Crossing the Sim2Real Gap Between Simulation and Ground Testing to Space Deployment of Autonomous Free-flyer Control
作者: Kenneth Stewart, Samantha Chapin, Roxana Leontie, Carl Glen Henshaw
分类: cs.RO, cs.LG, eess.SY
发布日期: 2025-12-03
备注: published at iSpaRo 2025
💡 一句话要点
首次在国际空间站验证基于强化学习的自由飞行器自主控制
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 空间机器人 自主控制 Sim2Real 在轨服务
📋 核心要点
- 现有空间机器人的控制方法难以适应动态变化的任务需求,限制了其在轨服务能力。
- 利用NVIDIA Omniverse进行高效的蒙特卡洛强化学习训练,弥合仿真到现实的差距。
- 成功将地面训练的强化学习策略部署到国际空间站的Astrobee机器人上,实现了自主导航。
📝 摘要(中文)
本文展示了基于强化学习(RL)的自主控制在空间机器人领域的变革潜力,首次在国际空间站(ISS)的NASA Astrobee自由飞行机器人上进行了在轨演示。通过使用NVIDIA Omniverse物理模拟器和课程学习,我们训练了一个深度神经网络来替代Astrobee的标准姿态和位移控制,使其能够在微重力环境中导航。实验结果验证了一种新颖的训练流程,该流程弥合了仿真到现实(Sim2Real)的差距,利用GPU加速的科学级仿真环境进行高效的蒙特卡洛RL训练。此次成功部署证明了在地面训练RL策略并将其转移到空间应用的可行性,为未来的在轨服务、组装和制造(ISAM)工作奠定了基础,从而能够快速适应动态的任务需求。
🔬 方法详解
问题定义:论文旨在解决空间自由飞行机器人在微重力环境下自主控制的问题。现有方法通常依赖于传统控制算法,这些算法在面对复杂或动态变化的环境时,适应性较差,需要人工进行大量的参数调整和优化。此外,在真实空间环境中进行算法测试成本高昂且风险大。
核心思路:论文的核心思路是利用强化学习(RL)训练一个深度神经网络控制器,使其能够自主学习如何在微重力环境下控制自由飞行机器人。通过在仿真环境中进行大量的训练,使RL策略能够适应各种复杂情况,然后将训练好的策略直接部署到真实机器人上。这种方法可以显著提高机器人的自主性和适应性,并降低开发和测试成本。
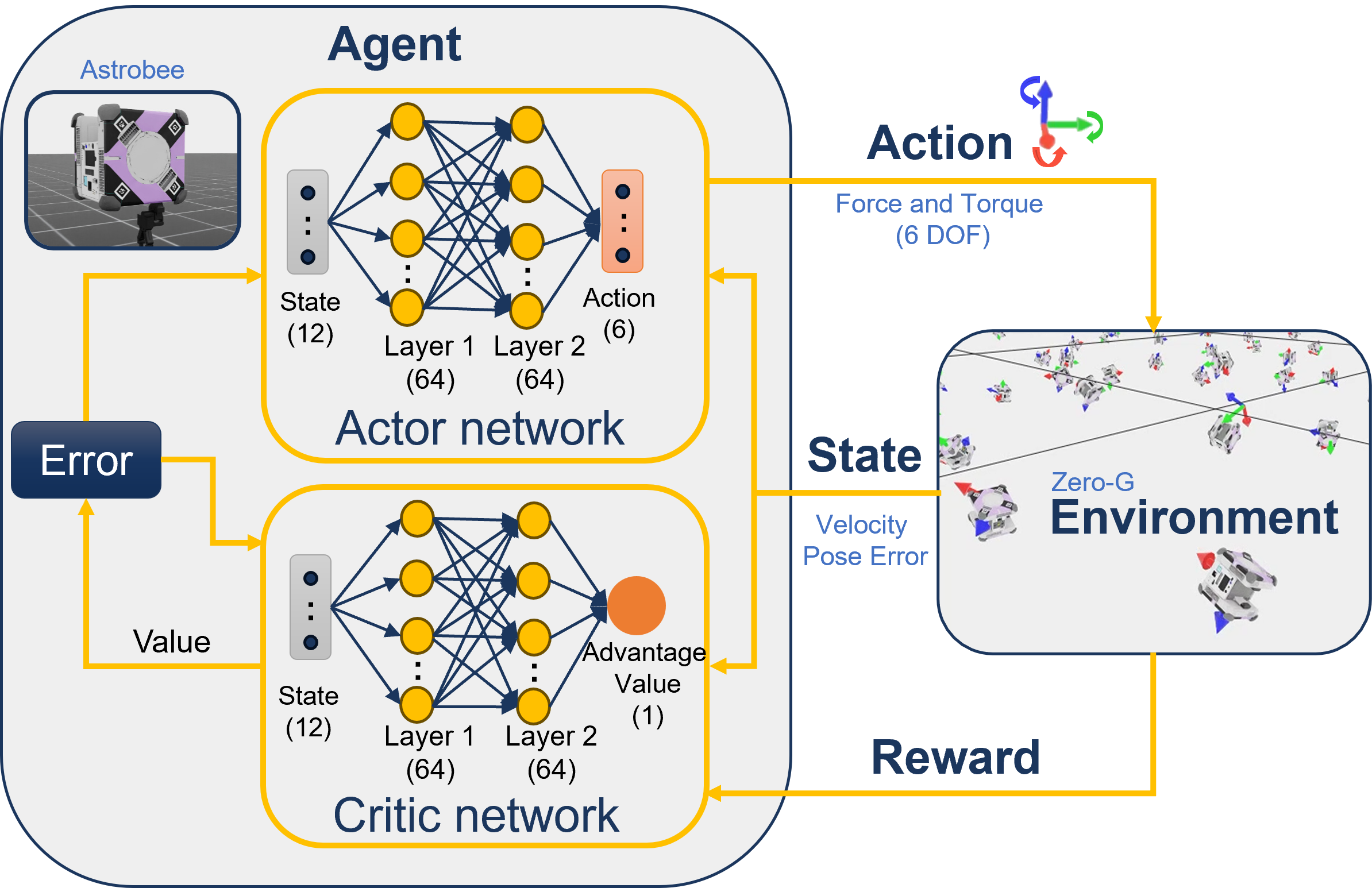
技术框架:整体框架包括三个主要部分:1) 基于NVIDIA Omniverse的物理仿真环境,用于生成训练数据;2) 基于课程学习的强化学习训练流程,用于训练深度神经网络控制器;3) 将训练好的控制器部署到NASA Astrobee自由飞行机器人上,并在国际空间站进行在轨测试。该流程利用GPU加速的仿真环境进行高效的蒙特卡洛RL训练,从而快速生成鲁棒的控制策略。
关键创新:论文的关键创新在于成功地将Sim2Real技术应用于空间机器人控制领域。通过精心设计的仿真环境和课程学习策略,有效地弥合了仿真环境和真实环境之间的差距,使得在仿真环境中训练的RL策略可以直接部署到真实机器人上,而无需进行大量的微调。
关键设计:论文使用了深度神经网络作为RL策略的表示形式,网络的具体结构未知。损失函数的设计目标是使机器人在微重力环境下能够稳定地进行姿态和位移控制,并尽可能地减少能量消耗。课程学习策略则通过逐步增加训练难度,使RL策略能够更好地泛化到各种复杂情况。
🖼️ 关键图片

📊 实验亮点
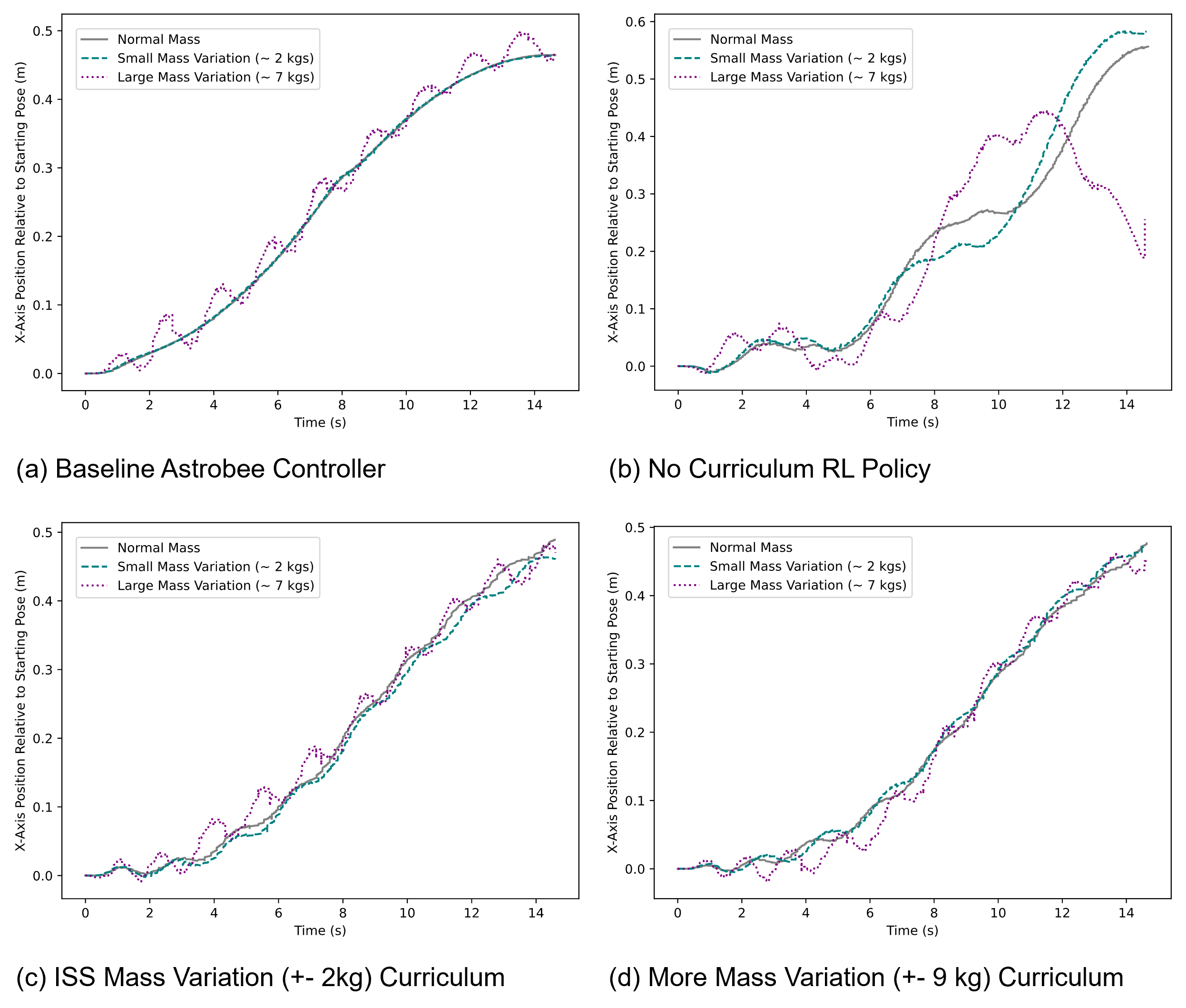
该研究首次在国际空间站成功演示了基于强化学习的自由飞行器自主控制。通过使用NVIDIA Omniverse物理模拟器和课程学习,训练了一个深度神经网络来替代Astrobee的标准控制,使其能够在微重力环境中自主导航。该实验验证了Sim2Real技术在空间机器人领域的有效性,为未来的空间机器人应用奠定了基础。具体的性能数据和对比基线未知。
🎯 应用场景
该研究成果可广泛应用于在轨服务、组装和制造(ISAM)等领域。例如,可以利用该技术实现空间站的自主维护、卫星的在轨维修、空间碎片清理等任务。此外,该技术还可以应用于深空探测任务,使探测器能够自主导航和执行科学探测任务,从而降低任务风险和成本。
📄 摘要(原文)
Reinforcement learning (RL) offers transformative potential for robotic control in space. We present the first on-orbit demonstration of RL-based autonomous control of a free-flying robot, the NASA Astrobee, aboard the International Space Station (ISS). Using NVIDIA's Omniverse physics simulator and curriculum learning, we trained a deep neural network to replace Astrobee's standard attitude and translation control, enabling it to navigate in microgravity. Our results validate a novel training pipeline that bridges the simulation-to-reality (Sim2Real) gap, utilizing a GPU-accelerated, scientific-grade simulation environment for efficient Monte Carlo RL training. This successful deployment demonstrates the feasibility of training RL policies terrestrially and transferring them to space-based applications. This paves the way for future work in In-Space Servicing, Assembly, and Manufacturing (ISAM), enabling rapid on-orbit adaptation to dynamic mission requirements.