World Models for Autonomous Navigation of Terrestrial Robots from LIDAR Observations
作者: Raul Steinmetz, Fabio Demo Rosa, Victor Augusto Kich, Jair Augusto Bottega, Ricardo Bedin Grando, Daniel Fernando Tello Gamarra
分类: cs.RO, cs.AI
发布日期: 2025-12-03
备注: Accepted for publication in the Journal of Intelligent and Fuzzy Systems
💡 一句话要点
提出基于DreamerV3和MLP-VAE的世界模型,提升激光雷达数据驱动的机器人自主导航性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 机器人导航 强化学习 世界模型 激光雷达 变分自编码器 DreamerV3 自主导航
📋 核心要点
- 现有方法难以处理高维激光雷达数据,导致机器人空间感知能力受限,导航鲁棒性降低。
- 利用MLP-VAE将高维激光雷达数据压缩为低维潜在表示,结合DreamerV3进行策略优化。
- 实验表明,该方法在TurtleBot3导航任务中,收敛速度更快,成功率更高,尤其是在完整激光雷达数据下。
📝 摘要(中文)
本文提出了一种新颖的基于模型的强化学习框架,用于解决激光雷达观测驱动的陆地机器人自主导航问题。该框架基于DreamerV3算法,并集成了一个多层感知机变分自编码器(MLP-VAE)到世界模型中,以将高维激光雷达数据编码为紧凑的潜在表示。这些潜在特征与学习到的动态预测器相结合,实现了高效的基于想象的策略优化。在模拟的TurtleBot3导航任务上的实验表明,与SAC、DDPG和TD3等无模型基线相比,所提出的架构实现了更快的收敛速度和更高的成功率。值得强调的是,基于DreamerV3的智能体在使用Turtlebot3激光雷达的完整数据集(360个读数)时,在所有评估环境中都达到了100%的成功率,而无模型方法的成功率则低于85%。这些发现表明,将预测世界模型与学习到的潜在表示相结合,能够从高维感官数据中实现更高效和鲁棒的导航。
🔬 方法详解
问题定义:论文旨在解决陆地机器人在仅使用激光雷达数据的情况下进行自主导航的问题。现有基于强化学习的方法,特别是无模型方法,在处理高维激光雷达数据时面临样本效率低下的问题,并且难以直接从原始激光雷达数据中学习有效的导航策略。传统策略网络难以处理全分辨率激光雷达输入,导致需要简化观测,从而降低了空间感知能力和导航鲁棒性。
核心思路:论文的核心思路是利用世界模型来学习环境的动态特性,并结合变分自编码器来降低激光雷达数据的维度。通过学习一个能够预测环境状态的内部模型,智能体可以在模拟环境中进行策略优化,从而提高样本效率。使用MLP-VAE将高维激光雷达数据编码为低维潜在表示,可以有效降低计算复杂度,并提取关键的环境特征。
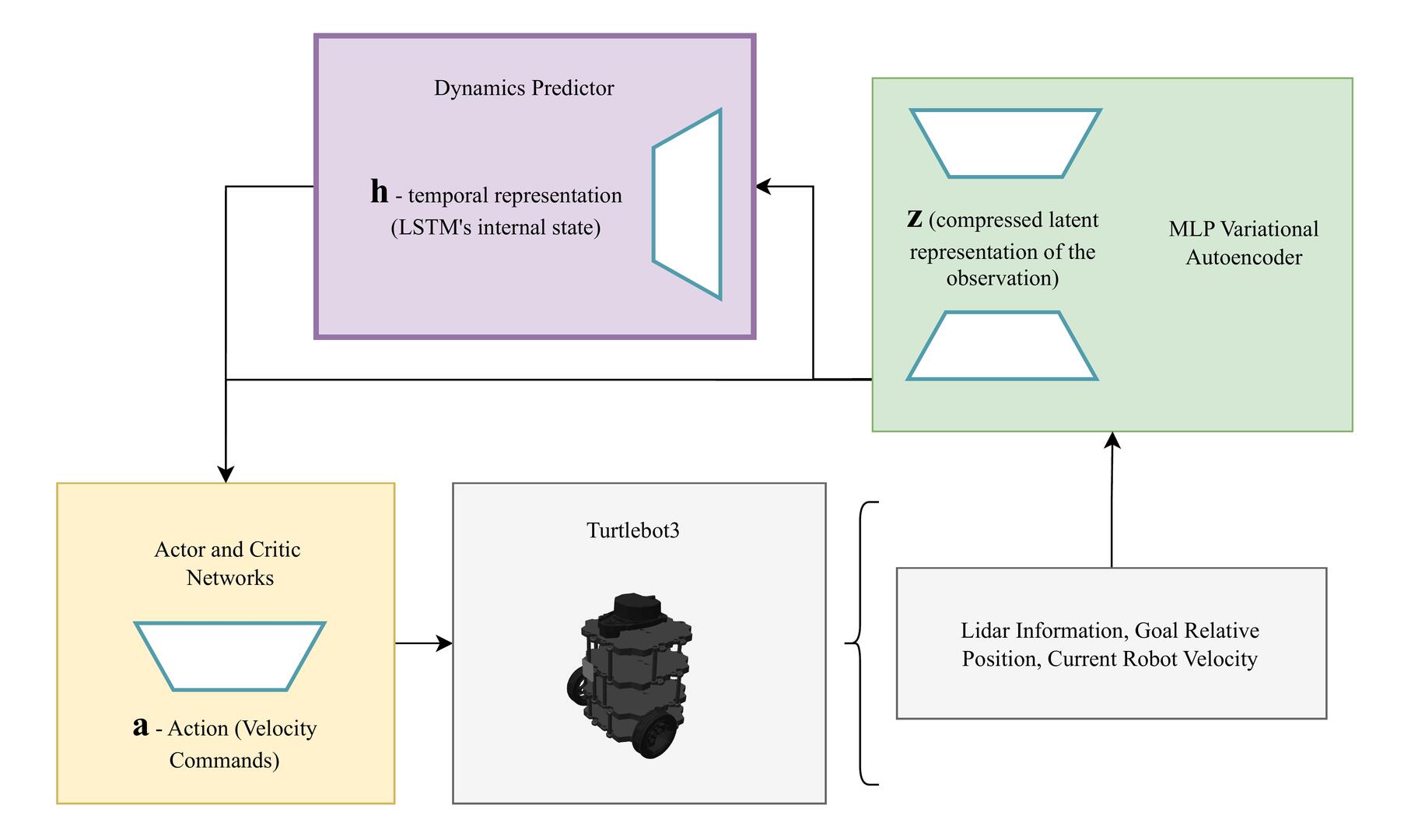
技术框架:整体框架基于DreamerV3算法,包含以下主要模块:1) 感知模块:使用MLP-VAE将激光雷达数据编码为潜在状态;2) 动态模块:学习潜在状态之间的转移概率,预测未来的状态;3) 奖励模块:预测智能体在当前状态下获得的奖励;4) 策略模块:基于世界模型学习到的知识,优化导航策略。智能体通过与环境交互,不断更新世界模型和策略网络。
关键创新:最重要的技术创新点在于将MLP-VAE集成到DreamerV3框架中,用于处理高维激光雷达数据。与直接使用原始激光雷达数据作为输入相比,使用潜在表示可以显著降低计算复杂度,并提高学习效率。此外,该方法利用世界模型进行策略优化,可以有效提高样本效率,并获得更鲁棒的导航策略。
关键设计:MLP-VAE的网络结构包括编码器和解码器,编码器将激光雷达数据映射到潜在空间,解码器从潜在空间重建激光雷达数据。损失函数包括重建损失和KL散度,用于约束潜在空间的分布。DreamerV3使用Actor-Critic框架进行策略优化,Actor网络输出动作,Critic网络评估状态的价值。具体的参数设置(如潜在空间的维度、学习率、折扣因子等)需要在实验中进行调整。
🖼️ 关键图片
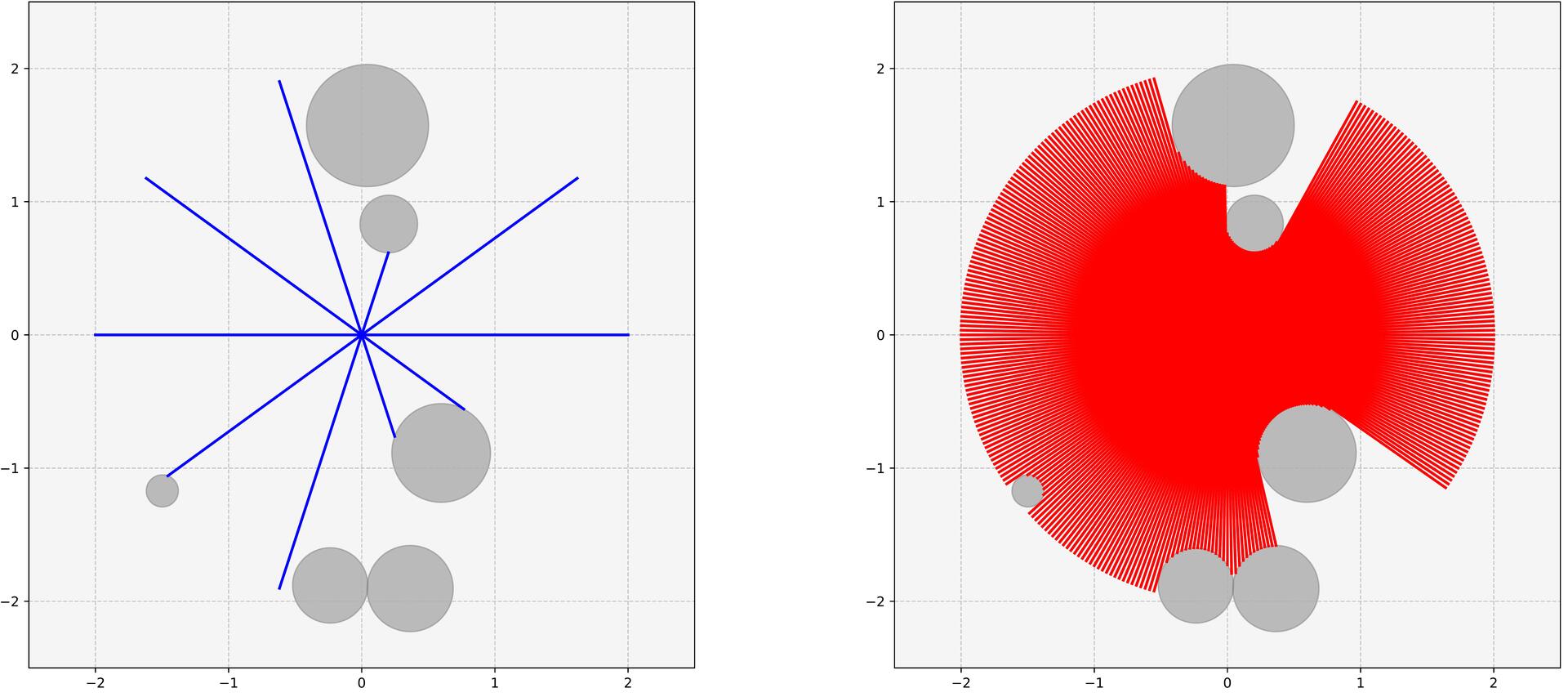
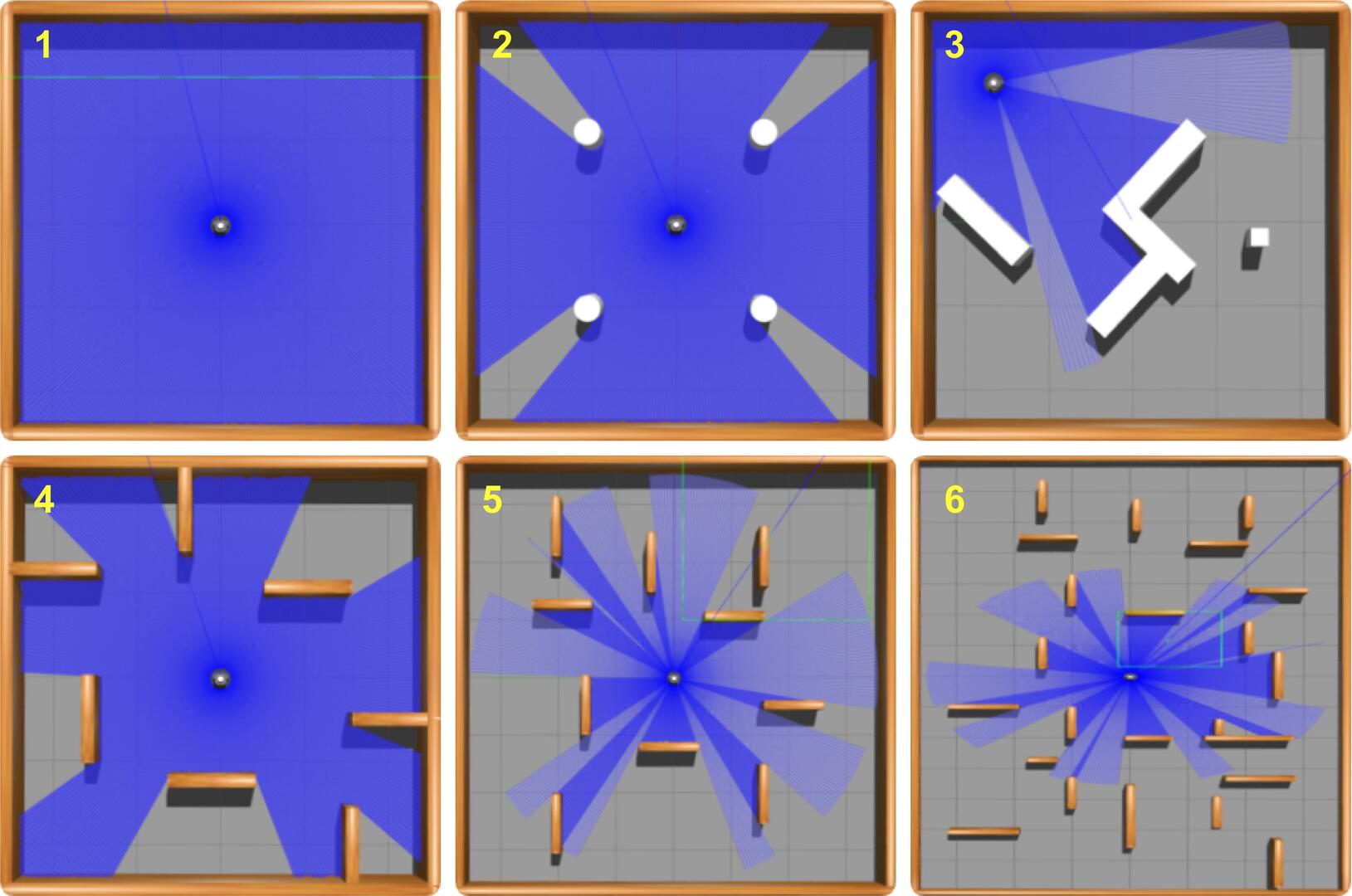
📊 实验亮点
实验结果表明,基于DreamerV3和MLP-VAE的导航方法在TurtleBot3模拟环境中取得了显著的性能提升。在使用完整激光雷达数据(360个读数)时,该方法在所有评估环境中都达到了100%的成功率,而无模型方法(如SAC、DDPG和TD3)的成功率则低于85%。这表明该方法能够更有效地利用高维激光雷达数据,并学习到更鲁棒的导航策略。此外,该方法还表现出更快的收敛速度,能够在更少的训练步骤内达到较高的性能。
🎯 应用场景
该研究成果可应用于各种需要自主导航的陆地机器人,例如:仓库机器人、巡检机器人、农业机器人和无人驾驶车辆。通过高效处理高维激光雷达数据,提升机器人在复杂环境中的导航能力,降低对环境先验知识的依赖,具有重要的实际应用价值和商业前景。未来可进一步扩展到其他类型的传感器数据,例如视觉数据和多传感器融合。
📄 摘要(原文)
Autonomous navigation of terrestrial robots using Reinforcement Learning (RL) from LIDAR observations remains challenging due to the high dimensionality of sensor data and the sample inefficiency of model-free approaches. Conventional policy networks struggle to process full-resolution LIDAR inputs, forcing prior works to rely on simplified observations that reduce spatial awareness and navigation robustness. This paper presents a novel model-based RL framework built on top of the DreamerV3 algorithm, integrating a Multi-Layer Perceptron Variational Autoencoder (MLP-VAE) within a world model to encode high-dimensional LIDAR readings into compact latent representations. These latent features, combined with a learned dynamics predictor, enable efficient imagination-based policy optimization. Experiments on simulated TurtleBot3 navigation tasks demonstrate that the proposed architecture achieves faster convergence and higher success rate compared to model-free baselines such as SAC, DDPG, and TD3. It is worth emphasizing that the DreamerV3-based agent attains a 100% success rate across all evaluated environments when using the full dataset of the Turtlebot3 LIDAR (360 readings), while model-free methods plateaued below 85%. These findings demonstrate that integrating predictive world models with learned latent representations enables more efficient and robust navigation from high-dimensional sensory data.