RoboScape-R: Unified Reward-Observation World Models for Generalizable Robotics Training via RL
作者: Yinzhou Tang, Yu Shang, Yinuo Chen, Bingwen Wei, Xin Zhang, Shu'ang Yu, Liangzhi Shi, Chao Yu, Chen Gao, Wei Wu, Yong Li
分类: cs.RO, cs.CV
发布日期: 2025-12-03
💡 一句话要点
RoboScape-R:提出基于世界模型的通用奖励机制,提升机器人强化学习的泛化性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 机器人强化学习 世界模型 泛化能力 内生奖励 具身智能
📋 核心要点
- 传统强化学习在机器人领域泛化性差,主要原因是缺乏统一的、可泛化的奖励信号,导致策略难以适应新环境。
- RoboScape-R利用世界模型作为通用环境代理,通过内生的奖励机制,使智能体能够从对环境动态的理解中学习。
- 实验表明,RoboScape-R显著提升了具身智能策略的泛化能力,在超出领域场景下,性能平均提升了37.5%。
📝 摘要(中文)
实现可泛化的具身智能策略仍然是一个关键挑战。传统的策略学习范式,包括模仿学习(IL)和强化学习(RL),都难以在不同的场景中培养泛化能力。模仿学习策略通常过度拟合特定的专家轨迹,而强化学习则受到缺乏统一和通用的奖励信号的限制,这对于有效的多场景泛化至关重要。我们认为世界模型能够作为一种通用的环境代理来解决这一局限性。然而,当前的世界模型主要关注于预测观测结果,并且仍然依赖于特定任务的手工设计的奖励函数,因此无法提供一个真正通用的训练环境。针对这个问题,我们提出了RoboScape-R,一个利用世界模型作为强化学习范式中具身环境的通用代理的框架。我们引入了一种新颖的基于世界模型的通用奖励机制,该机制生成源于模型对真实世界状态转移动态的内在理解的“内生”奖励。大量的实验表明,RoboScape-R通过提供一个高效和通用的训练环境,有效地解决了传统强化学习方法的局限性,从而大大提高了具身策略的泛化能力。我们的方法为利用世界模型作为在线训练策略提供了重要的见解,并且在超出领域场景下,性能比基线提高了平均37.5%。
🔬 方法详解
问题定义:现有强化学习方法在机器人任务中难以泛化到新的环境。主要痛点在于,奖励函数通常是手工设计的、特定于任务的,无法反映环境的真实动态,导致智能体只能在特定场景下表现良好,而无法适应新的、未知的环境。
核心思路:论文的核心思路是利用世界模型来学习环境的动态特性,并从中提取出通用的奖励信号。通过让智能体在世界模型中进行训练,可以使其学习到环境的内在规律,从而提高其在真实环境中的泛化能力。这种方法避免了手工设计奖励函数的局限性,使得智能体能够自主地探索和学习。
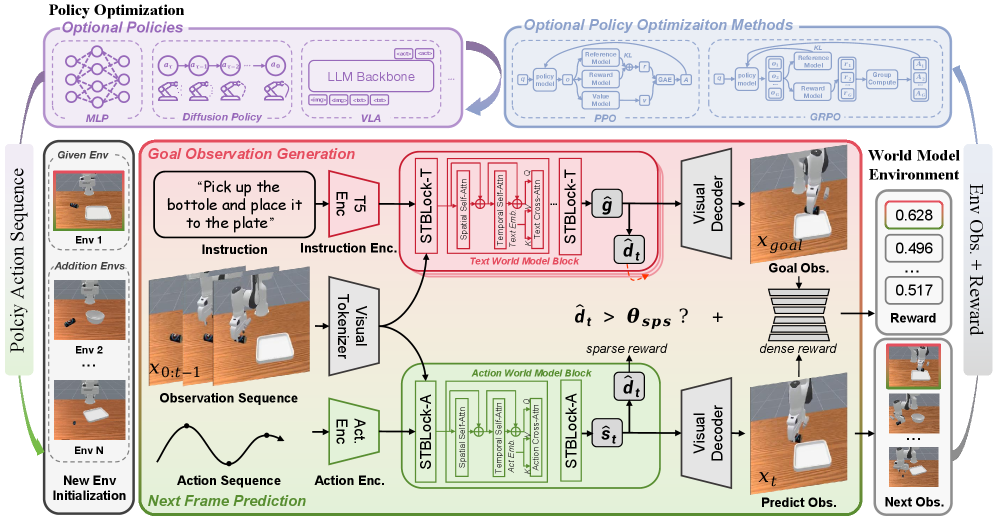
技术框架:RoboScape-R框架主要包含以下几个模块:1)世界模型:用于学习环境的动态特性,包括状态转移和观测预测;2)内生奖励生成器:基于世界模型的预测误差或状态变化,生成奖励信号;3)强化学习智能体:在世界模型中进行训练,以最大化内生奖励;4)策略部署:将训练好的策略部署到真实环境中。整个流程是,智能体在世界模型中与环境交互,世界模型预测下一步的状态和观测,内生奖励生成器根据预测结果生成奖励,智能体根据奖励更新策略,最终将学习到的策略应用到真实环境中。
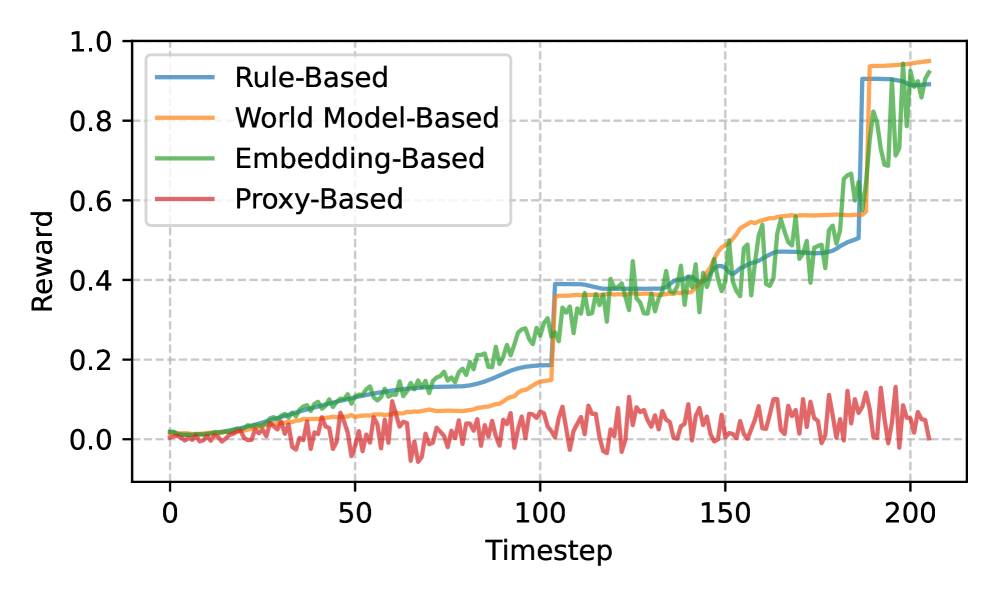
关键创新:该论文最重要的技术创新点在于提出了基于世界模型的通用奖励机制。与传统的强化学习方法不同,该方法不需要手工设计奖励函数,而是通过世界模型自动生成奖励信号。这种内生奖励机制能够反映环境的真实动态,从而提高智能体的泛化能力。此外,该方法还提出了一种新的训练策略,即在世界模型中进行训练,然后在真实环境中进行微调,从而进一步提高泛化能力。
关键设计:世界模型通常采用循环神经网络(RNN)或Transformer结构,用于学习环境的状态转移和观测预测。内生奖励生成器可以基于预测误差、状态变化或信息增益等指标来生成奖励信号。强化学习智能体可以使用各种算法,如PPO、SAC等。关键参数包括世界模型的容量、奖励函数的权重、学习率等。损失函数通常包括世界模型的预测误差损失和强化学习的策略梯度损失。
🖼️ 关键图片
📊 实验亮点
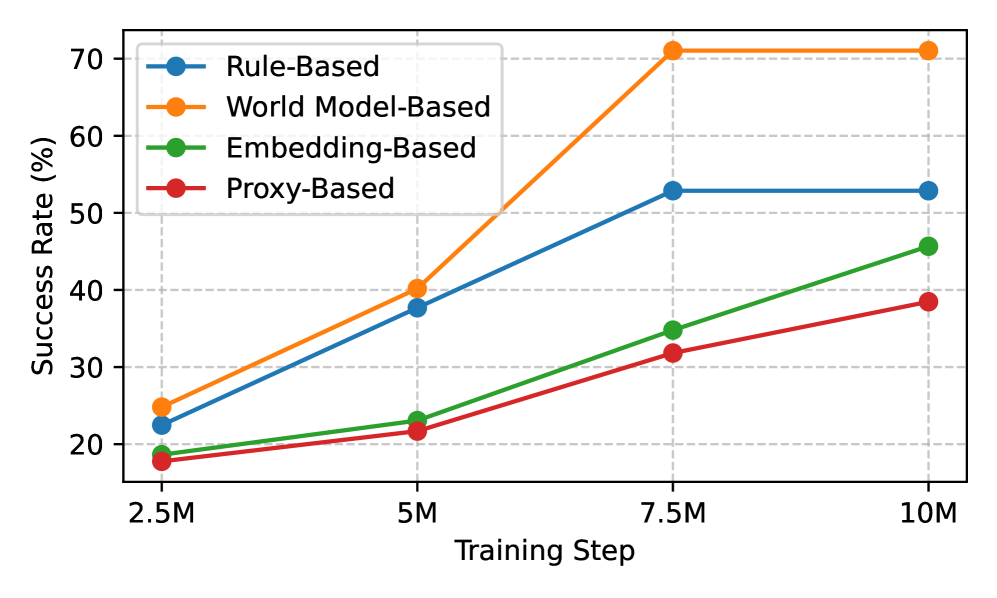
实验结果表明,RoboScape-R在多个机器人任务中都取得了显著的性能提升。在超出领域场景下,RoboScape-R的性能比基线方法平均提高了37.5%。这表明RoboScape-R能够有效地提高具身智能策略的泛化能力,使其能够适应新的、未知的环境。
🎯 应用场景
RoboScape-R具有广泛的应用前景,例如,可以应用于各种机器人任务,如导航、操作、抓取等。该方法可以降低机器人开发的成本和难度,提高机器人的自主性和适应性。此外,该方法还可以应用于游戏AI、自动驾驶等领域,具有重要的实际价值和未来影响。
📄 摘要(原文)
Achieving generalizable embodied policies remains a key challenge. Traditional policy learning paradigms, including both Imitation Learning (IL) and Reinforcement Learning (RL), struggle to cultivate generalizability across diverse scenarios. While IL policies often overfit to specific expert trajectories, RL suffers from the inherent lack of a unified and general reward signal necessary for effective multi-scene generalization. We posit that the world model is uniquely capable of serving as a universal environment proxy to address this limitation. However, current world models primarily focus on their ability to predict observations and still rely on task-specific, handcrafted reward functions, thereby failing to provide a truly general training environment. Toward this problem, we propose RoboScape-R, a framework leveraging the world model to serve as a versatile, general-purpose proxy for the embodied environment within the RL paradigm. We introduce a novel world model-based general reward mechanism that generates ''endogenous'' rewards derived from the model's intrinsic understanding of real-world state transition dynamics. Extensive experiments demonstrate that RoboScape-R effectively addresses the limitations of traditional RL methods by providing an efficient and general training environment that substantially enhances the generalization capability of embodied policies. Our approach offers critical insights into utilizing the world model as an online training strategy and achieves an average 37.5% performance improvement over baselines under out-of-domain scenarios.