STARE-VLA: Progressive Stage-Aware Reinforcement for Fine-Tuning Vision-Language-Action Models
作者: Feng Xu, Guangyao Zhai, Xin Kong, Tingzhong Fu, Daniel F. N. Gordon, Xueli An, Benjamin Busam
分类: cs.RO
发布日期: 2025-12-04 (更新: 2025-12-23)
💡 一句话要点
提出STARE-VLA,通过阶段感知强化学习微调视觉-语言-动作模型,提升机器人操作性能。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言-动作模型 强化学习 机器人操作 阶段感知 长时程规划
📋 核心要点
- 现有VLA模型微调方法在处理长时程动作时,信用分配粗糙,训练不稳定,难以有效学习。
- STARE-VLA将动作轨迹分解为语义阶段,提供阶段对齐的强化信号,实现更精细的优化。
- 实验表明,STARE-VLA在机器人操作任务中显著提升了成功率,达到了当前最优水平。
📝 摘要(中文)
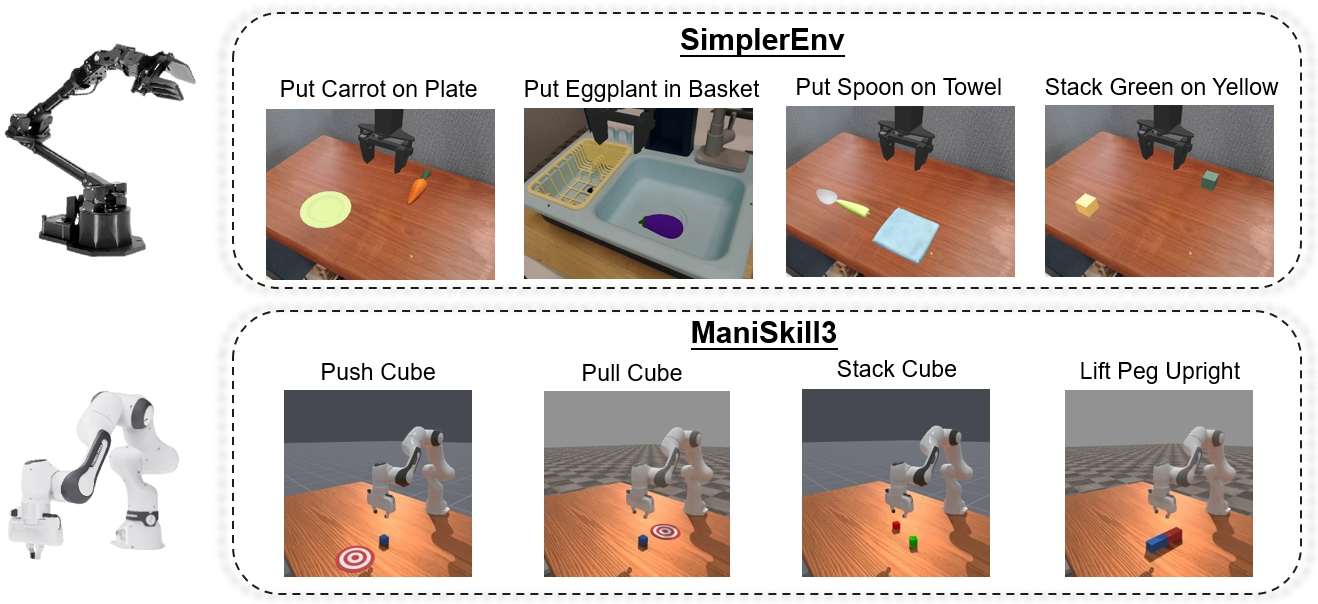
视觉-语言-动作(VLA)模型在大型语言模型和基于强化学习的微调技术的推动下,在机器人操作领域取得了显著进展。现有方法通常将长时程动作视为语言序列,并应用轨迹级优化方法,如轨迹偏好优化(TPO)或近端策略优化(PPO),导致粗糙的信用分配和不稳定的训练。与语言不同,动作轨迹通过因果链连接的不同阶段,具有不同的学习难度。因此,本文提出了阶段感知强化(STARE)模块,将长时程动作轨迹分解为语义上有意义的阶段,并提供密集、可解释且阶段对齐的强化信号。通过将STARE集成到TPO和PPO中,分别得到阶段感知TPO(STA-TPO)和阶段感知PPO(STA-PPO),用于离线阶段偏好和在线阶段内交互。此外,在监督微调的基础上,提出了模仿->偏好->交互(IPI)的串行微调流程,以提高VLA模型中的动作准确性。在SimplerEnv和ManiSkill3上的实验表明,该方法取得了显著的性能提升,在SimplerEnv上达到了98.0%的最先进成功率,在ManiSkill3任务上达到了96.4%。
🔬 方法详解
问题定义:现有VLA模型在处理长时程机器人操作任务时,通常将动作序列视为一个整体进行优化,忽略了动作序列中不同阶段的语义信息和学习难度差异。这种粗粒度的优化方式导致信用分配不准确,难以有效学习到每个阶段的关键动作,从而影响整体任务的成功率。现有方法如TPO和PPO虽然在一定程度上解决了强化学习中的探索问题,但仍然无法很好地处理长时程、多阶段的机器人操作任务。
核心思路:论文的核心思路是将长时程动作轨迹分解为多个语义上有意义的阶段,并为每个阶段提供独立的强化信号。通过阶段感知的强化学习,模型可以更准确地评估每个阶段的贡献,从而实现更精细的信用分配和更有效的学习。这种阶段分解的思想借鉴了人类学习复杂任务的过程,即将大任务分解为小任务,逐个攻破。
技术框架:STARE-VLA的技术框架主要包含三个部分:阶段分解模块、阶段感知强化模块和串行微调流程。阶段分解模块负责将长时程动作轨迹分解为多个语义阶段。阶段感知强化模块则根据每个阶段的完成情况,生成相应的强化信号,并将其集成到现有的强化学习算法中,如TPO和PPO。最后,串行微调流程IPI,首先进行模仿学习,然后进行偏好学习,最后进行交互学习,逐步提高模型的性能。
关键创新:STARE-VLA最重要的技术创新点在于提出了阶段感知的强化学习方法。与现有方法不同,STARE-VLA能够将长时程动作轨迹分解为多个语义阶段,并为每个阶段提供独立的强化信号。这种阶段分解的思想使得模型能够更准确地评估每个阶段的贡献,从而实现更精细的信用分配和更有效的学习。此外,IPI串行微调流程也为VLA模型的训练提供了一种新的思路。
关键设计:阶段分解模块的设计需要根据具体的任务进行调整,可以使用人工标注或者自动聚类等方法。阶段感知强化模块的关键在于如何设计合适的奖励函数,以准确评估每个阶段的完成情况。IPI串行微调流程中,模仿学习可以使用监督学习方法,偏好学习可以使用TPO或PPO等方法,交互学习则可以通过与环境的交互来进一步提高模型的性能。具体的参数设置和网络结构需要根据具体的任务进行调整。
🖼️ 关键图片

📊 实验亮点
实验结果表明,STARE-VLA在SimplerEnv和ManiSkill3两个机器人操作任务中均取得了显著的性能提升。在SimplerEnv上,STARE-VLA达到了98.0%的最先进成功率,相比于基线方法有显著提升。在ManiSkill3任务上,STARE-VLA也达到了96.4%的成功率,同样优于其他方法。这些结果表明,STARE-VLA能够有效地提高VLA模型在机器人操作任务中的性能。
🎯 应用场景
STARE-VLA具有广泛的应用前景,可应用于各种需要长时程规划和精细动作控制的机器人操作任务,如家庭服务机器人、工业机器人、医疗机器人等。该研究成果有助于提高机器人的自主性和智能化水平,使其能够更好地完成复杂的操作任务,从而在实际生活中发挥更大的作用。未来,该方法还可以扩展到其他领域,如游戏AI、自动驾驶等。
📄 摘要(原文)
Recent advances in Vision-Language-Action (VLA) models, powered by large language models and reinforcement learning-based fine-tuning, have shown remarkable progress in robotic manipulation. Existing methods often treat long-horizon actions as linguistic sequences and apply trajectory-level optimization methods such as Trajectory-wise Preference Optimization (TPO) or Proximal Policy Optimization (PPO), leading to coarse credit assignment and unstable training. However, unlike language, where a unified semantic meaning is preserved despite flexible sentence order, action trajectories progress through causally chained stages with different learning difficulties. This motivates progressive stage optimization. Thereby, we present Stage-Aware Reinforcement (STARE), a module that decomposes a long-horizon action trajectory into semantically meaningful stages and provides dense, interpretable, and stage-aligned reinforcement signals. Integrating STARE into TPO and PPO, we yield Stage-Aware TPO (STA-TPO) and Stage-Aware PPO (STA-PPO) for offline stage-wise preference and online intra-stage interaction, respectively. Further building on supervised fine-tuning as initialization, we propose the Imitation -> Preference -> Interaction (IPI), a serial fine-tuning pipeline for improving action accuracy in VLA models. Experiments on SimplerEnv and ManiSkill3 demonstrate substantial gains, achieving state-of-the-art success rates of 98.0 percent on SimplerEnv and 96.4 percent on ManiSkill3 tasks.