Training-Time Action Conditioning for Efficient Real-Time Chunking
作者: Kevin Black, Allen Z. Ren, Michael Equi, Sergey Levine
分类: cs.RO, cs.AI
发布日期: 2025-12-05 (更新: 2025-12-09)
💡 一句话要点
提出训练时动作条件反射,高效实现视觉-语言-动作模型的实时分块控制
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 实时控制 机器人学习 视觉-语言-动作模型 动作条件反射 推理加速
📋 核心要点
- 现有实时分块方法依赖推理时补全,引入额外计算开销,增加推理延迟,限制了机器人控制的实时性。
- 该论文提出在训练时模拟推理延迟,直接对动作前缀进行条件反射,避免推理时补全,降低计算复杂度。
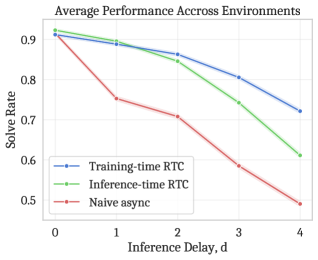
- 实验表明,训练时动作条件反射在模拟和真实机器人任务中,性能与推理时补全相当,但计算成本更低。
📝 摘要(中文)
实时分块(RTC)通过异步预测动作块,并利用推理时补全技术对先前执行的动作进行条件反射,使视觉-语言-动作模型(VLA)能够生成平滑、反应灵敏的机器人轨迹。然而,这种补全方法引入了计算开销,增加了推理延迟。本文提出了一种简单的替代方案:在训练时模拟推理延迟,并直接对动作前缀进行条件反射,从而消除任何推理时的开销。我们的方法不需要修改模型架构或机器人运行时,只需几行额外的代码即可实现。在模拟实验中,我们发现训练时RTC在更高的推理延迟下优于推理时RTC。在真实世界的箱子组装和咖啡制作任务中,我们使用$π_{0.6}$ VLA证明了训练时RTC保持了与推理时RTC相当的任务性能和速度,同时计算成本更低。我们的结果表明,训练时动作条件反射是实时机器人控制中推理时补全的一种实用的直接替代方案。
🔬 方法详解
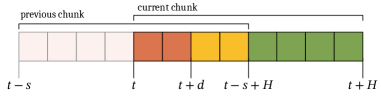
问题定义:实时分块(RTC)旨在使机器人能够根据视觉和语言指令,实时生成平滑且响应迅速的动作序列。现有的基于推理时补全的RTC方法,虽然能够处理动作延迟,但引入了额外的计算负担,导致推理速度下降,这对于需要快速响应的实时控制系统来说是一个显著的痛点。
核心思路:该论文的核心思路是在训练阶段模拟推理延迟,让模型学习在给定部分已执行动作序列的情况下,预测后续动作。通过这种方式,模型在推理时可以直接使用训练好的策略,而无需进行耗时的补全操作。这种方法旨在通过训练时的预先适应,来消除推理时的计算瓶颈。
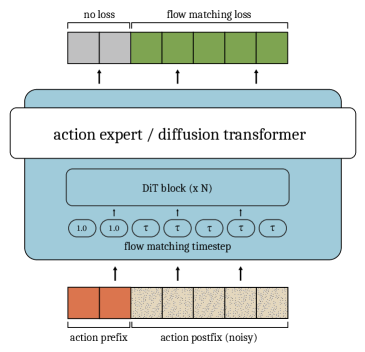
技术框架:整体框架包括一个视觉-语言-动作模型(VLA),该模型接收视觉输入(例如摄像头图像)和语言指令,并输出动作序列。在训练阶段,引入一个模拟延迟模块,该模块随机截断已执行的动作序列,并将其作为条件输入到VLA中。VLA的目标是预测完整的动作序列,从而学习在部分信息下进行动作规划。在推理阶段,直接使用训练好的VLA进行动作预测,无需额外的补全步骤。
关键创新:最重要的创新在于将推理时的计算负担转移到训练时。通过在训练过程中显式地模拟推理延迟,模型能够学习到一种更高效的动作生成策略,从而避免了推理时补全带来的性能瓶颈。这种方法无需修改模型架构,易于实现,并且可以显著提高实时控制系统的响应速度。
关键设计:关键的设计包括模拟延迟模块的实现方式,例如随机截断动作序列的长度分布。此外,损失函数的设计也至关重要,需要确保模型能够准确地预测完整的动作序列,即使在只有部分已执行动作作为条件的情况下。具体的网络结构和参数设置取决于所使用的VLA模型,但该方法可以与多种VLA模型兼容。
🖼️ 关键图片
📊 实验亮点
该论文在模拟和真实机器人实验中验证了训练时动作条件反射的有效性。在模拟实验中,该方法在更高的推理延迟下优于推理时RTC。在真实世界的箱子组装和咖啡制作任务中,使用$π_{0.6}$ VLA证明了训练时RTC保持了与推理时RTC相当的任务性能和速度,同时计算成本更低,表明其具有实际应用价值。
🎯 应用场景
该研究成果可广泛应用于需要实时响应的机器人控制任务中,例如自动化装配、服务机器人、自动驾驶等。通过降低推理延迟,可以提高机器人的反应速度和操作精度,使其能够更好地适应动态环境。此外,该方法还可以应用于其他需要实时序列预测的领域,例如语音合成、自然语言生成等。
📄 摘要(原文)
Real-time chunking (RTC) enables vision-language-action models (VLAs) to generate smooth, reactive robot trajectories by asynchronously predicting action chunks and conditioning on previously committed actions via inference-time inpainting. However, this inpainting method introduces computational overhead that increases inference latency. In this work, we propose a simple alternative: simulating inference delay at training time and conditioning on action prefixes directly, eliminating any inference-time overhead. Our method requires no modifications to the model architecture or robot runtime, and can be implemented with only a few additional lines of code. In simulated experiments, we find that training-time RTC outperforms inference-time RTC at higher inference delays. In real-world experiments on box building and espresso making tasks with the $π_{0.6}$ VLA, we demonstrate that training-time RTC maintains both task performance and speed parity with inference-time RTC while being computationally cheaper. Our results suggest that training-time action conditioning is a practical drop-in replacement for inference-time inpainting in real-time robot control.