OmniDexVLG: Learning Dexterous Grasp Generation from Vision Language Model-Guided Grasp Semantics, Taxonomy and Functional Affordance
作者: Lei Zhang, Diwen Zheng, Kaixin Bai, Zhenshan Bing, Zoltan-Csaba Marton, Zhaopeng Chen, Alois Christian Knoll, Jianwei Zhang
分类: cs.RO, cs.LG
发布日期: 2025-12-03
备注: Project Website: https://sites.google.com/view/omnidexvlg, 16 pages
💡 一句话要点
OmniDexVLG:提出基于视觉语言模型引导的灵巧抓取生成框架,实现语义可控的抓取合成。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 灵巧抓取 视觉语言模型 多模态学习 语义推理 机器人操作
📋 核心要点
- 现有灵巧抓取生成方法缺乏对抓取分类、接触语义和功能可供性等多维度语义的统一建模,难以实现语义可控的抓取合成。
- OmniDexVLG通过构建语义丰富的抓取数据集和多模态语义推理模块,显式地结合抓取分类、接触结构和功能可供性语义,实现细粒度的抓取控制。
- 实验结果表明,OmniDexVLG在抓取多样性、接触语义多样性、功能可供性多样性和语义一致性方面显著优于现有方法。
📝 摘要(中文)
本文提出OmniDexVLG,一个多模态、语义感知的抓取生成框架,能够在联合语言和视觉指导下生成结构多样且语义连贯的灵巧抓取。该方法首先构建了OmniDexDataGen,一个语义丰富的灵巧抓取数据集生成流程,集成了抓取分类引导的配置采样、功能可供性接触点采样、分类感知的微分力闭合抓取采样以及基于物理的优化和验证,从而系统地覆盖了各种抓取类型。进一步引入OmniDexReasoner,一个多模态抓取类型语义推理模块,利用多智能体协作、检索增强生成和思维链推理来推断抓取相关的语义,并生成高质量的标注,使语言指令与特定任务的抓取意图对齐。在此基础上,开发了一个统一的视觉语言抓取生成模型,显式地结合了抓取分类、接触结构和功能可供性语义,从而能够从自然语言指令中对抓取合成进行细粒度的控制。在模拟和真实物体抓取中的大量实验和消融研究表明,该方法在抓取多样性、接触语义多样性、功能可供性多样性和语义一致性方面显著优于现有技术。
🔬 方法详解
问题定义:现有灵巧抓取生成方法难以统一建模抓取分类、接触语义和功能可供性等多维度语义,导致无法根据任务需求和人类可解释的抓取语义生成抓取姿势,缺乏语义可控性。现有方法在生成结构多样和语义连贯的灵巧抓取方面存在挑战。
核心思路:论文的核心思路是构建一个多模态、语义感知的抓取生成框架,通过显式地结合抓取分类、接触结构和功能可供性语义,实现从自然语言指令到抓取姿势的细粒度控制。该方法通过数据生成流程和语义推理模块,将语言指令与特定任务的抓取意图对齐,从而生成语义连贯的抓取。
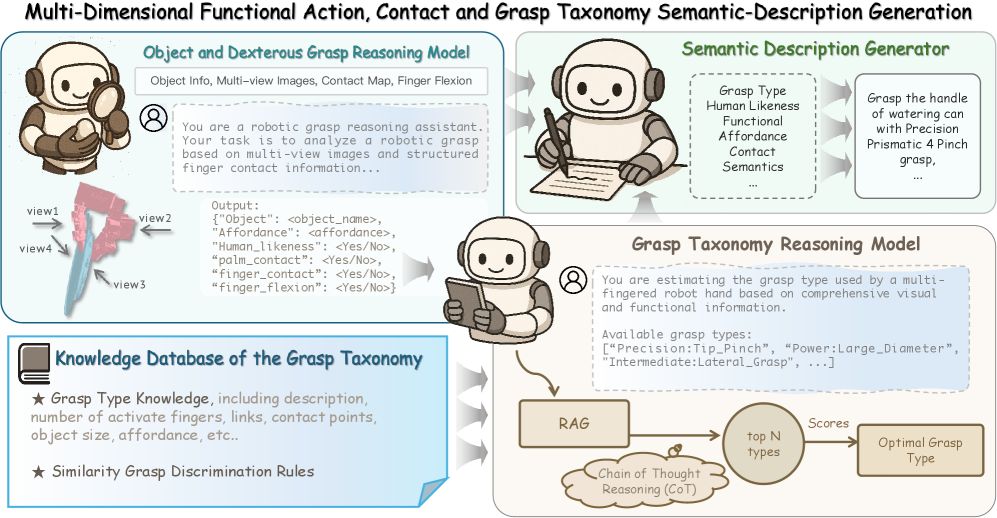
技术框架:OmniDexVLG框架主要包含三个模块:OmniDexDataGen、OmniDexReasoner和视觉语言抓取生成模型。OmniDexDataGen负责生成语义丰富的抓取数据集,OmniDexReasoner负责进行多模态抓取类型语义推理,视觉语言抓取生成模型则利用前两者的输出,生成最终的抓取姿势。整体流程是从语言指令和视觉输入开始,通过OmniDexReasoner进行语义推理,然后由视觉语言抓取生成模型生成抓取姿势。
关键创新:论文的关键创新在于:1) 提出了OmniDexDataGen,一个语义丰富的灵巧抓取数据集生成流程,能够系统地覆盖各种抓取类型;2) 引入了OmniDexReasoner,一个多模态抓取类型语义推理模块,能够推断抓取相关的语义,并生成高质量的标注;3) 开发了一个统一的视觉语言抓取生成模型,显式地结合了抓取分类、接触结构和功能可供性语义。
关键设计:OmniDexDataGen中,采用了抓取分类引导的配置采样、功能可供性接触点采样、分类感知的微分力闭合抓取采样以及基于物理的优化和验证。OmniDexReasoner利用多智能体协作、检索增强生成和思维链推理。视觉语言抓取生成模型具体网络结构和损失函数细节未知,但其核心在于将抓取分类、接触结构和功能可供性语义显式地融入到模型中。
🖼️ 关键图片


📊 实验亮点
实验结果表明,OmniDexVLG在模拟和真实物体抓取任务中,在抓取多样性、接触语义多样性、功能可供性多样性和语义一致性方面显著优于现有方法。具体性能提升数据未知,但整体效果表明该方法具有较强的实用性和优越性。
🎯 应用场景
该研究成果可应用于机器人灵巧操作、自动化装配、智能辅助等领域。通过自然语言指令控制机器人进行复杂的抓取任务,提高机器人的智能化水平和适应性。未来可进一步扩展到更复杂的任务场景,例如医疗手术、灾难救援等。
📄 摘要(原文)
Dexterous grasp generation aims to produce grasp poses that align with task requirements and human interpretable grasp semantics. However, achieving semantically controllable dexterous grasp synthesis remains highly challenging due to the lack of unified modeling of multiple semantic dimensions, including grasp taxonomy, contact semantics, and functional affordance. To address these limitations, we present OmniDexVLG, a multimodal, semantics aware grasp generation framework capable of producing structurally diverse and semantically coherent dexterous grasps under joint language and visual guidance. Our approach begins with OmniDexDataGen, a semantic rich dexterous grasp dataset generation pipeline that integrates grasp taxonomy guided configuration sampling, functional affordance contact point sampling, taxonomy aware differential force closure grasp sampling, and physics based optimization and validation, enabling systematic coverage of diverse grasp types. We further introduce OmniDexReasoner, a multimodal grasp type semantic reasoning module that leverages multi agent collaboration, retrieval augmented generation, and chain of thought reasoning to infer grasp related semantics and generate high quality annotations that align language instructions with task specific grasp intent. Building upon these components, we develop a unified Vision Language Grasping generation model that explicitly incorporates grasp taxonomy, contact structure, and functional affordance semantics, enabling fine grained control over grasp synthesis from natural language instructions. Extensive experiments in simulation and real world object grasping and ablation studies demonstrate that our method substantially outperforms state of the art approaches in terms of grasp diversity, contact semantic diversity, functional affordance diversity, and semantic consistency.