Multi-Agent Reinforcement Learning and Real-Time Decision-Making in Robotic Soccer for Virtual Environments
作者: Aya Taourirte, Md Sohag Mia
分类: cs.RO, cs.CV
发布日期: 2025-12-02
💡 一句话要点
提出基于分层强化学习和均值场理论的多智能体足球决策框架
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 多智能体强化学习 分层强化学习 均值场理论 机器人足球 实时决策
📋 核心要点
- 现有强化学习方法在机器人足球等复杂环境中,难以同时处理长期策略规划和即时动作执行,且在大规模智能体交互时面临维度灾难。
- 论文提出一种分层强化学习(HRL)框架,结合均值场理论,将复杂问题分解为高层策略和低层动作,并简化多智能体交互。
- 实验结果表明,该方法在机器人足球仿真中显著提升了进球数、控球率和传球准确率,验证了其鲁棒性和可扩展性。
📝 摘要(中文)
本文提出了一种统一的多智能体强化学习(MARL)框架,旨在解决机器人足球等动态对抗环境中实时决策、复杂协作和可扩展性问题。现有方法难以兼顾任务的多粒度(长期策略与即时动作)以及大规模智能体交互的复杂性。首先,我们使用近端策略优化(PPO)在客户端-服务器架构中建立实时动作调度的基线,PPO表现出优异的性能(平均进球4.32个,控球率82.9%)。其次,我们引入基于选项框架的分层强化学习(HRL)结构,将问题分解为高层轨迹规划层(建模为半马尔可夫决策过程)和低层动作执行层,从而改进全局策略(平均进球增加到5.26个)。最后,为了确保可扩展性,我们将均值场理论集成到HRL框架中,将多智能体交互简化为单个智能体与群体平均的交互。我们的均值场Actor-Critic方法实现了显著的性能提升(平均进球5.93个,控球率89.1%,传球准确率92.3%)并增强了训练稳定性。在Webots环境中进行的4v4比赛的大量仿真验证了我们的方法,证明了其在复杂多智能体领域中实现鲁棒、可扩展和协作行为的潜力。
🔬 方法详解
问题定义:论文旨在解决多智能体机器人足球环境中实时决策、复杂协作和可扩展性问题。现有强化学习方法难以处理任务的多粒度,即长期策略规划和即时动作执行之间的gap,并且在大规模智能体交互时面临维度灾难,导致训练不稳定和性能下降。
核心思路:论文的核心思路是将问题分解为两个层次:高层策略规划和低层动作执行。高层负责长期目标和策略选择,低层负责具体的动作执行。同时,利用均值场理论简化多智能体之间的复杂交互,将每个智能体与其他智能体的交互简化为与群体平均状态的交互。这样可以降低问题的复杂度,提高训练效率和稳定性。
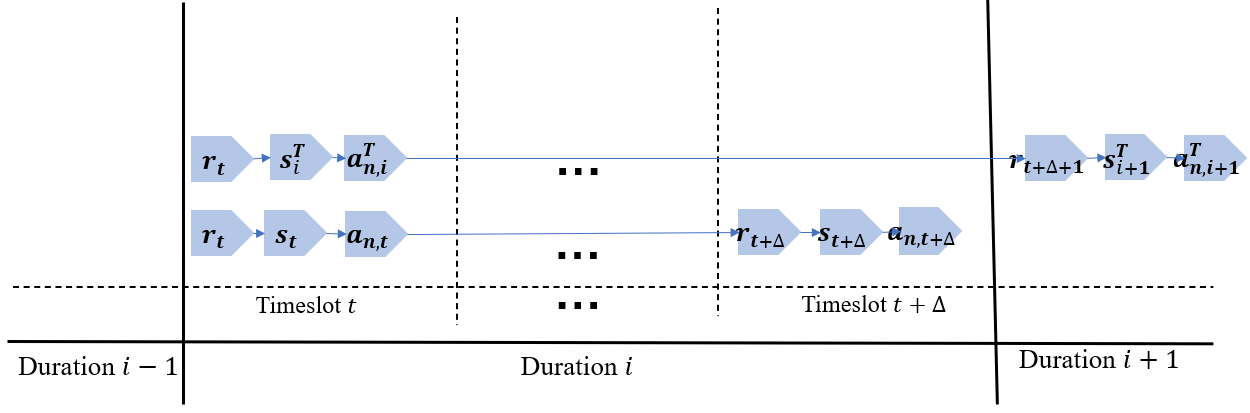
技术框架:整体框架是一个分层强化学习(HRL)结构,包含两个主要模块:高层策略网络和低层动作网络。高层策略网络基于半马尔可夫决策过程(SMDP)进行建模,负责选择合适的策略(选项)。低层动作网络负责执行选定的策略,生成具体的动作。均值场理论被集成到HRL框架中,用于简化多智能体交互。整体流程是:首先,高层策略网络根据当前状态选择一个策略(选项);然后,低层动作网络执行该策略,生成一系列动作;最后,环境反馈奖励信号,用于更新高层和低层网络。
关键创新:最重要的技术创新点是将分层强化学习和均值场理论相结合,用于解决多智能体环境中的复杂决策问题。与传统的单层强化学习方法相比,分层强化学习可以更好地处理长期依赖关系,提高学习效率。与传统的多智能体强化学习方法相比,均值场理论可以有效地降低问题的复杂度,提高训练稳定性和可扩展性。
关键设计:高层策略网络使用Actor-Critic结构,Actor网络负责选择策略,Critic网络负责评估策略的价值。低层动作网络也使用Actor-Critic结构,Actor网络负责生成动作,Critic网络负责评估动作的价值。损失函数包括策略梯度损失和价值函数损失。均值场项被添加到奖励函数中,用于鼓励智能体与群体平均状态保持一致。具体的网络结构和参数设置在论文中有详细描述(未知)。
🖼️ 关键图片

📊 实验亮点
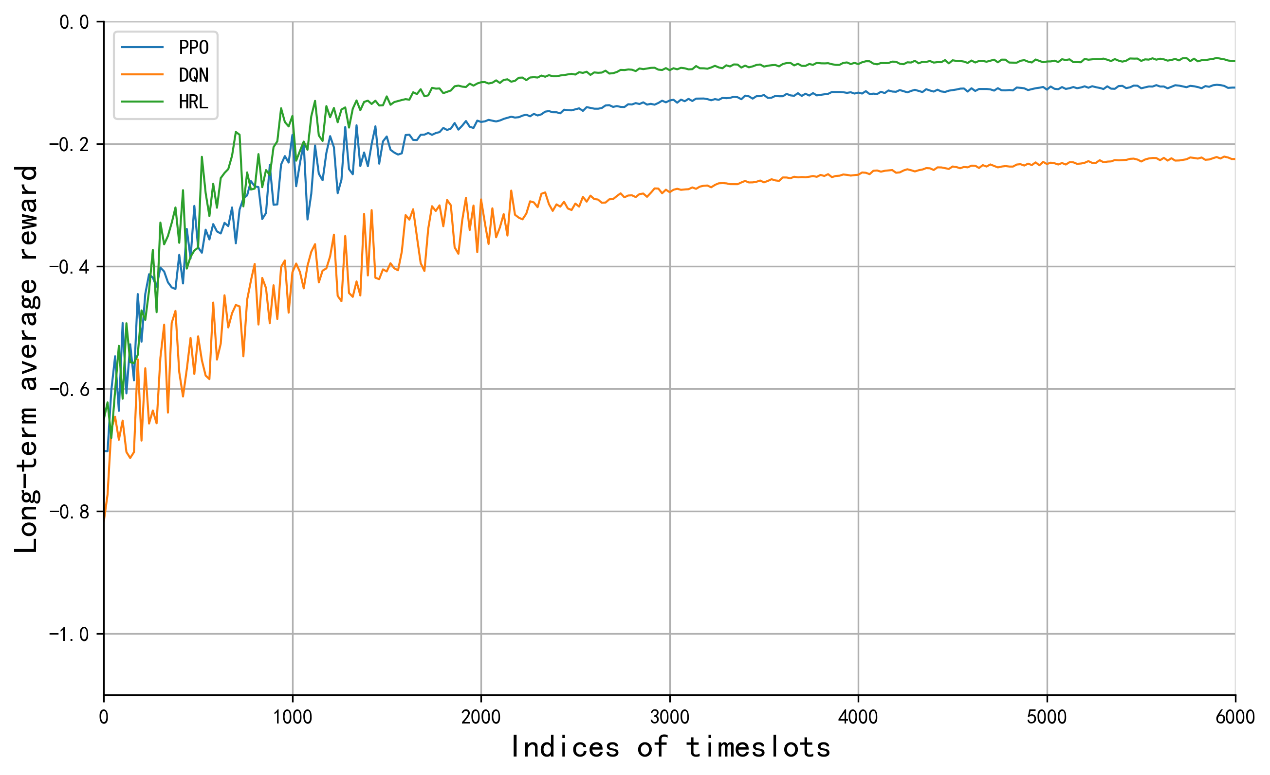
实验结果表明,该方法在4v4机器人足球仿真中取得了显著的性能提升。与基线PPO方法相比,平均进球数从4.32个提高到5.93个,控球率从82.9%提高到89.1%,传球准确率达到92.3%。这些数据表明,该方法能够有效地提高智能体的协作能力和决策水平。
🎯 应用场景
该研究成果可应用于各种多智能体协作和竞争场景,例如自动驾驶、机器人集群控制、资源分配、网络安全等。通过分层强化学习和均值场理论,可以有效地解决复杂环境中的决策问题,提高系统的鲁棒性、可扩展性和协作效率,具有重要的实际应用价值和未来发展潜力。
📄 摘要(原文)
The deployment of multi-agent systems in dynamic, adversarial environments like robotic soccer necessitates real-time decision-making, sophisticated cooperation, and scalable algorithms to avoid the curse of dimensionality. While Reinforcement Learning (RL) offers a promising framework, existing methods often struggle with the multi-granularity of tasks (long-term strategy vs. instant actions) and the complexity of large-scale agent interactions. This paper presents a unified Multi-Agent Reinforcement Learning (MARL) framework that addresses these challenges. First, we establish a baseline using Proximal Policy Optimization (PPO) within a client-server architecture for real-time action scheduling, with PPO demonstrating superior performance (4.32 avg. goals, 82.9% ball control). Second, we introduce a Hierarchical RL (HRL) structure based on the options framework to decompose the problem into a high-level trajectory planning layer (modeled as a Semi-Markov Decision Process) and a low-level action execution layer, improving global strategy (avg. goals increased to 5.26). Finally, to ensure scalability, we integrate mean-field theory into the HRL framework, simplifying many-agent interactions into a single agent vs. the population average. Our mean-field actor-critic method achieves a significant performance boost (5.93 avg. goals, 89.1% ball control, 92.3% passing accuracy) and enhanced training stability. Extensive simulations of 4v4 matches in the Webots environment validate our approach, demonstrating its potential for robust, scalable, and cooperative behavior in complex multi-agent domains.