From Generated Human Videos to Physically Plausible Robot Trajectories
作者: James Ni, Zekai Wang, Wei Lin, Amir Bar, Yann LeCun, Trevor Darrell, Jitendra Malik, Roei Herzig
分类: cs.RO, cs.CV
发布日期: 2025-12-04 (更新: 2025-12-11)
备注: For project website, see https://genmimic.github.io
💡 一句话要点
GenMimic:利用生成视频实现物理可信的人形机器人轨迹控制
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱四:生成式动作 (Generative Motion) 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation)
关键词: 视频生成 机器人控制 强化学习 人形机器人 运动模仿 零样本学习 物理仿真
📋 核心要点
- 现有方法难以直接将生成视频中的人类动作迁移到机器人,因为生成视频存在噪声和形态失真。
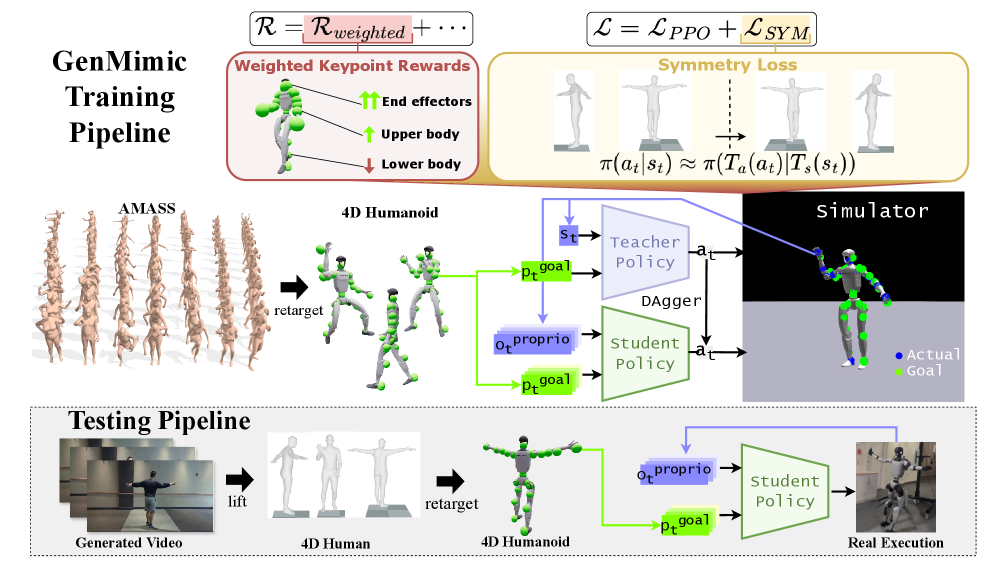
- 论文提出GenMimic,一个两阶段流程,先将视频像素转换为4D人体表示并重定向,再使用强化学习策略进行模仿。
- 实验表明,GenMimic在模拟和真实机器人上均表现出良好的性能,无需微调即可实现连贯的运动跟踪。
📝 摘要(中文)
视频生成模型在合成人类行为方面取得了显著进展,为上下文机器人控制提供了一种高层规划的潜力。为了实现这一潜力,一个关键问题是如何让人形机器人以零样本方式执行生成视频中的人类动作。由于生成视频通常包含噪声和形态失真,直接模仿具有挑战性。为此,我们提出了一个两阶段流程。首先,将视频像素转换为4D人体表示,然后重定向到人形机器人的形态。其次,我们提出了GenMimic,一个基于物理的强化学习策略,以3D关键点为条件,并通过对称正则化和关键点加权跟踪奖励进行训练。GenMimic能够模仿来自嘈杂生成视频的人类动作。我们创建了GenMimicBench,一个使用两个视频生成模型生成的合成人类运动数据集,涵盖了各种动作和上下文,为评估零样本泛化和策略鲁棒性建立了一个基准。大量实验表明,在模拟中优于强大的基线,并证实了在Unitree G1人形机器人上无需微调即可实现连贯、物理稳定的运动跟踪。这项工作为实现视频生成模型作为机器人控制高层策略的潜力提供了一条有希望的途径。
🔬 方法详解
问题定义:论文旨在解决如何利用快速发展的视频生成模型来控制人形机器人的问题。现有的挑战在于,直接模仿生成视频中的人类动作是困难的,因为这些视频通常包含噪声、形态失真,并且与真实世界的人形机器人形态存在差异。因此,需要一种方法能够将生成视频中的动作转化为机器人可以执行的物理可行的轨迹。
核心思路:论文的核心思路是将问题分解为两个阶段:首先,将生成视频中的像素信息转化为机器人可以理解的人体姿态信息;然后,利用强化学习训练一个策略,使机器人能够根据这些姿态信息模仿人类动作。这种分解使得问题更容易处理,并且允许利用强化学习来解决物理约束和机器人形态差异带来的挑战。
技术框架:整体框架包含两个主要阶段:1) 视频到4D人体表示的转换和重定向:使用现有的姿态估计模型从视频中提取3D关键点,并将其转换为4D人体表示,然后将人体表示重定向到人形机器人的形态。2) 基于物理的强化学习策略训练:使用强化学习训练一个策略,该策略以3D关键点为条件,并通过对称正则化和关键点加权跟踪奖励进行训练。该策略的目标是使机器人能够尽可能地模仿人类动作,同时保持物理稳定。
关键创新:论文的关键创新在于提出了一个完整的pipeline,能够将生成视频中的人类动作转化为机器人可以执行的物理可行的轨迹。具体来说,GenMimic结合了视频处理、姿态估计、形态重定向和强化学习等技术,克服了生成视频的噪声和形态失真带来的挑战。此外,论文还提出了GenMimicBench,一个用于评估零样本泛化和策略鲁棒性的合成数据集。
关键设计:在强化学习训练中,使用了对称正则化来鼓励机器人学习对称的动作,并使用关键点加权跟踪奖励来提高模仿的准确性。奖励函数的设计至关重要,需要平衡模仿的准确性和物理稳定性。此外,论文还使用了特定的网络结构来处理3D关键点输入,并输出机器人的关节控制信号。具体的参数设置和网络结构细节在论文中有详细描述。
🖼️ 关键图片


📊 实验亮点
实验结果表明,GenMimic在模拟环境中优于现有的基线方法,并且能够在真实的Unitree G1人形机器人上实现连贯、物理稳定的运动跟踪,而无需进行任何微调。这表明GenMimic具有良好的泛化能力和鲁棒性,能够有效地处理生成视频中的噪声和形态失真。论文还提出了GenMimicBench数据集,为未来的研究提供了一个有用的基准。
🎯 应用场景
该研究成果具有广泛的应用前景,例如:1) 机器人辅助康复:利用生成视频生成各种康复动作,并指导机器人辅助患者进行康复训练。2) 机器人舞蹈:利用生成视频生成各种舞蹈动作,并控制机器人进行舞蹈表演。3) 机器人模仿学习:利用生成视频作为机器人的训练数据,使机器人能够学习各种人类技能。这项研究为机器人控制提供了一种新的思路,有望推动机器人技术的发展。
📄 摘要(原文)
Video generation models are rapidly improving in their ability to synthesize human actions in novel contexts, holding the potential to serve as high-level planners for contextual robot control. To realize this potential, a key research question remains open: how can a humanoid execute the human actions from generated videos in a zero-shot manner? This challenge arises because generated videos are often noisy and exhibit morphological distortions that make direct imitation difficult compared to real video. To address this, we introduce a two-stage pipeline. First, we lift video pixels into a 4D human representation and then retarget to the humanoid morphology. Second, we propose GenMimic-a physics-aware reinforcement learning policy conditioned on 3D keypoints, and trained with symmetry regularization and keypoint-weighted tracking rewards. As a result, GenMimic can mimic human actions from noisy, generated videos. We curate GenMimicBench, a synthetic human-motion dataset generated using two video generation models across a spectrum of actions and contexts, establishing a benchmark for assessing zero-shot generalization and policy robustness. Extensive experiments demonstrate improvements over strong baselines in simulation and confirm coherent, physically stable motion tracking on a Unitree G1 humanoid robot without fine-tuning. This work offers a promising path to realizing the potential of video generation models as high-level policies for robot control.