A New Trajectory-Oriented Approach to Enhancing Comprehensive Crowd Navigation Performance
作者: Xinyu Zhou, Songhao Piao, Chao Gao, Liguo Chen
分类: cs.RO
发布日期: 2025-12-07
备注: 8 pages, 6 figures
💡 一句话要点
提出一种新的面向轨迹的crowd navigation方法,提升综合性能。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: Crowd Navigation 深度强化学习 轨迹优化 奖励塑造 轨迹平滑 机器人导航 多目标优化
📋 核心要点
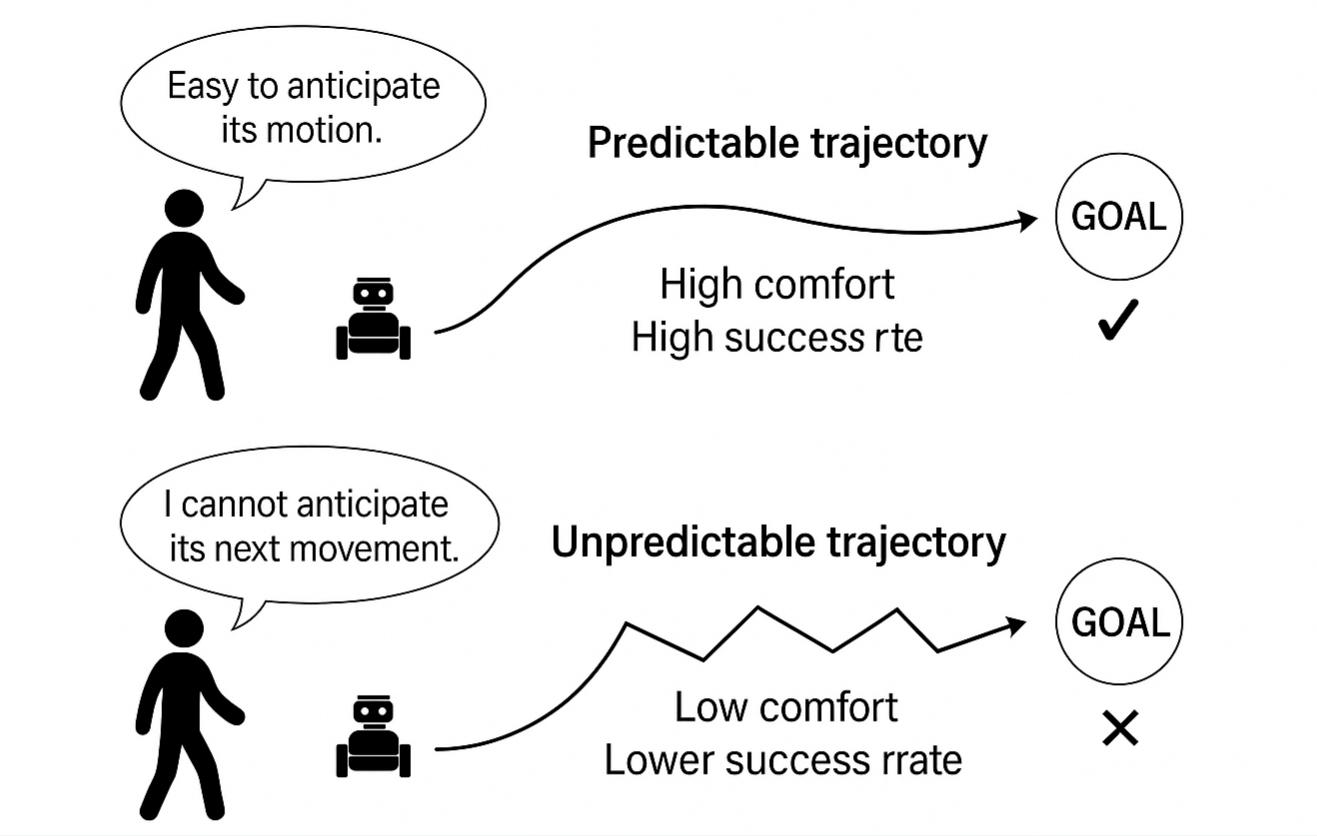
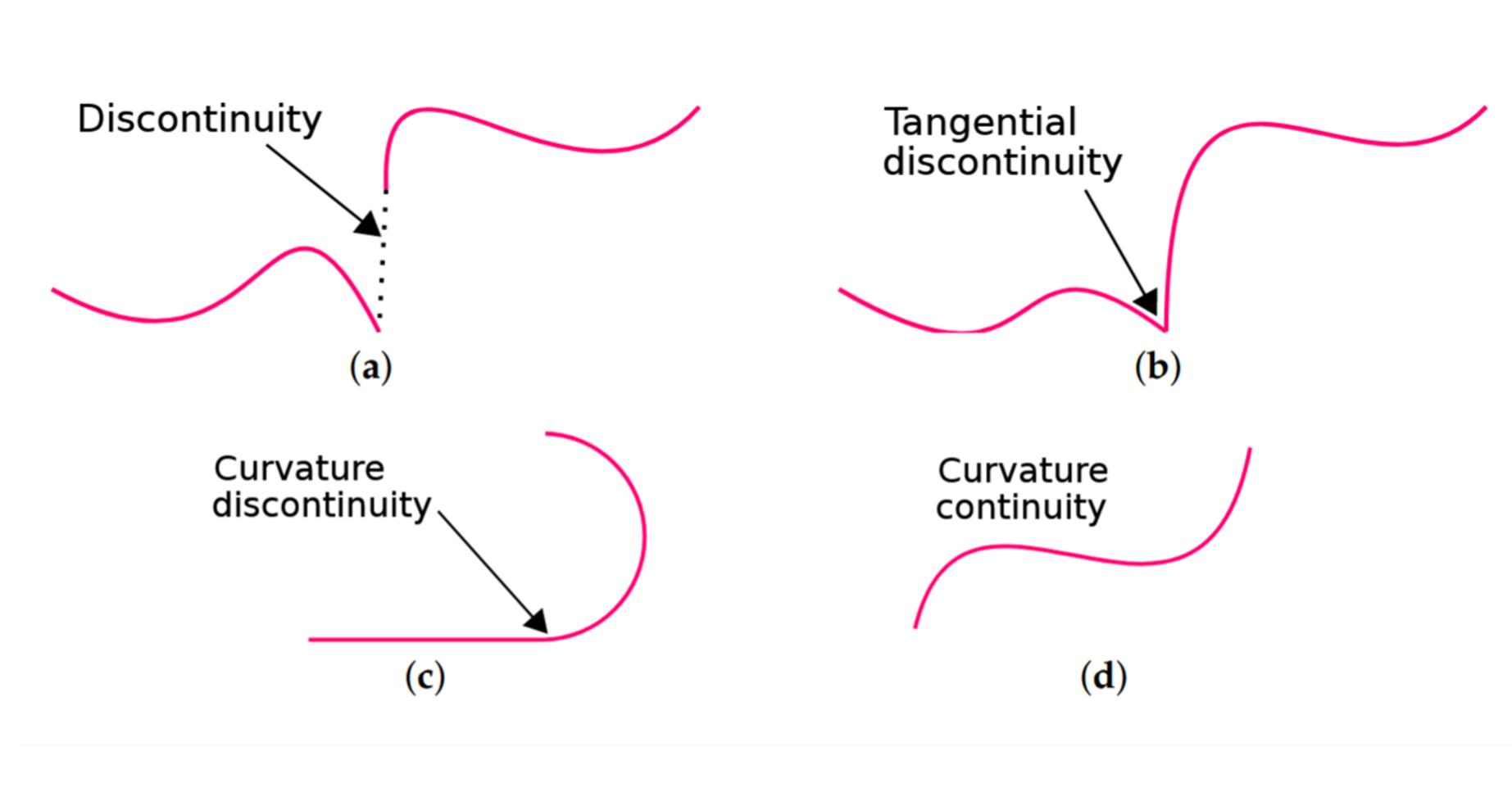
- 现有crowd navigation方法在评估指标优先级分析不足,导致对不同目标算法的评估不公平,且忽略了轨迹平滑度等重要指标。
- 论文提出统一框架,通过分析优化目标优先级和联合评估,实现导航方法公平评估,并设计奖励函数优化轨迹曲率。
- 实验结果表明,该方法在多尺度场景下显著提升了轨迹质量和适应性,性能优于现有方法。
📝 摘要(中文)
近年来,crowd navigation,特别是深度强化学习(DRL)技术在该领域的应用,受到了广泛的研究关注。然而,许多研究没有充分分析评估指标之间的相对优先级,这损害了对具有不同目标的算法的公平评估。此外,轨迹连续性指标,特别是那些要求$C^2$平滑度的指标,很少被纳入考虑。目前的DRL方法通常优先考虑效率和近端舒适度,常常忽略轨迹优化,或者仅通过简单、未经充分验证的平滑度奖励来解决。然而,有效的轨迹优化对于确保自然性、提高舒适度和最大化任何导航系统的能源效率至关重要。为了解决这些差距,本文提出了一个统一的框架,通过检查多个优化目标的优先级和联合评估,来实现对导航方法进行公平和透明的评估。我们进一步提出了一种新的奖励塑造策略,该策略明确强调轨迹曲率优化。由此产生的轨迹质量和适应性在多尺度场景中得到了显著提高。通过广泛的2D和3D实验,我们证明了所提出的方法与最先进的方法相比,实现了卓越的性能。
🔬 方法详解
问题定义:现有crowd navigation方法在评估时,缺乏对不同评估指标(如效率、舒适度、轨迹平滑度)之间相对优先级的充分分析,导致对不同目标的算法评估不公平。此外,现有方法通常忽略轨迹优化,或仅采用简单的平滑度奖励,无法保证轨迹的自然性、舒适性和能源效率。
核心思路:论文的核心思路是构建一个统一的评估框架,能够公平地评估不同crowd navigation算法的性能。同时,通过显式地优化轨迹曲率,提高轨迹的质量和适应性。这样设计的目的是为了解决现有方法在评估和轨迹优化方面的不足。
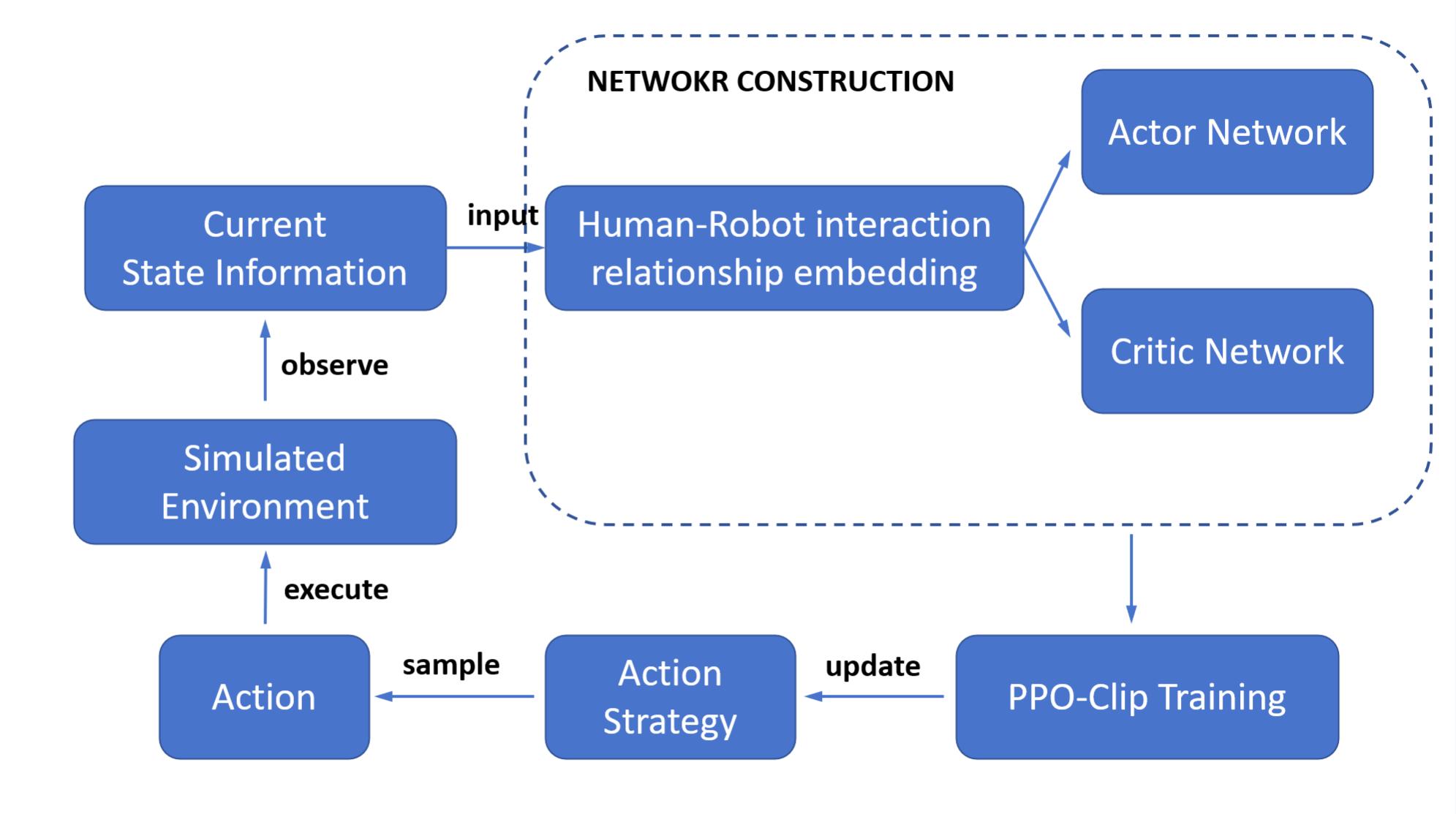
技术框架:论文提出的框架包含以下几个主要部分:1) 定义了一组全面的评估指标,包括效率、舒适度、轨迹平滑度等;2) 提出了一个统一的评估方法,能够根据不同指标的优先级进行加权评估;3) 设计了一种新的奖励塑造策略,用于优化轨迹曲率。整体流程是,首先使用该框架对现有算法进行评估,然后利用提出的奖励塑造策略训练新的crowd navigation模型。
关键创新:论文最重要的技术创新点在于提出了显式地优化轨迹曲率的奖励塑造策略。与现有方法仅采用简单的平滑度奖励不同,该策略能够更有效地优化轨迹的形状,从而提高轨迹的自然性、舒适性和能源效率。
关键设计:论文的关键设计包括:1) 评估指标的选取和加权方式,需要根据具体应用场景进行调整;2) 奖励塑造策略的具体形式,例如可以使用轨迹曲率的平方作为奖励函数的负项;3) 深度强化学习模型的网络结构和训练参数,需要根据具体问题进行优化。
🖼️ 关键图片
📊 实验亮点
论文通过2D和3D实验验证了所提出方法的有效性。实验结果表明,该方法在轨迹质量和适应性方面均优于现有方法。具体性能数据未知,但论文强调了在多尺度场景下的显著提升。
🎯 应用场景
该研究成果可应用于机器人导航、自动驾驶、虚拟现实等领域,提升智能体在复杂人群环境中的导航能力。通过优化轨迹,可以提高用户体验、降低能耗,并增强系统的安全性。未来,该方法有望应用于更广泛的场景,例如无人机配送、智能仓储等。
📄 摘要(原文)
Crowd navigation has garnered considerable research interest in recent years, especially with the proliferating application of deep reinforcement learning (DRL) techniques. Many studies, however, do not sufficiently analyze the relative priorities among evaluation metrics, which compromises the fair assessment of methods with divergent objectives. Furthermore, trajectory-continuity metrics, specifically those requiring $C^2$ smoothness, are rarely incorporated. Current DRL approaches generally prioritize efficiency and proximal comfort, often neglecting trajectory optimization or addressing it only through simplistic, unvalidated smoothness reward. Nevertheless, effective trajectory optimization is essential to ensure naturalness, enhance comfort, and maximize the energy efficiency of any navigation system. To address these gaps, this paper proposes a unified framework that enables the fair and transparent assessment of navigation methods by examining the prioritization and joint evaluation of multiple optimization objectives. We further propose a novel reward-shaping strategy that explicitly emphasizes trajectory-curvature optimization. The resulting trajectory quality and adaptability are significantly enhanced across multi-scale scenarios. Through extensive 2D and 3D experiments, we demonstrate that the proposed method achieves superior performance compared to state-of-the-art approaches.