MOVE: A Simple Motion-Based Data Collection Paradigm for Spatial Generalization in Robotic Manipulation
作者: Huanqian Wang, Chi Bene Chen, Yang Yue, Danhua Tao, Tong Guo, Shaoxuan Xie, Denghang Huang, Shiji Song, Guocai Yao, Gao Huang
分类: cs.RO
发布日期: 2025-12-04
备注: 9 pages, 9 figures
🔗 代码/项目: GITHUB
💡 一句话要点
提出MOVE:一种基于运动的数据收集范式,提升机器人操作的空间泛化能力
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 机器人操作 模仿学习 空间泛化 数据增强 运动规划
📋 核心要点
- 现有模仿学习方法在机器人操作中面临空间泛化能力不足的挑战,主要原因是训练数据缺乏空间多样性。
- MOVE通过在数据收集过程中引入物体运动,隐式地生成更丰富、更密集的空间配置,从而提升数据效率。
- 实验结果表明,MOVE在仿真和真实环境中均能显著提高机器人操作的空间泛化能力,并提升数据效率。
📝 摘要(中文)
模仿学习在机器人操作领域展现出巨大潜力,但数据稀缺性严重制约了其应用。现有大规模数据集构建工作仍难以实现鲁棒的空间泛化。我们发现一个关键限制:单个轨迹通常来自环境的单一静态空间配置,包括固定的物体和目标位置以及不变的相机视角,这大大限制了可用于学习的空间信息的多样性。为了解决数据效率瓶颈,我们提出了基于运动的可变性增强(MOVE),一种简单而有效的数据收集范式,能够从动态演示中获取更丰富的空间信息。核心贡献是一种增强策略,为每次演示中的任何可移动物体注入运动,从而在单个轨迹内隐式生成密集且多样的空间配置。在仿真和真实环境中进行了大量实验验证了该方法。例如,在需要强空间泛化的仿真任务中,MOVE实现了39.1%的平均成功率,相比静态数据收集范式(22.2%)相对提升了76.1%,并在某些任务上实现了2-5倍的数据效率提升。代码已开源。
🔬 方法详解
问题定义:现有机器人模仿学习方法在数据收集时,通常采用静态环境配置,即物体和目标位置固定,相机视角不变。这种方式导致训练数据缺乏空间多样性,限制了模型在新的空间配置下的泛化能力。因此,需要一种更高效的数据收集方法,能够以更少的数据量学习到更强的空间泛化能力。
核心思路:MOVE的核心思路是在数据收集过程中,通过引入物体运动来增加空间多样性。具体来说,在每次演示中,对环境中可移动的物体施加随机运动,使得物体在轨迹执行过程中不断改变其空间位置。这样,即使是单个轨迹,也包含了多个不同的空间配置,从而提高了数据的利用率和模型的泛化能力。
技术框架:MOVE的数据收集流程如下:1) 初始化环境,包括物体和目标位置;2) 对环境中可移动的物体施加随机运动;3) 执行机器人操作任务,同时记录轨迹数据;4) 重复步骤1-3,收集多个轨迹数据。在训练阶段,使用收集到的轨迹数据训练模仿学习模型。
关键创新:MOVE的关键创新在于其数据收集范式,通过在数据收集过程中引入物体运动,隐式地生成更丰富、更密集的空间配置。与传统的静态数据收集方法相比,MOVE能够以更少的数据量学习到更强的空间泛化能力。
关键设计:MOVE的关键设计在于如何控制物体的运动。论文中采用了一种简单的随机运动策略,即对物体施加随机的力和扭矩。此外,还可以根据具体的任务需求,设计更复杂的运动模式,例如,沿着特定的轨迹运动,或者根据环境反馈进行调整。
🖼️ 关键图片
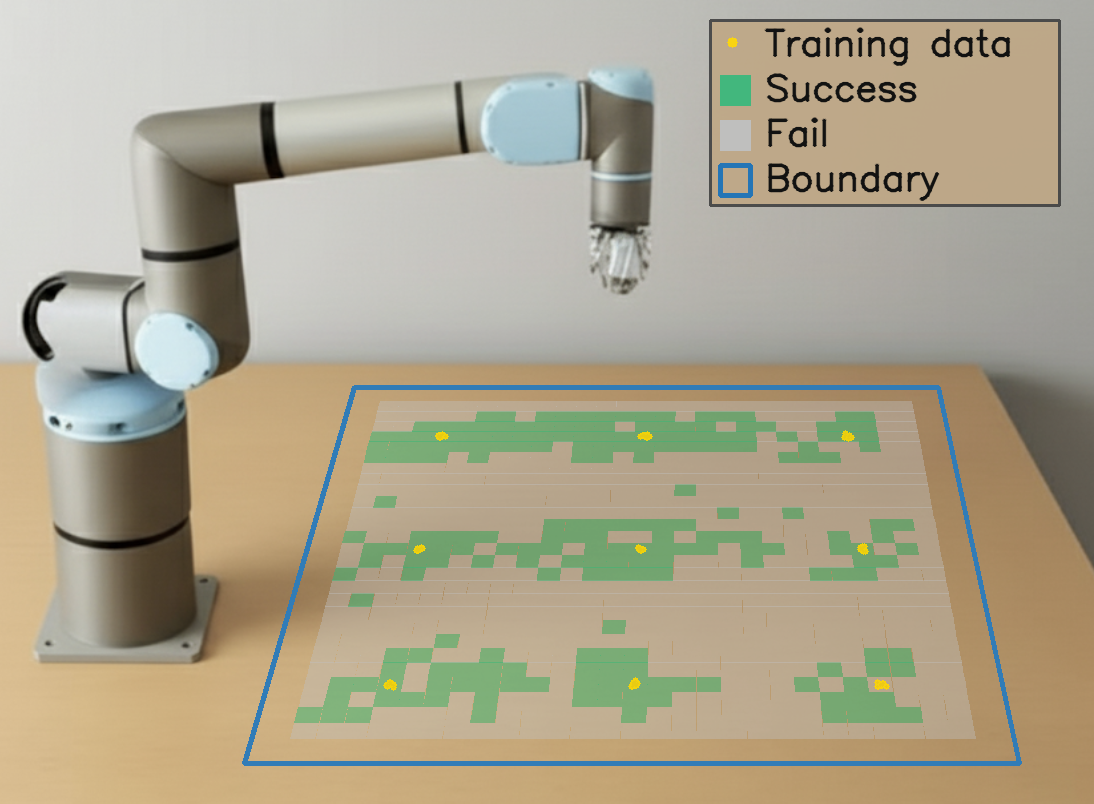


📊 实验亮点
在仿真实验中,MOVE在需要强空间泛化的任务上,平均成功率达到39.1%,相比静态数据收集范式(22.2%)提升了76.1%。在某些任务上,MOVE实现了2-5倍的数据效率提升。这些结果表明,MOVE能够显著提高机器人操作的空间泛化能力,并提升数据效率。
🎯 应用场景
MOVE方法可广泛应用于各种机器人操作任务,尤其是在需要较强空间泛化能力的场景中,例如,家庭服务机器人、工业机器人等。通过MOVE,机器人可以更好地适应不同的环境配置,完成各种复杂的任务。此外,MOVE还可以用于生成更逼真的机器人仿真环境,从而加速机器人算法的开发和测试。
📄 摘要(原文)
Imitation learning method has shown immense promise for robotic manipulation, yet its practical deployment is fundamentally constrained by the data scarcity. Despite prior work on collecting large-scale datasets, there still remains a significant gap to robust spatial generalization. We identify a key limitation: individual trajectories, regardless of their length, are typically collected from a \emph{single, static spatial configuration} of the environment. This includes fixed object and target spatial positions as well as unchanging camera viewpoints, which significantly restricts the diversity of spatial information available for learning. To address this critical bottleneck in data efficiency, we propose \textbf{MOtion-Based Variability Enhancement} (\emph{MOVE}), a simple yet effective data collection paradigm that enables the acquisition of richer spatial information from dynamic demonstrations. Our core contribution is an augmentation strategy that injects motion into any movable objects within the environment for each demonstration. This process implicitly generates a dense and diverse set of spatial configurations within a single trajectory. We conduct extensive experiments in both simulation and real-world environments to validate our approach. For example, in simulation tasks requiring strong spatial generalization, \emph{MOVE} achieves an average success rate of 39.1\%, a 76.1\% relative improvement over the static data collection paradigm (22.2\%), and yields up to 2--5$\times$ gains in data efficiency on certain tasks. Our code is available at https://github.com/lucywang720/MOVE.