Hierarchical Vision Language Action Model Using Success and Failure Demonstrations
作者: Jeongeun Park, Jihwan Yoon, Byungwoo Jeon, Juhan Park, Jinwoo Shin, Namhoon Cho, Kyungjae Lee, Sangdoo Yun, Sungjoon Choi
分类: cs.RO, cs.AI
发布日期: 2025-12-03
备注: https://vine-vla.github.io/
💡 一句话要点
提出VINE模型,利用成功与失败演示提升视觉-语言-动作模型的鲁棒性
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言动作模型 分层强化学习 失败数据利用 鲁棒性提升 场景图抽象
📋 核心要点
- 现有VLA模型忽略了失败数据中蕴含的策略脆弱性信息,限制了模型鲁棒性的提升。
- VINE模型通过分层强化学习框架,将高层推理与低层控制分离,使失败数据能够作为结构化学习信号。
- 实验表明,VINE模型在操作任务中显著提高了成功率和鲁棒性,验证了失败数据的重要性。
📝 摘要(中文)
现有的视觉-语言-动作(VLA)模型通常在远程操作的成功演示上进行训练,而忽略了数据收集过程中自然发生的许多失败尝试。然而,这些失败编码了策略在何处以及如何变得脆弱的信息,这些信息可以被利用来提高鲁棒性。我们通过利用混合质量的数据集来学习规划时的失败感知推理来解决这个问题。我们引入了VINE,一个分层视觉-语言-动作模型,它在分层强化学习形式下将高层推理(系统2)与低层控制(系统1)分离,使失败可以用作结构化的学习信号,而不是嘈杂的监督。系统2在2D场景图抽象上执行可行性引导的树搜索:它提出子目标转换,从成功和失败中预测成功概率,并在执行前修剪脆弱的分支,有效地将计划评估转化为可行性评分。然后,将选择的子目标序列传递给系统1,系统1执行低级动作而不修改代理的核心技能。VINE完全从离线远程操作数据中训练,直接将负面经验集成到决策循环中。在具有挑战性的操作任务中,这种方法始终提高成功率和鲁棒性,表明失败数据是将VLA的广泛能力转化为鲁棒执行的重要资源。
🔬 方法详解
问题定义:现有视觉-语言-动作(VLA)模型主要依赖于成功的演示数据进行训练,忽略了在数据采集过程中产生的失败案例。这些失败案例实际上包含了策略的脆弱点信息,能够帮助模型学习如何避免失败,提高鲁棒性。因此,如何有效地利用这些失败数据成为了一个关键问题。
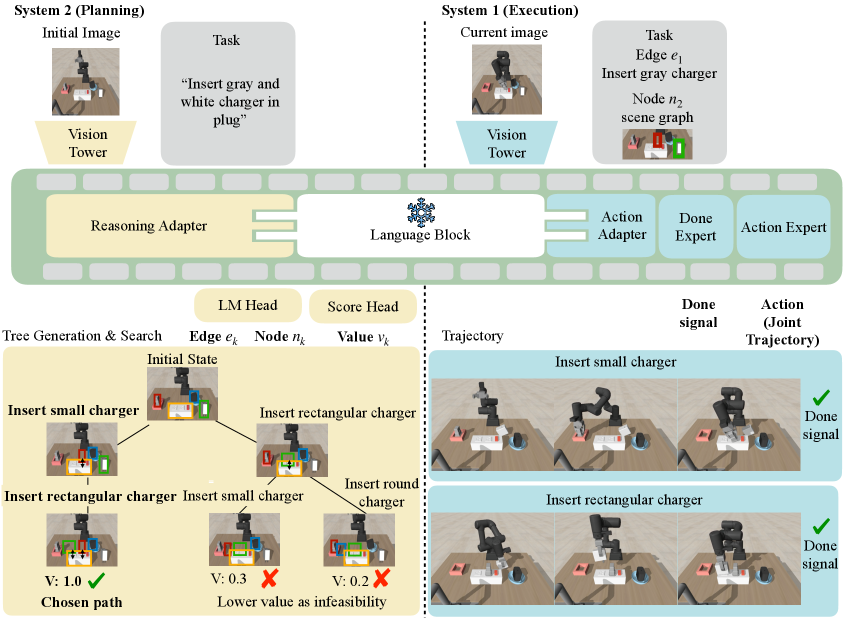
核心思路:VINE模型的核心思路是将高层推理(System 2)和低层控制(System 1)分离,构建一个分层强化学习框架。System 2负责进行全局规划,利用成功和失败的经验评估子目标的feasibility,从而选择更稳健的行动序列。System 1则负责执行System 2选择的低层动作,专注于动作的执行,而不改变agent的核心技能。
技术框架:VINE模型包含两个主要模块:System 2和System 1。System 2首先将视觉输入转化为2D场景图抽象,然后在此基础上进行可行性引导的树搜索。树搜索过程中,System 2会预测每个子目标的成功概率,并根据成功概率修剪脆弱的分支。最终,System 2选择的子目标序列会被传递给System 1。System 1接收到子目标序列后,执行相应的低层动作,完成任务。整个框架采用离线训练方式,直接从远程操作数据中学习。
关键创新:VINE模型的关键创新在于将失败数据直接融入到决策循环中。通过System 2对子目标可行性的评估,模型能够学习到哪些行动容易导致失败,从而在规划阶段避免这些行动。这种失败感知的推理方式显著提高了模型的鲁棒性。此外,分层架构的设计使得模型能够更好地处理复杂任务,将全局规划和局部执行解耦。
关键设计:System 2使用可行性评分来评估子目标的优劣,可行性评分的计算依赖于成功和失败的经验数据。具体来说,模型会学习一个函数,该函数能够根据当前状态和子目标预测成功概率。在树搜索过程中,System 2会根据预测的成功概率对分支进行修剪,选择成功概率较高的分支。System 1采用标准的强化学习算法进行训练,专注于低层动作的执行。
🖼️ 关键图片

📊 实验亮点
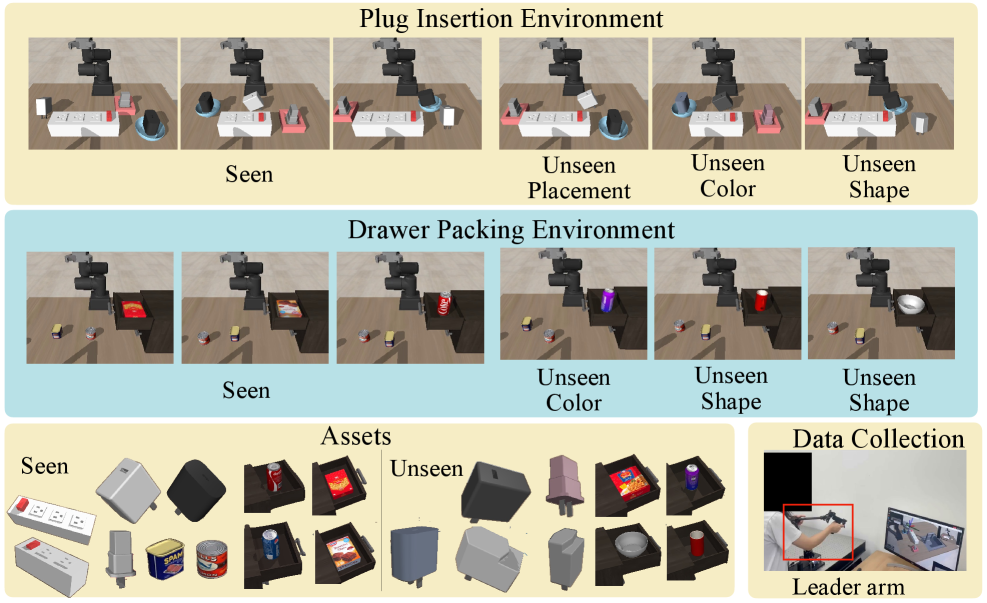
实验结果表明,VINE模型在多个具有挑战性的操作任务中,显著提高了成功率和鲁棒性。与基线方法相比,VINE模型能够更好地利用失败数据,从而做出更明智的决策。具体的性能提升数据在论文中有详细展示,证明了该方法的有效性。
🎯 应用场景
VINE模型可应用于机器人操作、自动驾驶、游戏AI等领域。通过利用失败数据,可以显著提高智能体在复杂环境中的鲁棒性和可靠性。该研究有助于推动智能体在真实世界中的应用,例如在家庭服务机器人、工业自动化等场景中。
📄 摘要(原文)
Prior Vision-Language-Action (VLA) models are typically trained on teleoperated successful demonstrations, while discarding numerous failed attempts that occur naturally during data collection. However, these failures encode where and how policies can be fragile, information that can be exploited to improve robustness. We address this problem by leveraging mixed-quality datasets to learn failure-aware reasoning at planning time. We introduce VINE, a hierarchical vision-language-action model that separates high-level reasoning (System 2) from low-level control (System 1) under a hierarchical reinforcement learning formalism, making failures usable as a structured learning signal rather than noisy supervision. System 2 performs feasibility-guided tree search over a 2D scene-graph abstraction: it proposes subgoal transitions, predicts success probabilities from both successes and failures, and prunes brittle branches before execution, effectively casting plan evaluation as feasibility scoring. The selected subgoal sequence is then passed to System 1, which executes low-level actions without modifying the agent's core skills. Trained entirely from offline teleoperation data, VINE integrates negative experience directly into the decision loop. Across challenging manipulation tasks, this approach consistently improves success rates and robustness, demonstrating that failure data is an essential resource for converting the broad competence of VLAs into robust execution.