SwarmDiffusion: End-To-End Traversability-Guided Diffusion for Embodiment-Agnostic Navigation of Heterogeneous Robots
作者: Iana Zhura, Sausar Karaf, Faryal Batool, Nipun Dhananjaya Weerakkodi Mudalige, Valerii Serpiva, Ali Alridha Abdulkarim, Aleksey Fedoseev, Didar Seyidov, Hajira Amjad, Dzmitry Tsetserukou
分类: cs.RO
发布日期: 2025-12-02 (更新: 2025-12-08)
备注: This work has been submitted for publication and is currently under review
💡 一句话要点
SwarmDiffusion:端到端可通行性引导的扩散模型,用于异构机器人通用导航
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱三:空间感知与语义 (Perception & Semantics) 支柱七:动作重定向 (Motion Retargeting)
关键词: 机器人导航 扩散模型 可通行性估计 端到端学习 视觉语言模型 自主导航 轨迹生成 无监督学习
📋 核心要点
- 现有基于视觉语言模型(VLM)的导航方法依赖手工设计的提示,泛化性差,且仅输出可通行性地图,轨迹生成依赖外部规划器。
- SwarmDiffusion提出一种端到端扩散模型,从RGB图像联合预测可通行性与可行轨迹,无需人工提示或规划器生成的路径。
- 实验表明,该方法在室内环境和不同机器人形态上实现了高导航成功率和快速推理,并能快速适应新机器人和未见环境。
📝 摘要(中文)
视觉可通行性估计对于自主导航至关重要,但现有基于VLM的方法依赖于手工设计的提示,在不同机器人形态上的泛化能力较差,并且仅输出可通行性地图,将轨迹生成留给缓慢的外部规划器。我们提出了SwarmDiffusion,一个轻量级的端到端扩散模型,它从单个RGB图像中联合预测可通行性并生成可行的轨迹。为了消除对带注释或规划器生成的路径的需求,我们引入了一种基于随机航路点采样、贝塞尔平滑和正则化的无规划器轨迹构建流程,该正则化强制执行连通性、安全性、方向性和路径稀疏性。这使得无需演示即可学习稳定的运动先验。SwarmDiffusion利用VLM衍生的监督,无需提示工程,并以紧凑的机器人形态状态为扩散过程提供条件,从而产生物理上一致的、可通行的路径,这些路径可以在不同的机器人平台上转移。在室内环境和两种形态(四足和空中)中,该方法实现了80-100%的导航成功率和0.09秒的推理速度,并且仅使用500个额外的视觉样本即可适应新的机器人。它在模拟和真实世界试验中可靠地推广到未见过的环境,为统一的可通行性推理和轨迹生成提供了一种可扩展的、无提示的方法。
🔬 方法详解
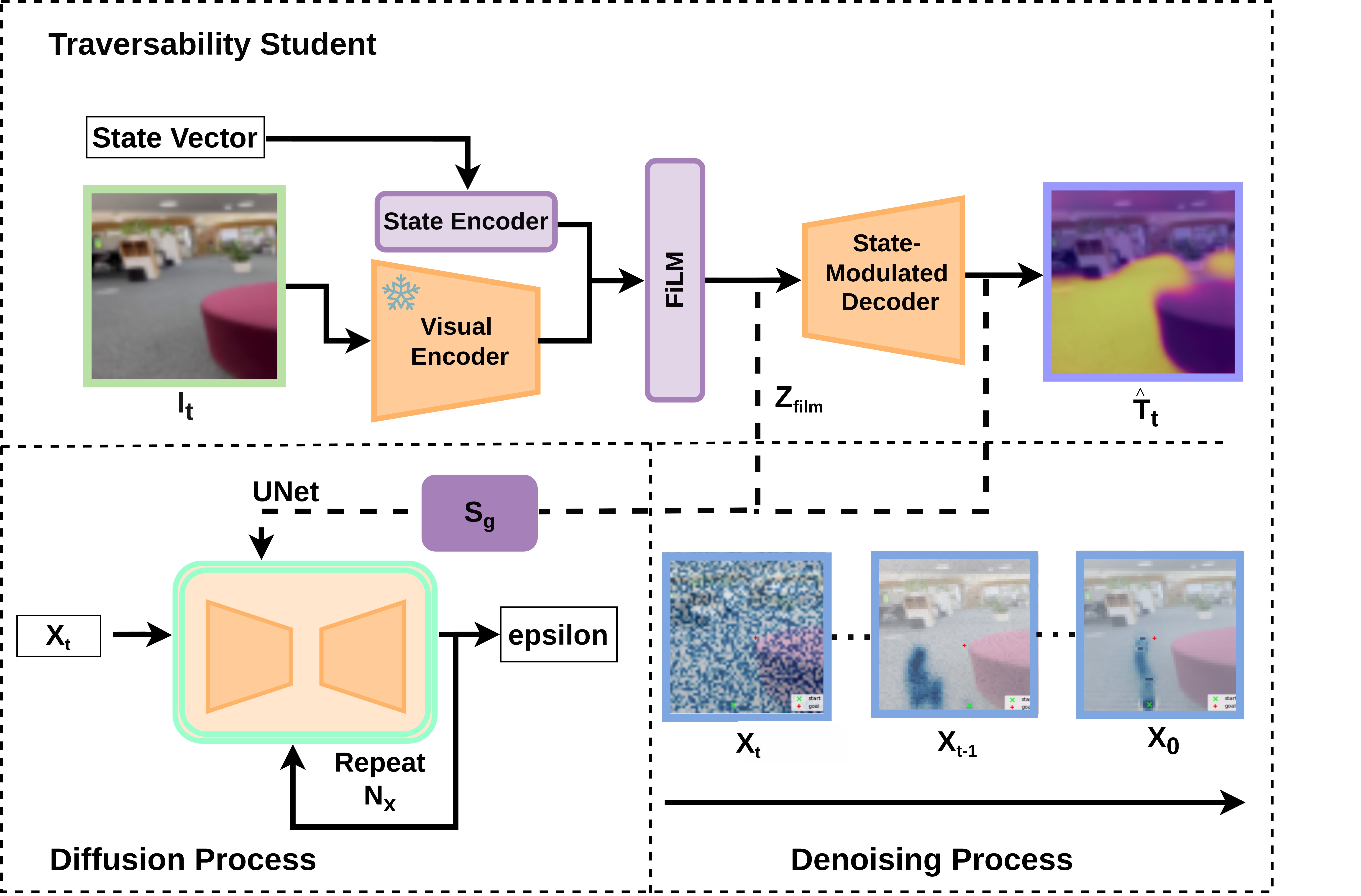
问题定义:现有基于视觉语言模型的导航方法存在三个主要痛点:一是依赖手工设计的提示,需要大量人工干预;二是泛化能力差,难以适应不同的机器人形态;三是仅输出可通行性地图,需要额外的规划器进行轨迹生成,效率较低。因此,需要一种能够自动、通用、高效地进行可通行性推理和轨迹生成的导航方法。
核心思路:SwarmDiffusion的核心思路是利用扩散模型直接从RGB图像中生成可行的轨迹,同时预测可通行性。通过引入无规划器的轨迹构建流程,避免了对带注释数据的依赖,并利用VLM衍生的监督信号,无需人工提示。此外,通过将机器人形态作为扩散过程的条件,实现了跨不同机器人平台的泛化能力。
技术框架:SwarmDiffusion的整体框架包括以下几个主要模块:1) 图像输入模块,接收RGB图像作为输入;2) 可通行性与轨迹联合扩散模型,该模型以RGB图像和机器人形态为条件,生成可通行性地图和可行轨迹;3) 无规划器的轨迹构建流程,用于生成训练数据,包括随机航路点采样、贝塞尔平滑和正则化;4) VLM监督模块,利用VLM生成的可通行性信息作为监督信号。
关键创新:SwarmDiffusion的关键创新在于:1) 端到端的轨迹生成,直接从RGB图像生成可行轨迹,无需额外的规划器;2) 无提示的VLM监督,利用VLM生成的可通行性信息,无需人工设计提示;3) 基于机器人形态的条件扩散,实现了跨不同机器人平台的泛化能力;4) 无规划器的轨迹构建流程,避免了对带注释数据的依赖。
关键设计:在轨迹构建流程中,采用了随机航路点采样和贝塞尔平滑,以生成初始轨迹。为了保证轨迹的质量,引入了正则化项,包括连通性、安全性、方向性和路径稀疏性。扩散模型采用U-Net结构,以RGB图像和机器人形态作为输入,预测可通行性地图和轨迹。损失函数包括可通行性损失和轨迹损失,其中可通行性损失采用交叉熵损失,轨迹损失采用L1损失。
🖼️ 关键图片


📊 实验亮点
SwarmDiffusion在室内环境和两种机器人形态(四足和空中)上取得了显著的实验结果。导航成功率达到80-100%,推理速度为0.09秒。仅使用500个额外的视觉样本即可适应新的机器人。在模拟和真实世界试验中,该方法能够可靠地推广到未见过的环境,证明了其良好的泛化能力。
🎯 应用场景
SwarmDiffusion具有广泛的应用前景,可用于各种机器人的自主导航,包括无人车、无人机、四足机器人等。该方法能够提高机器人在复杂环境中的导航能力,降低对人工干预的依赖,并加速机器人的部署和应用。未来,该研究可以进一步扩展到多机器人协同导航、动态环境导航等领域。
📄 摘要(原文)
Visual traversability estimation is critical for autonomous navigation, but existing VLM-based methods rely on hand-crafted prompts, generalize poorly across embodiments, and output only traversability maps, leaving trajectory generation to slow external planners. We propose SwarmDiffusion, a lightweight end-to-end diffusion model that jointly predicts traversability and generates a feasible trajectory from a single RGB image. To remove the need for annotated or planner-produced paths, we introduce a planner-free trajectory construction pipeline based on randomized waypoint sampling, Bezier smoothing, and regularization enforcing connectivity, safety, directionality, and path thinness. This enables learning stable motion priors without demonstrations. SwarmDiffusion leverages VLM-derived supervision without prompt engineering and conditions the diffusion process on a compact embodiment state, producing physically consistent, traversable paths that transfer across different robot platforms. Across indoor environments and two embodiments (quadruped and aerial), the method achieves 80-100% navigation success and 0.09s inference, and adapts to a new robot using only-500 additional visual samples. It generalizes reliably to unseen environments in simulation and real-world trials, offering a scalable, prompt-free approach to unified traversability reasoning and trajectory generation.