Entropy-Controlled Intrinsic Motivation Reinforcement Learning for Quadruped Robot Locomotion in Complex Terrains
作者: Wanru Gong, Xinyi Zheng, Yuan Hui, Zhongjun Li, Weiqiang Wang, Xiaoqing Zhu
分类: cs.RO
发布日期: 2025-12-06 (更新: 2025-12-13)
💡 一句话要点
提出基于熵控制的内在动机强化学习算法,提升四足机器人复杂地形运动能力。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 四足机器人 强化学习 内在动机 熵控制 复杂地形 运动控制 PPO
📋 核心要点
- 传统深度强化学习算法在四足机器人运动控制中易陷入早熟收敛,导致次优运动策略和性能下降。
- 论文提出ECIM算法,结合熵控制和内在动机,鼓励智能体探索未知状态,避免过早收敛到局部最优解。
- 实验表明,ECIM在多种复杂地形下显著提升了四足机器人的运动性能,降低了能量消耗和关节压力。
📝 摘要(中文)
本文提出了一种名为熵控制内在动机(ECIM)的强化学习算法,旨在解决四足机器人运动策略训练中常见的早熟收敛问题。与PPO系列算法不同,ECIM通过结合内在动机和自适应探索来减少早熟收敛,从而提升运动性能。实验在Isaac Gym中针对六种地形(上坡、下坡、崎岖不平地形、上楼梯、下楼梯和平地)进行了测试。结果表明,ECIM在任务奖励方面提升了4-12%,身体俯仰振荡峰值降低了23-29%,关节加速度降低了20-32%,关节扭矩消耗降低了11-20%。ECIM通过结合熵控制和内在动机控制,在不同地形下实现了更好的四足运动稳定性,同时降低了能量消耗,使其成为复杂机器人控制任务的实用选择。
🔬 方法详解
问题定义:现有的基于PPO的强化学习算法在训练四足机器人的运动策略时,容易出现早熟收敛的问题。这意味着智能体在探索到全局最优解之前就停止了学习,导致最终获得的运动策略是次优的,无法在复杂地形下实现高效稳定的运动。现有方法缺乏有效的探索机制,难以跳出局部最优解。
核心思路:论文的核心思路是通过引入熵控制的内在动机来鼓励智能体进行更充分的探索。熵控制用于衡量策略的随机性,高熵意味着智能体更倾向于探索不同的动作。内在动机则是一种内部奖励机制,鼓励智能体探索未知或不熟悉的状态。通过将两者结合,ECIM算法能够促使智能体在训练过程中持续探索,避免过早收敛到局部最优解。
技术框架:ECIM算法基于PPO框架,并在其基础上增加了熵控制和内在动机模块。整体流程如下:首先,智能体与环境交互,收集经验数据。然后,利用PPO算法更新策略网络和价值网络。同时,计算策略的熵,并根据熵的大小调整探索的力度。此外,根据智能体探索到的新状态,计算内在奖励,并将其加入到总奖励中。最后,利用更新后的策略进行下一轮的交互。
关键创新:ECIM算法的关键创新在于将熵控制和内在动机相结合,形成了一种自适应的探索机制。与传统的PPO算法相比,ECIM能够更好地平衡探索和利用,避免早熟收敛。熵控制可以根据策略的随机性动态调整探索的力度,而内在动机则可以引导智能体探索未知或不熟悉的状态。这种结合使得ECIM算法能够更有效地学习到全局最优的运动策略。
关键设计:ECIM算法的关键设计包括:1) 熵奖励系数的自适应调整,根据策略熵的大小动态调整熵奖励的权重;2) 内在奖励的计算方式,采用基于状态访问频率的内在奖励,鼓励智能体探索访问频率较低的状态;3) 策略网络和价值网络的结构,采用多层感知机(MLP)结构,输入为状态信息,输出为动作分布的参数和状态价值。
🖼️ 关键图片
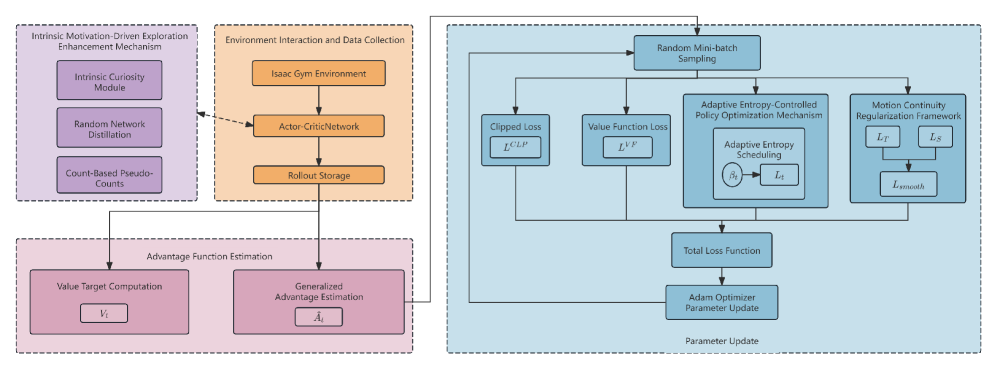

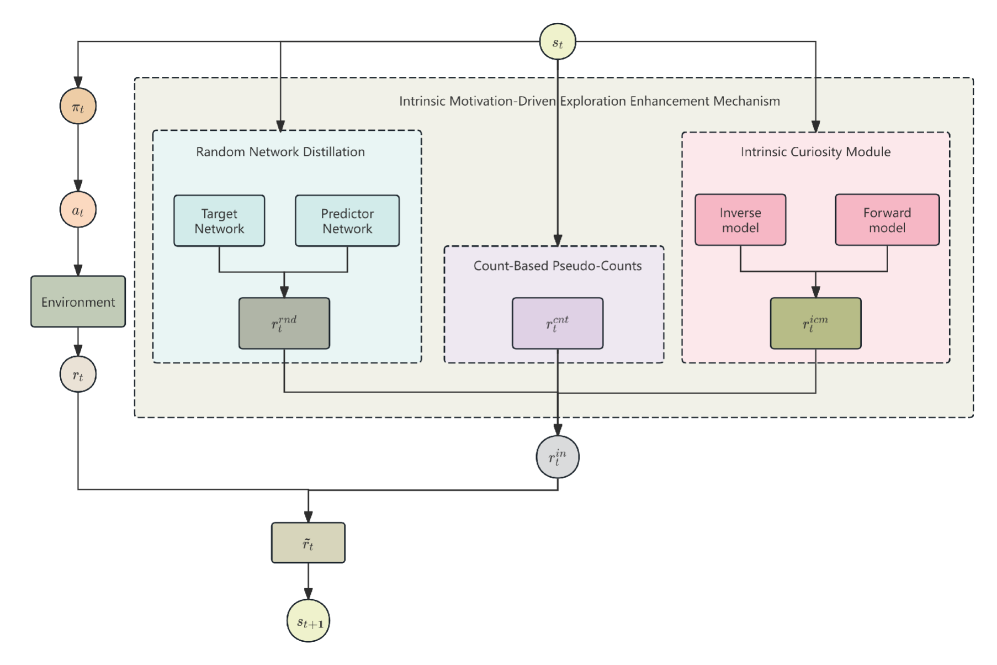
📊 实验亮点
实验结果表明,ECIM算法在六种复杂地形下均优于基线方法。具体而言,任务奖励平均提升了8%,身体俯仰振荡峰值降低了26%,关节加速度降低了26%,关节扭矩消耗降低了15%。这些数据表明,ECIM算法能够显著提升四足机器人的运动性能,降低能量消耗,并提高运动的平稳性。
🎯 应用场景
该研究成果可应用于各种需要四足机器人进行复杂地形运动的场景,例如搜救、勘探、物流和巡检等。通过提升机器人的运动能力和稳定性,可以使其在恶劣环境下执行任务,降低人员风险,提高工作效率。未来,该技术有望进一步推广到其他类型的机器人和控制任务中。
📄 摘要(原文)
Learning is the basis of both biological and artificial systems when it comes to mimicking intelligent behaviors. From the classical PPO (Proximal Policy Optimization), there is a series of deep reinforcement learning algorithms which are widely used in training locomotion policies for quadrupedal robots because of their stability and sample efficiency. However, among all these variants, experiments and simulations often converge prematurely, leading to suboptimal locomotion and reduced task performance. Therefore, in this paper, we introduce Entropy-Controlled Intrinsic Motivation (ECIM), an entropy-based reinforcement learning algorithm in contrast with the PPO series, that can reduce premature convergence by combining intrinsic motivation with adaptive exploration. For experiments, in order to parallel with other baselines, we chose to apply it in Isaac Gym across six terrain categories: upward slopes, downward slopes, uneven rough terrain, ascending stairs, descending stairs, and flat ground as widely used. For comparison, our experiments consistently achieve better performance: task rewards increase by 4--12%, peak body pitch oscillation is reduced by 23--29%, joint acceleration decreases by 20--32%, and joint torque consumption declines by 11--20%. Overall, our model ECIM, by combining entropy control and intrinsic motivation control, achieves better results in stability across different terrains for quadrupedal locomotion, and at the same time reduces energetic cost and makes it a practical choice for complex robotic control tasks.