Learning Agile Striker Skills for Humanoid Soccer Robots from Noisy Sensory Input
作者: Zifan Xu, Myoungkyu Seo, Dongmyeong Lee, Hao Fu, Jiaheng Hu, Jiaxun Cui, Yuqian Jiang, Zhihan Wang, Anastasiia Brund, Joydeep Biswas, Peter Stone
分类: cs.RO
发布日期: 2025-12-06 (更新: 2025-12-10)
💡 一句话要点
提出基于强化学习的人形机器人敏捷踢球技能学习系统,提升噪声环境下的鲁棒性。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 人形机器人 强化学习 师生学习 策略蒸馏 噪声建模 鲁棒控制 足球机器人
📋 核心要点
- 人形机器人踢球需要快速的腿部摆动和单脚站立的姿态稳定,同时还要应对噪声感知和外部扰动,这使得快速鲁棒踢球技能的学习极具挑战。
- 论文提出一种基于强化学习的师生训练框架,通过定制奖励函数、噪声建模和在线约束RL等关键设计,提升了机器人踢球的鲁棒性和适应性。
- 实验结果表明,该系统在模拟和真实机器人上均表现出良好的踢球精度和进球成功率,验证了所提出方法的有效性。
📝 摘要(中文)
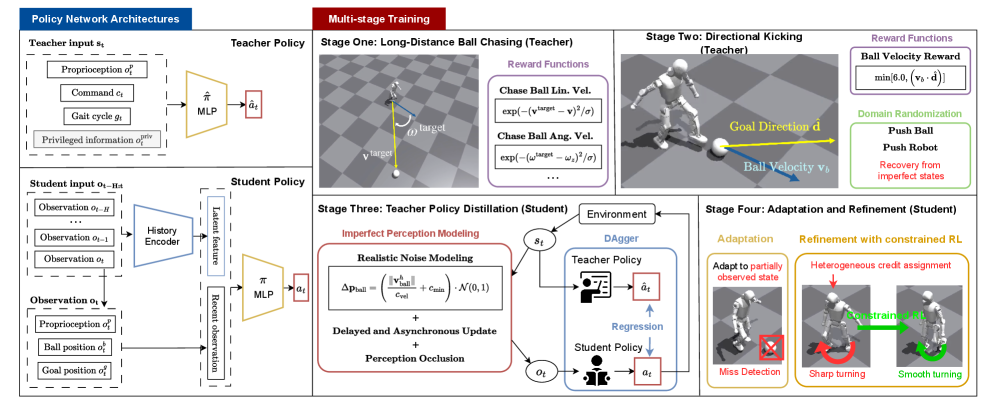
本文提出了一种基于强化学习(RL)的系统,使人形机器人能够在不同的球-门配置下执行鲁棒的连续踢球动作。该系统扩展了一个典型的师生训练框架,其中“教师”策略使用真实状态信息进行训练,“学生”学习在噪声和不完善的感知下模仿它。该框架包括四个训练阶段:(1)长距离追球(教师);(2)定向踢球(教师);(3)教师策略蒸馏(学生);(4)学生适应和改进(学生)。关键的设计要素,包括定制的奖励函数、真实的噪声建模以及用于适应和改进的在线约束RL,对于弥合模拟到真实的差距以及在感知不确定性下维持性能至关重要。在模拟和真实机器人上的大量评估表明,在不同的球-门配置下,踢球精度和进球成功率都很高。消融研究进一步强调了约束RL、噪声建模和适应阶段的必要性。这项工作提出了一个在不完善感知下学习鲁棒的连续人形机器人踢球的系统,为人形全身控制中的视觉运动技能学习建立了一个基准任务。
🔬 方法详解
问题定义:论文旨在解决人形机器人在噪声感知条件下,如何学习鲁棒且敏捷的踢球技能的问题。现有方法难以在真实环境中实现稳定和精确的踢球,主要痛点在于模拟环境与真实环境的差距,以及感知噪声带来的不确定性。
核心思路:论文采用师生学习框架,教师策略在理想状态下学习,学生策略则在模拟真实环境的噪声条件下学习模仿教师策略。通过策略蒸馏和在线适应,学生策略能够克服感知噪声,实现鲁棒的踢球动作。
技术框架:该系统包含四个主要阶段:(1)教师策略的长距离追球训练;(2)教师策略的定向踢球训练;(3)学生策略通过策略蒸馏模仿教师策略;(4)学生策略通过在线约束强化学习进行适应和改进。整体流程是从简单到复杂,逐步提升机器人的踢球能力。
关键创新:该方法的关键创新在于结合了师生学习框架和在线约束强化学习,并针对人形机器人踢球任务进行了定制化设计。通过噪声建模,使学生策略能够更好地适应真实环境中的感知不确定性。在线约束强化学习则保证了在适应过程中,策略不会偏离安全区域。
关键设计:奖励函数的设计考虑了踢球的准确性和效率,同时加入了对姿态稳定性的惩罚项。噪声建模模拟了真实环境中传感器可能出现的误差。在线约束强化学习采用Trust Region Policy Optimization (TRPO)算法,并设置了约束条件,防止策略发生剧烈变化。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该系统在模拟和真实机器人上均取得了显著的成果。在真实机器人实验中,该系统能够成功地在不同的球-门配置下完成踢球任务,并且表现出良好的鲁棒性。消融实验证明了约束RL、噪声建模和适应阶段对于提升系统性能的必要性。
🎯 应用场景
该研究成果可应用于人形机器人足球比赛,提高机器人的运动能力和竞技水平。此外,该方法也可推广到其他需要鲁棒运动控制的机器人应用场景,例如复杂地形下的机器人导航、操作等,具有重要的实际应用价值和潜力。
📄 摘要(原文)
Learning fast and robust ball-kicking skills is a critical capability for humanoid soccer robots, yet it remains a challenging problem due to the need for rapid leg swings, postural stability on a single support foot, and robustness under noisy sensory input and external perturbations (e.g., opponents). This paper presents a reinforcement learning (RL)-based system that enables humanoid robots to execute robust continual ball-kicking with adaptability to different ball-goal configurations. The system extends a typical teacher-student training framework -- in which a "teacher" policy is trained with ground truth state information and the "student" learns to mimic it with noisy, imperfect sensing -- by including four training stages: (1) long-distance ball chasing (teacher); (2) directional kicking (teacher); (3) teacher policy distillation (student); and (4) student adaptation and refinement (student). Key design elements -- including tailored reward functions, realistic noise modeling, and online constrained RL for adaptation and refinement -- are critical for closing the sim-to-real gap and sustaining performance under perceptual uncertainty. Extensive evaluations in both simulation and on a real robot demonstrate strong kicking accuracy and goal-scoring success across diverse ball-goal configurations. Ablation studies further highlight the necessity of the constrained RL, noise modeling, and the adaptation stage. This work presents a system for learning robust continual humanoid ball-kicking under imperfect perception, establishing a benchmark task for visuomotor skill learning in humanoid whole-body control.