Autonomous Planning In-space Assembly Reinforcement-learning free-flYer (APIARY) International Space Station Astrobee Testing
作者: Samantha Chapin, Kenneth Stewart, Roxana Leontie, Carl Glen Henshaw
分类: cs.RO, cs.LG, eess.SY
发布日期: 2025-12-03
备注: iSpaRo 2025, Best Paper Award in Orbital Robotics
💡 一句话要点
APIARY实验首次在国际空间站利用强化学习控制Astrobee机器人
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 空间机器人 自主控制 Astrobee 近端策略优化
📋 核心要点
- 现有空间机器人的控制策略开发周期长,难以快速适应变化的任务需求和环境。
- APIARY实验利用强化学习,在仿真环境中训练机器人控制策略,实现快速部署和定制化行为。
- 实验成功在国际空间站的Astrobee机器人上验证了该方法的有效性,展示了强化学习在空间机器人自主控制方面的潜力。
📝 摘要(中文)
美国海军研究实验室(NRL)的自主规划空间组装强化学习自由飞行器(APIARY)实验,率先在零重力(zero-G)空间环境中利用强化学习(RL)控制自由飞行机器人。2025年5月27日,APIARY团队首次在国际空间站(ISS)上使用NASA Astrobee机器人进行了自由飞行器的RL控制。该团队使用NVIDIA Isaac Lab仿真环境中的actor-critic近端策略优化(PPO)网络训练了一个鲁棒的6自由度(DOF)控制策略,通过随机化目标姿态和质量分布来增强鲁棒性。本文详细介绍了该实验的仿真测试、地面测试和飞行验证。这次在轨演示验证了RL在提高机器人自主性方面的变革潜力,能够快速开发和部署(在几分钟到几小时内)针对空间探索、物流和实时任务需求的定制行为。
🔬 方法详解
问题定义:论文旨在解决空间机器人自主控制的问题,特别是在零重力环境下,如何快速开发和部署适应不同任务需求的控制策略。传统方法依赖于人工设计和调整控制参数,耗时且难以适应复杂环境和任务变化。现有方法的痛点在于开发周期长、鲁棒性差,难以满足空间探索和实时任务的需求。
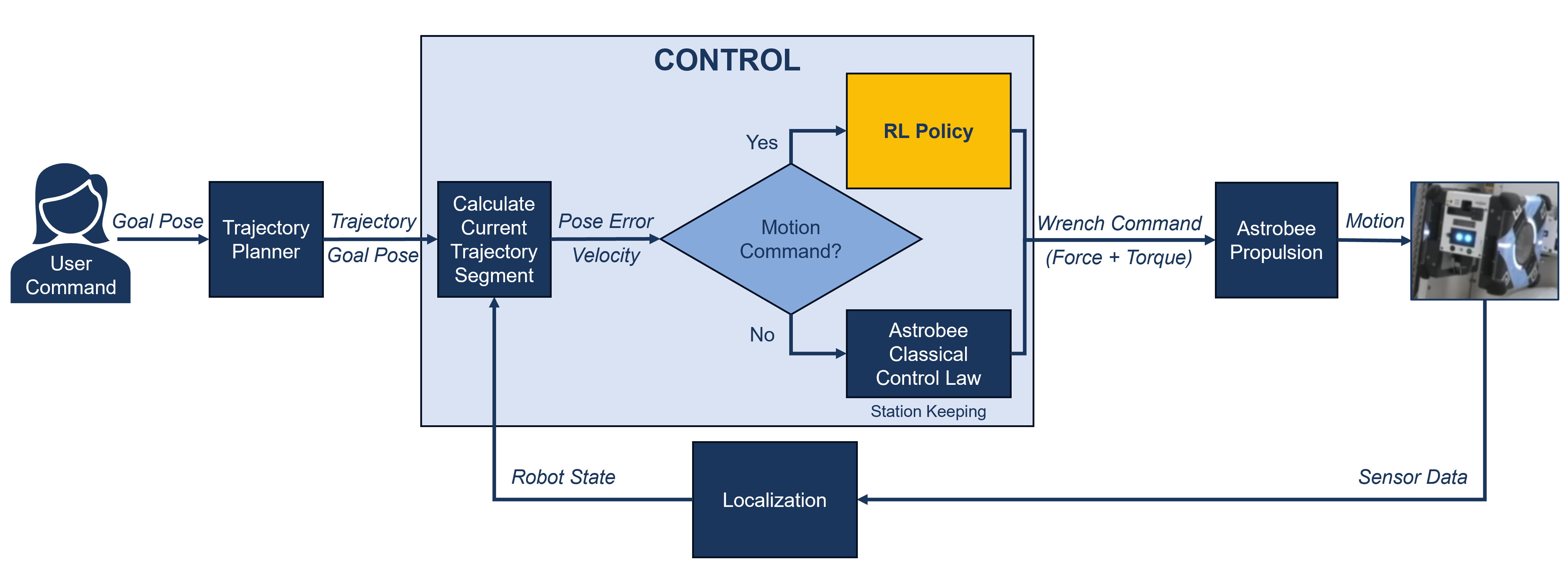
核心思路:论文的核心解决思路是利用强化学习(RL)技术,通过在仿真环境中训练机器人控制策略,使其能够自主学习适应不同任务和环境。这种方法避免了人工设计控制参数的繁琐过程,并能够通过随机化训练环境来提高策略的鲁棒性。核心在于利用RL的自学习能力,实现快速开发和部署定制化的机器人行为。
技术框架:APIARY实验的技术框架主要包括以下几个阶段:1) 在NVIDIA Isaac Lab仿真环境中构建Astrobee机器人的仿真模型;2) 使用近端策略优化(PPO)算法训练actor-critic网络,生成机器人控制策略;3) 通过随机化目标姿态和质量分布等参数,增强策略的鲁棒性;4) 在地面进行测试验证,确保策略的有效性;5) 在国际空间站(ISS)的Astrobee机器人上进行在轨实验,验证策略的实际性能。
关键创新:该论文最重要的技术创新点在于首次在国际空间站上成功实现了基于强化学习的自由飞行机器人控制。与传统的控制方法相比,该方法能够快速开发和部署定制化的机器人行为,并具有更强的鲁棒性和适应性。此外,通过在仿真环境中进行训练,大大降低了在真实环境中进行实验的成本和风险。
关键设计:论文的关键设计包括:1) 使用actor-critic结构的PPO算法,提高训练效率和稳定性;2) 在仿真环境中随机化目标姿态和质量分布,增强策略的鲁棒性;3) 设计合适的奖励函数,引导机器人学习期望的行为;4) 针对Astrobee机器人的动力学特性,优化网络结构和参数设置。
🖼️ 关键图片


📊 实验亮点
APIARY实验首次在国际空间站上成功验证了基于强化学习的自由飞行机器人控制策略。实验结果表明,该方法能够快速生成鲁棒的控制策略,并能够适应不同的任务需求。与传统的控制方法相比,该方法能够显著缩短开发周期,并提高机器人的自主性和适应性。具体性能数据未知,但实验验证了RL在空间机器人控制方面的巨大潜力。
🎯 应用场景
该研究成果可应用于空间探索、空间站维护、在轨组装等领域。例如,可以利用该技术控制机器人进行空间站外部的维修工作,或者在太空中组装大型结构。此外,该技术还可以应用于地面环境下的复杂机器人控制任务,例如在危险环境中进行救援或勘探。
📄 摘要(原文)
The US Naval Research Laboratory's (NRL's) Autonomous Planning In-space Assembly Reinforcement-learning free-flYer (APIARY) experiment pioneers the use of reinforcement learning (RL) for control of free-flying robots in the zero-gravity (zero-G) environment of space. On Tuesday, May 27th 2025 the APIARY team conducted the first ever, to our knowledge, RL control of a free-flyer in space using the NASA Astrobee robot on-board the International Space Station (ISS). A robust 6-degrees of freedom (DOF) control policy was trained using an actor-critic Proximal Policy Optimization (PPO) network within the NVIDIA Isaac Lab simulation environment, randomizing over goal poses and mass distributions to enhance robustness. This paper details the simulation testing, ground testing, and flight validation of this experiment. This on-orbit demonstration validates the transformative potential of RL for improving robotic autonomy, enabling rapid development and deployment (in minutes to hours) of tailored behaviors for space exploration, logistics, and real-time mission needs.