WAM-Diff: A Masked Diffusion VLA Framework with MoE and Online Reinforcement Learning for Autonomous Driving
作者: Mingwang Xu, Jiahao Cui, Feipeng Cai, Hanlin Shang, Zhihao Zhu, Shan Luan, Yifang Xu, Neng Zhang, Yaoyi Li, Jia Cai, Siyu Zhu
分类: cs.RO, cs.AI, cs.CV
发布日期: 2025-12-06
🔗 代码/项目: GITHUB
💡 一句话要点
提出WAM-Diff,一种基于Masked Diffusion和MoE的VLA框架,用于自动驾驶轨迹生成。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自动驾驶 掩码扩散 视觉语言动作模型 轨迹生成 在线强化学习
📋 核心要点
- 现有端到端自动驾驶系统依赖自回归模型或连续扩散策略,缺乏对离散掩码扩散在轨迹生成方面的深入研究。
- WAM-Diff采用掩码扩散迭代优化离散轨迹序列,结合MoE扩展模型容量,并利用在线强化学习优化驾驶奖励。
- 实验表明,WAM-Diff在NAVSIM-v1和NAVSIM-v2数据集上取得了显著的性能,验证了掩码扩散在自动驾驶中的有效性。
📝 摘要(中文)
本文提出了一种基于视觉-语言-动作(VLA)模型的端到端自动驾驶系统WAM-Diff,该系统集成了多模态传感器输入和语言指令,以生成规划和控制信号。与目前流行的自回归大语言模型和连续扩散策略不同,本文探索了离散掩码扩散在轨迹生成方面的潜力。WAM-Diff通过掩码扩散迭代地细化代表未来车辆轨迹的离散序列。该方法包含三个关键创新:系统性地调整掩码扩散以适应自动驾驶,支持灵活的非因果解码顺序;通过在运动预测和面向驾驶的视觉问答(VQA)上联合训练的稀疏MoE架构实现可扩展的模型容量;以及使用Group Sequence Policy Optimization (GSPO)进行在线强化学习,以优化序列级别的驾驶奖励。实验结果表明,该模型在NAVSIM-v1上实现了91.0 PDMS,在NAVSIM-v2上实现了89.7 EPDMS,证明了掩码扩散在自动驾驶中的有效性。该方法为轨迹生成提供了自回归和基于扩散策略之外的一种有前景的替代方案,支持场景感知的解码策略。
🔬 方法详解
问题定义:现有端到端自动驾驶系统主要依赖于自回归模型或连续扩散模型生成轨迹。自回归模型通常存在误差累积问题,而连续扩散模型在离散动作空间的建模上存在局限性。因此,如何有效地利用离散扩散模型进行轨迹生成,并克服现有方法的不足,是本文要解决的核心问题。
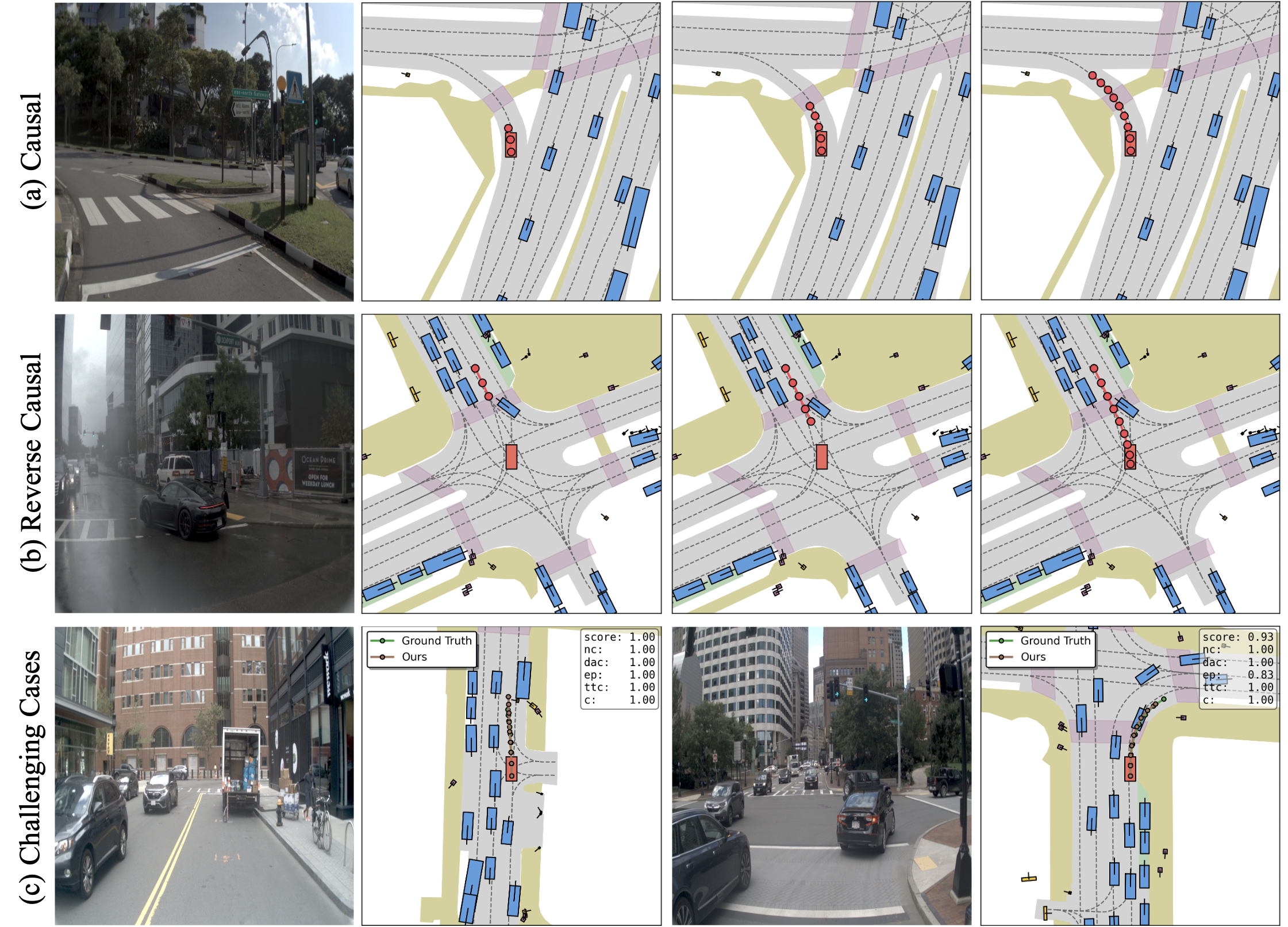
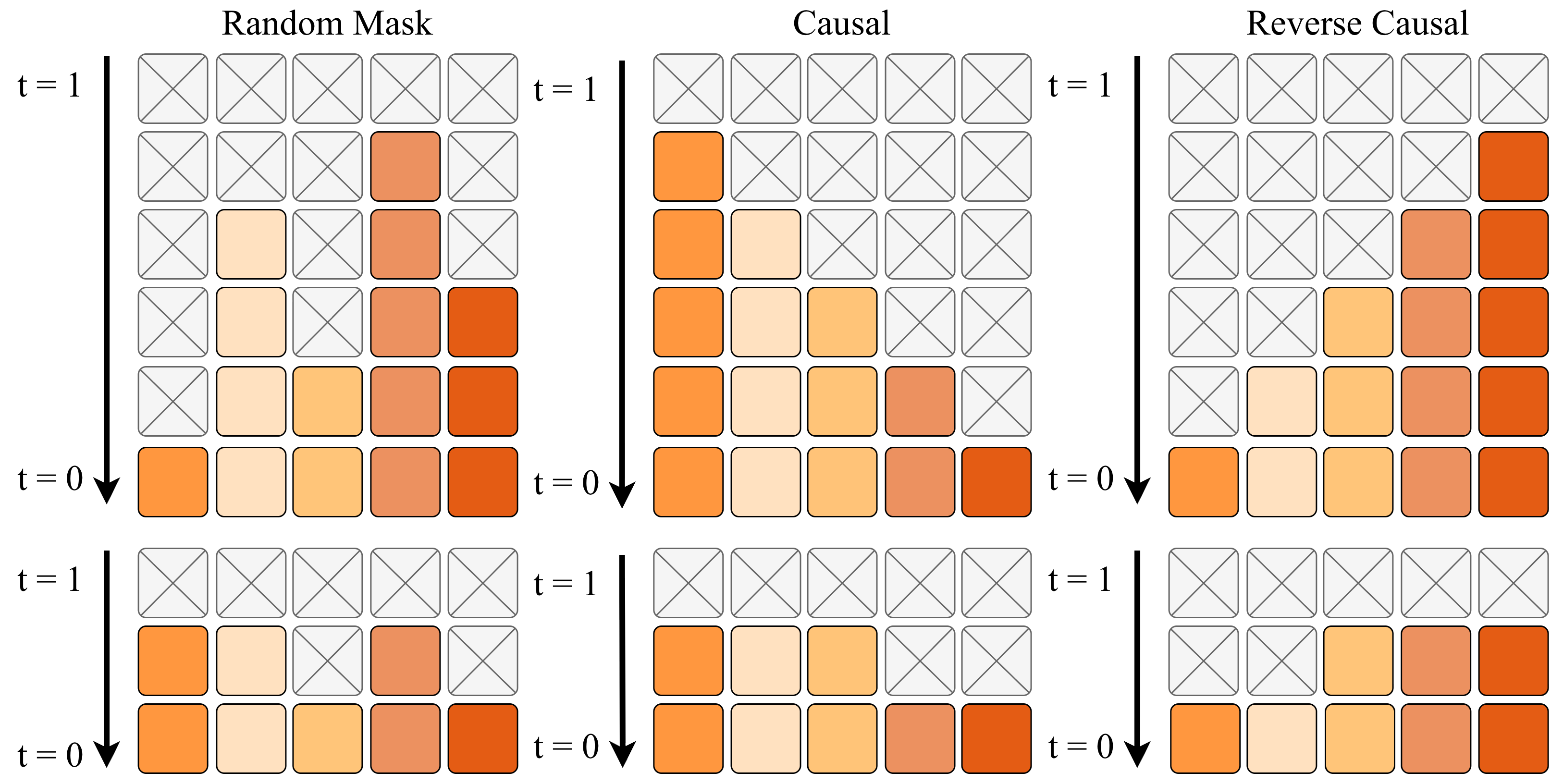
核心思路:本文的核心思路是利用掩码扩散模型迭代地细化离散轨迹序列。通过随机掩盖轨迹序列中的部分元素,并利用模型预测被掩盖的部分,从而实现对整个轨迹的优化。这种非自回归的方式可以避免误差累积,并且能够灵活地控制解码顺序,从而更好地适应不同的驾驶场景。
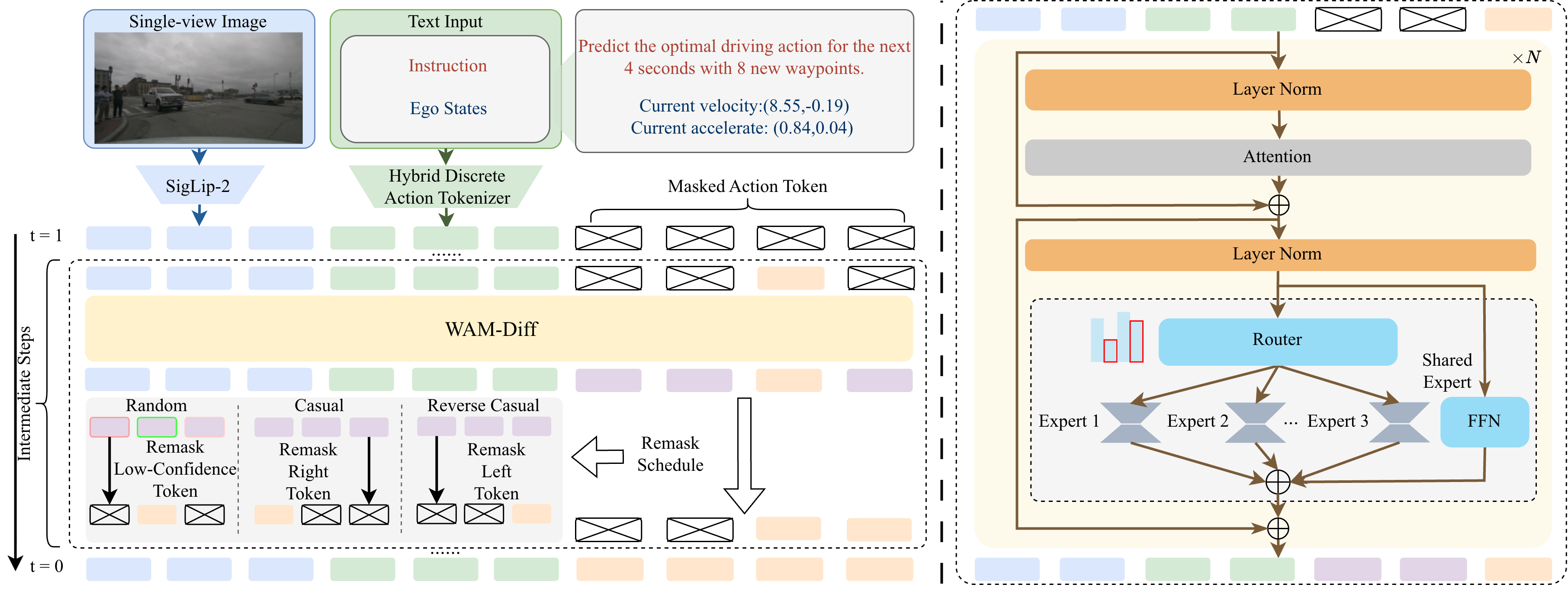
技术框架:WAM-Diff框架主要包含三个模块:视觉-语言编码器、掩码扩散模型和在线强化学习模块。首先,视觉-语言编码器将多模态输入(如图像和语言指令)编码成统一的特征表示。然后,掩码扩散模型基于该特征表示,迭代地细化离散轨迹序列。最后,在线强化学习模块利用GSPO算法,根据环境反馈优化策略,提高驾驶性能。
关键创新:本文的关键创新在于将掩码扩散模型应用于自动驾驶轨迹生成,并结合MoE和在线强化学习进行优化。具体来说,本文提出了一种系统性的掩码扩散适应方法,支持灵活的非因果解码顺序。此外,本文还利用MoE架构扩展模型容量,并使用GSPO算法进行在线强化学习,从而进一步提高驾驶性能。
关键设计:在掩码扩散模型中,本文采用了Transformer架构,并使用交叉注意力机制融合视觉-语言特征。在MoE架构中,本文采用了稀疏门控机制,以减少计算量。在在线强化学习中,本文使用了GSPO算法,该算法可以有效地优化序列级别的驾驶奖励。具体的损失函数包括运动预测损失、视觉问答损失和强化学习奖励。
🖼️ 关键图片
📊 实验亮点
WAM-Diff在NAVSIM-v1数据集上实现了91.0 PDMS,在NAVSIM-v2数据集上实现了89.7 EPDMS。这些结果表明,WAM-Diff在自动驾驶任务上取得了显著的性能,并且优于现有的自回归和基于扩散的策略。该方法为轨迹生成提供了一种有前景的替代方案。
🎯 应用场景
该研究成果可应用于各种自动驾驶场景,例如城市道路、高速公路和越野环境。通过结合视觉、语言和动作信息,WAM-Diff能够生成更加安全、高效和符合人类驾驶习惯的轨迹。此外,该方法还可以扩展到其他机器人领域,例如无人机和移动机器人。
📄 摘要(原文)
End-to-end autonomous driving systems based on vision-language-action (VLA) models integrate multimodal sensor inputs and language instructions to generate planning and control signals. While autoregressive large language models and continuous diffusion policies are prevalent, the potential of discrete masked diffusion for trajectory generation remains largely unexplored. This paper presents WAM-Diff, a VLA framework that employs masked diffusion to iteratively refine a discrete sequence representing future ego-trajectories. Our approach features three key innovations: a systematic adaptation of masked diffusion for autonomous driving that supports flexible, non-causal decoding orders; scalable model capacity via a sparse MoE architecture trained jointly on motion prediction and driving-oriented visual question answering (VQA); and online reinforcement learning using Group Sequence Policy Optimization (GSPO) to optimize sequence-level driving rewards. Remarkably, our model achieves 91.0 PDMS on NAVSIM-v1 and 89.7 EPDMS on NAVSIM-v2, demonstrating the effectiveness of masked diffusion for autonomous driving. The approach provides a promising alternative to autoregressive and diffusion-based policies, supporting scenario-aware decoding strategies for trajectory generation. The code for this paper will be released publicly at: https://github.com/fudan-generative-vision/WAM-Diff