Embodied Referring Expression Comprehension in Human-Robot Interaction
作者: Md Mofijul Islam, Alexi Gladstone, Sujan Sarker, Ganesh Nanduru, Md Fahim, Keyan Du, Aman Chadha, Tariq Iqbal
分类: cs.RO
发布日期: 2025-12-06
备注: 14 pages, 7 figures, accepted at the ACM/IEEE International Conference on Human-Robot Interaction (HRI) 2026
💡 一句话要点
提出Refer360数据集和MuRes模块,提升人机交互中具身指代表达理解能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 人机交互 具身指代表达 多模态融合 数据集构建 残差学习
📋 核心要点
- 现有具身指代表达理解数据集缺乏大规模、多视角、非语言信息和户外场景覆盖。
- 提出Refer360数据集,并设计多模态引导残差模块MuRes,提取模态特定信息增强模型。
- 实验表明,现有模型难以充分理解具身交互,而MuRes能有效提升模型性能,Refer360成为有价值的基准。
📝 摘要(中文)
为了使机器人能够理解具身人类指令,实现直观流畅的人机交互(HRI),本文提出了Refer360数据集,这是一个大规模的具身语言和非语言交互数据集,涵盖室内和室外环境中的不同视角。此外,本文还引入了多模态引导残差模块MuRes,旨在提升具身指代表达理解能力。MuRes作为一个信息瓶颈,提取显著的模态特定信号,并将其增强到预训练表示中,形成下游任务的互补特征。在包括Refer360数据集在内的四个人机交互数据集上进行了大量实验,结果表明,当前的多模态模型未能全面捕捉具身交互;然而,通过MuRes增强这些模型可以持续提高性能。这些发现确立了Refer360作为一个有价值的基准,并展示了引导残差学习在提升人机环境中机器人具身指代表达理解方面的潜力。
🔬 方法详解
问题定义:论文旨在解决人机交互中机器人理解具身指代表达的问题。现有数据集存在视角偏差、单视角采集、非语言手势覆盖不足以及主要关注室内环境等局限性,导致模型难以泛化到真实世界的人机交互场景中。
核心思路:论文的核心思路是构建一个更全面、更真实的数据集Refer360,并设计一个多模态引导残差模块MuRes,以更好地利用不同模态的信息,提升模型对具身指代表达的理解能力。通过数据集的丰富性和模块的针对性设计,弥补现有方法的不足。
技术框架:整体框架包含两个主要部分:Refer360数据集的构建和MuRes模块的设计。Refer360数据集包含多视角、室内外场景以及丰富的非语言信息。MuRes模块则作为一个信息瓶颈,首先提取各个模态的显著特征,然后将这些特征融入到预训练的表示中,从而形成互补的特征表示。最终,这些特征被用于下游的具身指代表达理解任务。
关键创新:论文的关键创新在于Refer360数据集的规模和多样性,以及MuRes模块的设计。Refer360数据集提供了更接近真实人机交互场景的数据,而MuRes模块则通过引导残差学习的方式,更好地利用了不同模态的信息,避免了简单融合可能导致的信息冗余和噪声。与现有方法相比,MuRes更注重提取和增强模态特定的显著特征。
关键设计:MuRes模块的关键设计在于其残差连接和引导机制。残差连接允许信息直接从输入传递到输出,避免了梯度消失问题。引导机制则通过注意力机制或其他方式,选择性地提取和增强各个模态的显著特征。具体的参数设置、损失函数和网络结构等细节在论文中应该有更详细的描述(未知)。
🖼️ 关键图片


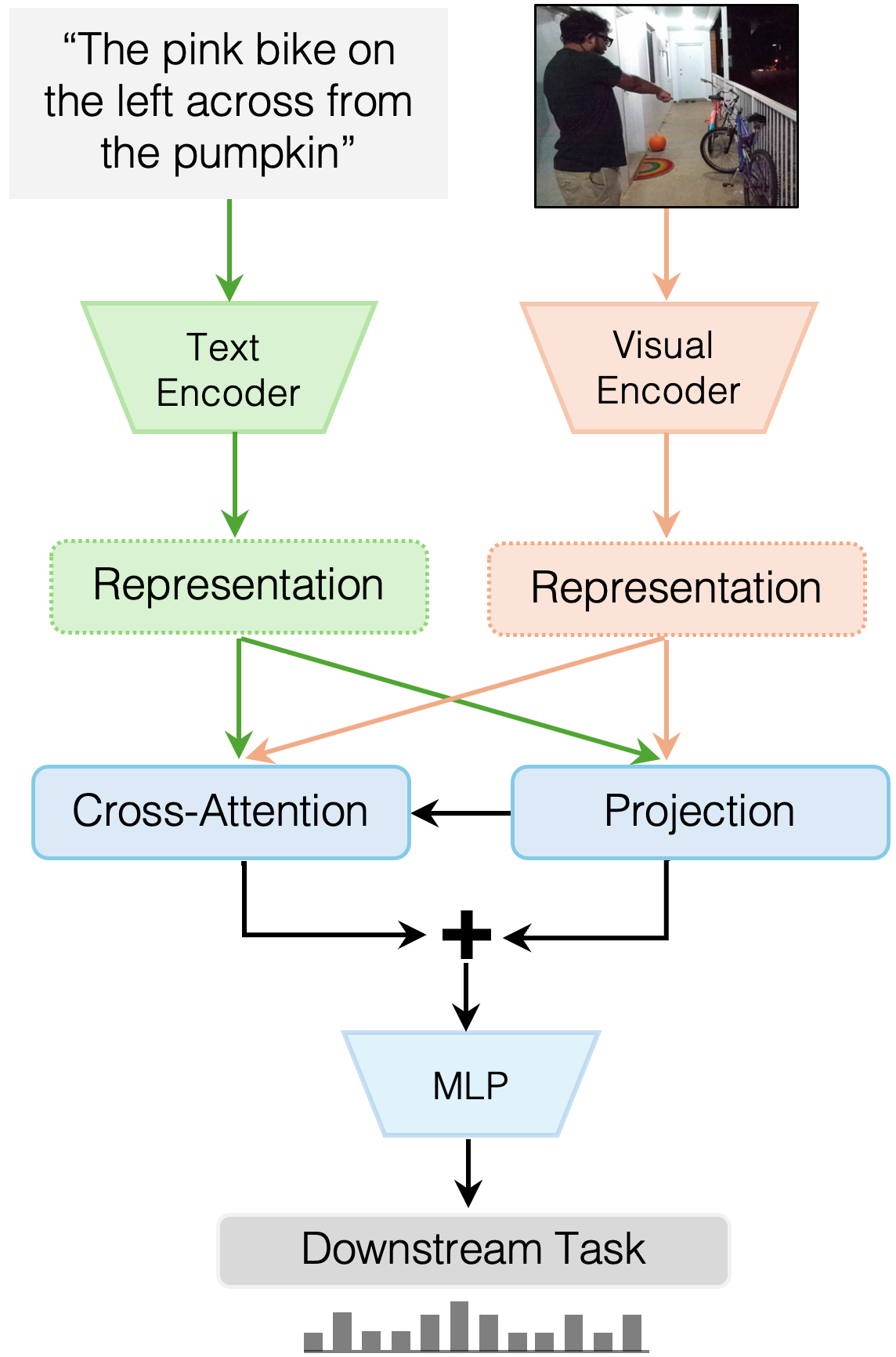
📊 实验亮点
实验结果表明,在包括Refer360在内的四个人机交互数据集上,将MuRes模块添加到现有的多模态模型中,可以持续提高性能。具体提升幅度未知,但论文强调MuRes能够有效改善现有模型在具身指代表达理解方面的不足。Refer360数据集的发布也为该领域的研究提供了一个新的基准。
🎯 应用场景
该研究成果可应用于各种人机交互场景,例如家庭服务机器人、工业协作机器人、医疗辅助机器人等。通过提升机器人对人类指令的理解能力,可以实现更自然、更高效的人机协作,提高工作效率和生活质量。未来,该研究还可以扩展到更复杂的交互场景,例如多机器人协作、人机混合团队等。
📄 摘要(原文)
As robots enter human workspaces, there is a crucial need for them to comprehend embodied human instructions, enabling intuitive and fluent human-robot interaction (HRI). However, accurate comprehension is challenging due to a lack of large-scale datasets that capture natural embodied interactions in diverse HRI settings. Existing datasets suffer from perspective bias, single-view collection, inadequate coverage of nonverbal gestures, and a predominant focus on indoor environments. To address these issues, we present the Refer360 dataset, a large-scale dataset of embodied verbal and nonverbal interactions collected across diverse viewpoints in both indoor and outdoor settings. Additionally, we introduce MuRes, a multimodal guided residual module designed to improve embodied referring expression comprehension. MuRes acts as an information bottleneck, extracting salient modality-specific signals and reinforcing them into pre-trained representations to form complementary features for downstream tasks. We conduct extensive experiments on four HRI datasets, including the Refer360 dataset, and demonstrate that current multimodal models fail to capture embodied interactions comprehensively; however, augmenting them with MuRes consistently improves performance. These findings establish Refer360 as a valuable benchmark and exhibit the potential of guided residual learning to advance embodied referring expression comprehension in robots operating within human environments.