用3D先验的动态视觉SLAM系统,提升动态场景下的相机位姿估计精度。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 视觉SLAM 动态场景 单目视觉 深度学习 Bundle Adjustment 三维重建 相机位姿估计
📋 核心要点
- 在动态自然环境中,场景动态性会严重降低相机位姿估计的准确性,这是视觉SLAM面临的关键挑战。
- 论文提出一种结合几何块状Bundle Adjustment和前馈重建模型的单目视觉SLAM系统,利用深度预测过滤动态区域并增强鲁棒性。
- 通过对齐深度预测和Bundle Adjustment估计的块,系统能够有效处理前馈重建模型中的尺度模糊问题,提升位姿估计精度。
📝 摘要(中文)
本文提出了一种新颖的单目视觉SLAM系统,能够在动态场景中稳健地估计相机位姿。该系统利用了几何块状在线Bundle Adjustment和最新的前馈重建模型的互补优势。具体而言,我们提出了一个前馈重建模型来精确地过滤掉动态区域,同时利用其深度预测来增强基于块状的视觉SLAM的鲁棒性。通过将深度预测与Bundle Adjustment估计的块对齐,我们能够稳健地处理前馈重建模型分批应用时固有的尺度模糊性。
🔬 方法详解
问题定义:论文旨在解决动态场景下单目视觉SLAM中相机位姿估计精度下降的问题。现有方法在动态环境下容易受到运动物体的影响,导致特征点匹配错误,从而降低位姿估计的准确性和鲁棒性。
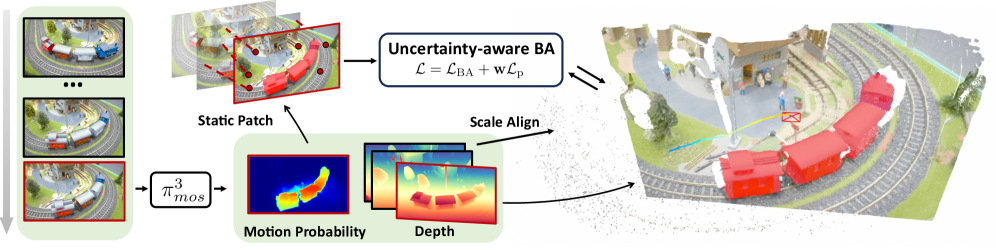
核心思路:论文的核心思路是结合几何方法(Bundle Adjustment)和深度学习方法(前馈重建模型)的优势。利用前馈重建模型预测场景深度并过滤动态区域,从而减少动态物体对位姿估计的影响。同时,利用Bundle Adjustment的几何约束来校正前馈重建模型的尺度漂移。
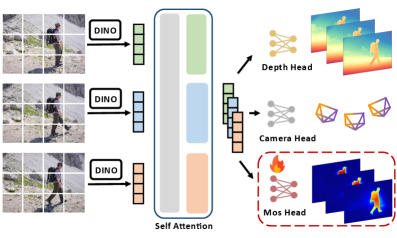
技术框架:该系统主要包含以下几个模块:1) 特征提取与匹配:提取图像特征点并进行匹配。2) 前馈重建模型:利用预训练的深度学习模型预测场景深度,并根据深度信息过滤动态区域。3) 基于块状的Bundle Adjustment:利用剩余的静态特征点进行Bundle Adjustment优化,估计相机位姿和三维结构。4) 深度预测对齐:将前馈重建模型的深度预测与Bundle Adjustment估计的块对齐,校正尺度漂移。
关键创新:论文的关键创新在于将前馈重建模型和几何Bundle Adjustment相结合,利用深度学习模型过滤动态区域,并利用几何方法校正深度学习模型的尺度漂移。这种结合方式能够充分利用两种方法的优势,提高动态场景下的位姿估计精度和鲁棒性。
关键设计:论文的关键设计包括:1) 使用预训练的深度学习模型进行深度预测。2) 设计了一种基于深度信息的动态区域过滤方法。3) 使用基于块状的Bundle Adjustment来提高鲁棒性。4) 设计了一种深度预测对齐方法,利用Bundle Adjustment的几何约束来校正前馈重建模型的尺度漂移。具体的损失函数和网络结构等细节在论文中进行了详细描述。
🖼️ 关键图片

📊 实验亮点
论文通过实验验证了所提出方法的有效性。实验结果表明,该方法在动态场景下的相机位姿估计精度明显优于现有的单目视觉SLAM系统。具体的性能提升幅度在论文中进行了详细的量化分析,并与多个基线方法进行了对比。
🎯 应用场景
该研究成果可应用于机器人导航、增强现实、三维重建等领域。在动态环境中,例如人流密集的街道或家庭环境中,该系统能够更准确地估计相机位姿,从而提高机器人的自主导航能力和增强现实应用的体验。此外,该方法还可以用于动态场景的三维重建,为虚拟现实和游戏等领域提供更逼真的场景模型。
📄 摘要(原文)
Reliable incremental estimation of camera poses and 3D reconstruction is key to enable various applications including robotics, interactive visualization, and augmented reality. However, this task is particularly challenging in dynamic natural environments, where scene dynamics can severely deteriorate camera pose estimation accuracy. In this work, we propose a novel monocular visual SLAM system that can robustly estimate camera poses in dynamic scenes. To this end, we leverage the complementary strengths of geometric patch-based online bundle adjustment and recent feed-forward reconstruction models. Specifically, we propose a feed-forward reconstruction model to precisely filter out dynamic regions, while also utilizing its depth prediction to enhance the robustness of the patch-based visual SLAM. By aligning depth prediction with estimated patches from bundle adjustment, we robustly handle the inherent scale ambiguities of the batch-wise application of the feed-forward reconstruction model.