VLA Models Are More Generalizable Than You Think: Revisiting Physical and Spatial Modeling
作者: Weiqi Li, Quande Zhang, Ruifeng Zhai, Liang Lin, Guangrun Wang
分类: cs.RO, cs.AI, cs.LG
发布日期: 2025-12-02
💡 一句话要点
针对VLA模型泛化性不足,提出轻量级视觉表征校准方法,显著提升视角泛化能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言动作模型 泛化能力 空间建模 特征自适应 机器人学习
📋 核心要点
- VLA模型在视角变化和视觉扰动下泛化能力差,主要原因是空间建模不对齐。
- 提出单样本自适应框架,通过轻量级可学习更新校准视觉表征,解决空间建模不对齐问题。
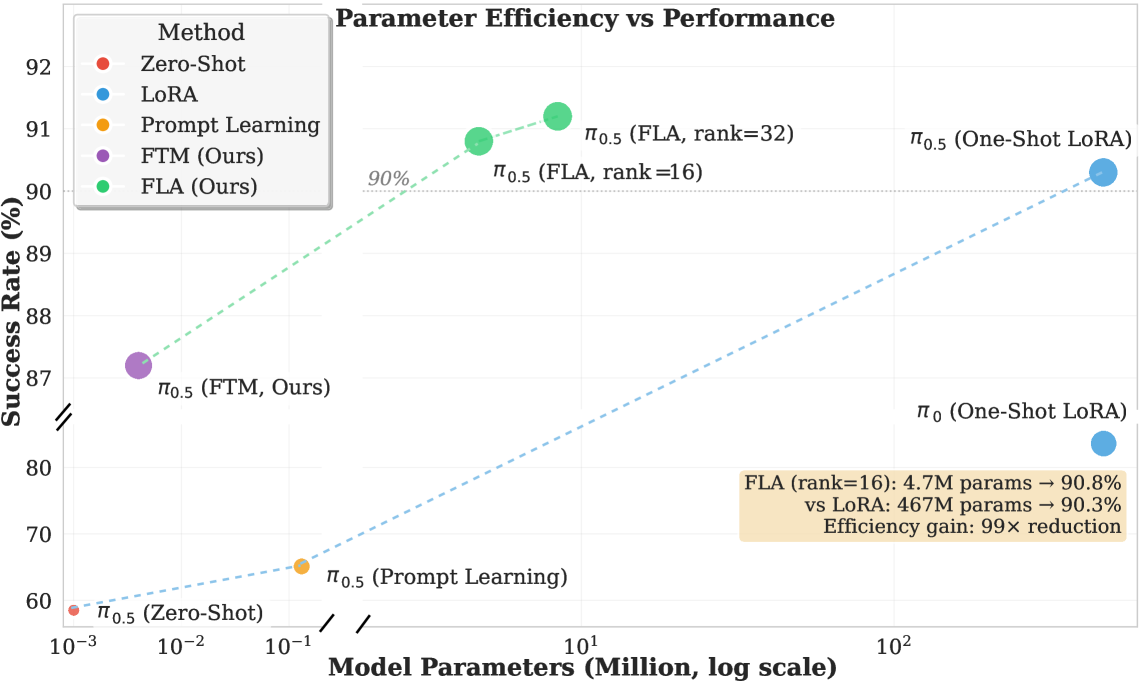
- FTM和FLA方法分别以极少参数量显著提升Libero数据集上的视角准确率,证明了VLA模型的鲁棒性潜力。
📝 摘要(中文)
视觉-语言-动作(VLA)模型在同分布数据上表现出色,但在新的相机视角和视觉扰动下性能急剧下降。本文研究表明,这种脆弱性主要源于空间建模中的不对齐,而非物理建模。为了解决这个问题,我们提出了一个单样本自适应框架,通过轻量级的可学习更新来重新校准视觉表征。我们的第一个方法,特征令牌调制(FTM),对视觉令牌应用全局仿射变换,仅用4K参数就将Libero视点准确率从48.5%提高到87.1%。在此基础上,特征线性自适应(FLA)引入了对ViT编码器的低秩更新,以4.7M参数实现了90.8%的成功率——以远低于LoRA规模的微调成本达到了相当的性能。总之,这些结果揭示了预训练VLA模型中大量未被利用的鲁棒性,并表明有针对性的、最小的视觉自适应足以恢复视点泛化能力。
🔬 方法详解
问题定义:VLA模型在特定分布的数据集上表现良好,但当面对新的相机视角或视觉扰动时,性能会显著下降。现有的VLA模型在空间建模方面存在不足,导致其对视角变化的泛化能力较差。这种泛化性问题限制了VLA模型在实际机器人应用中的部署。
核心思路:论文的核心思路是通过轻量级的自适应方法来校准VLA模型中的视觉表征,从而提高其对不同视角的泛化能力。作者认为,VLA模型的脆弱性主要源于空间建模的不对齐,因此通过调整视觉特征的表示方式,可以有效地提升模型的鲁棒性。
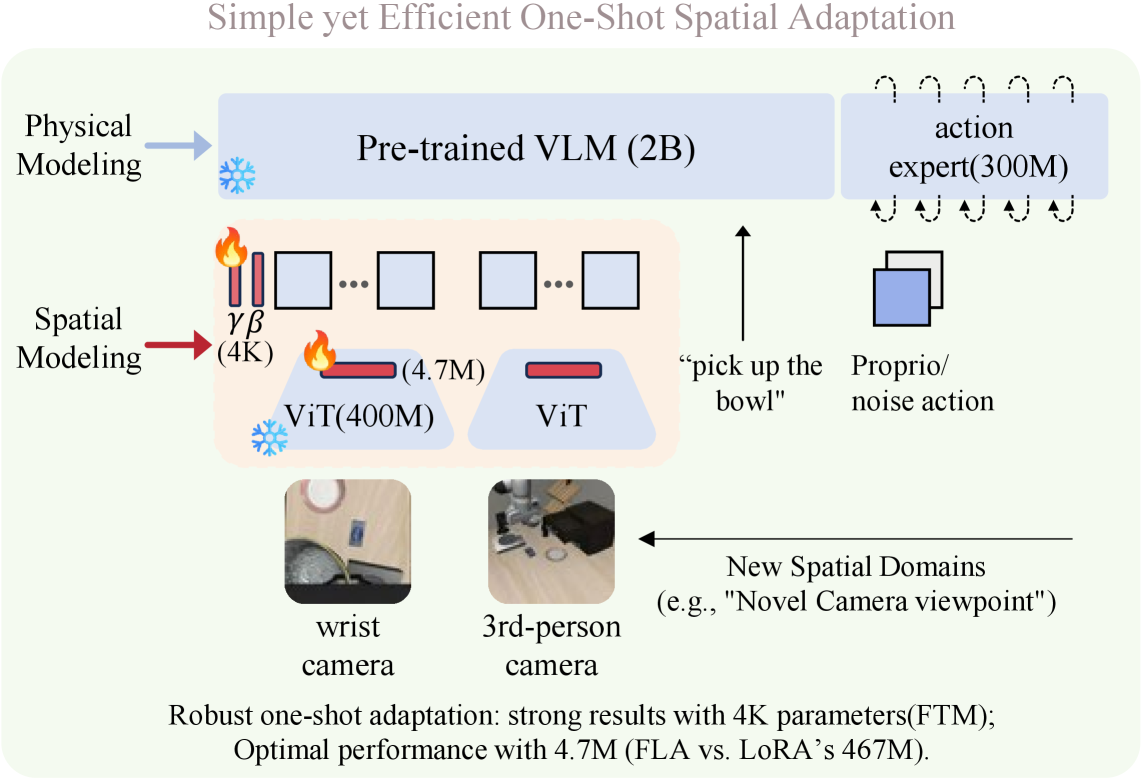
技术框架:该论文提出了一个单样本自适应框架,包含两种主要方法:特征令牌调制(FTM)和特征线性自适应(FLA)。FTM通过对视觉令牌应用全局仿射变换来调整特征表示。FLA则引入了对ViT编码器的低秩更新。这两种方法都旨在以最小的参数量实现对视觉表征的有效校准。
关键创新:该论文的关键创新在于发现了VLA模型泛化性不足的主要原因是空间建模的不对齐,并提出了轻量级的自适应方法来解决这个问题。与传统的微调方法相比,FTM和FLA只需要极少的参数,就能显著提升模型的泛化能力。这种方法在计算资源有限的场景下具有重要意义。
关键设计:FTM的关键设计是对视觉令牌应用全局仿射变换,通过学习仿射变换的参数来调整特征表示。FLA的关键设计是引入对ViT编码器的低秩更新,通过学习低秩矩阵来调整ViT的权重。这两种方法都采用了可学习的参数,并通过优化这些参数来最小化模型在目标任务上的损失函数。
🖼️ 关键图片

📊 实验亮点
实验结果表明,FTM方法仅使用4K参数就将Libero视点准确率从48.5%提高到87.1%。FLA方法使用4.7M参数实现了90.8%的成功率,与LoRA规模的微调相比,成本大大降低。这些结果证明了该方法在提高VLA模型泛化能力方面的有效性,并揭示了预训练VLA模型中未被充分利用的鲁棒性。
🎯 应用场景
该研究成果可应用于机器人导航、自动驾驶、增强现实等领域。通过提高VLA模型对不同视角的泛化能力,可以使机器人在复杂环境中更可靠地执行任务。例如,机器人可以在不同的光照条件和视角下准确识别物体,从而实现更智能的交互和操作。此外,该方法还可以降低模型部署的计算成本,使其更易于在资源受限的设备上运行。
📄 摘要(原文)
Vision-language-action (VLA) models achieve strong in-distribution performance but degrade sharply under novel camera viewpoints and visual perturbations. We show that this brittleness primarily arises from misalignment in Spatial Modeling, rather than Physical Modeling. To address this, we propose a one-shot adaptation framework that recalibrates visual representations through lightweight, learnable updates. Our first method, Feature Token Modulation (FTM), applies a global affine transformation to visual tokens and improves Libero viewpoint accuracy from 48.5% to 87.1% with only 4K parameters. Building on this, Feature Linear Adaptation (FLA) introduces low-rank updates to the ViT encoder, achieving 90.8% success with 4.7M parameters -- matching LoRA-scale finetuning at far lower cost. Together, these results reveal substantial untapped robustness in pretrained VLA models and demonstrate that targeted, minimal visual adaptation is sufficient to restore viewpoint generalization.