Diagnose, Correct, and Learn from Manipulation Failures via Visual Symbols
作者: Xianchao Zeng, Xinyu Zhou, Youcheng Li, Jiayou Shi, Tianle Li, Liangming Chen, Lei Ren, Yong-Lu Li
分类: cs.RO, cs.CV
发布日期: 2025-12-02 (更新: 2025-12-03)
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
ViFailback:利用视觉符号诊断、纠正和学习机器人操作失败
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人操作 失败诊断 视觉符号 视觉问答 视觉-语言模型
📋 核心要点
- 现有VLA模型在机器人操作失败诊断和从失败中学习方面存在不足,且现有数据集泛化性有限。
- ViFailback框架利用视觉符号增强标注效率,诊断失败并提供文本和视觉纠正指导。
- ViFailback-8B VLM在ViFailback-Bench上表现出色,并能生成视觉符号指导纠正动作,辅助VLA模型从失败中恢复。
📝 摘要(中文)
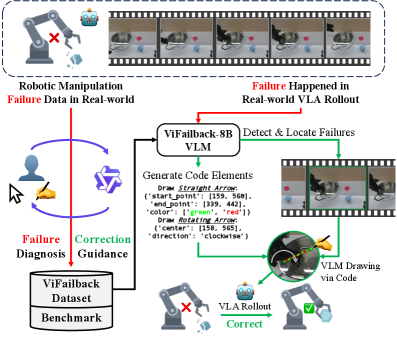
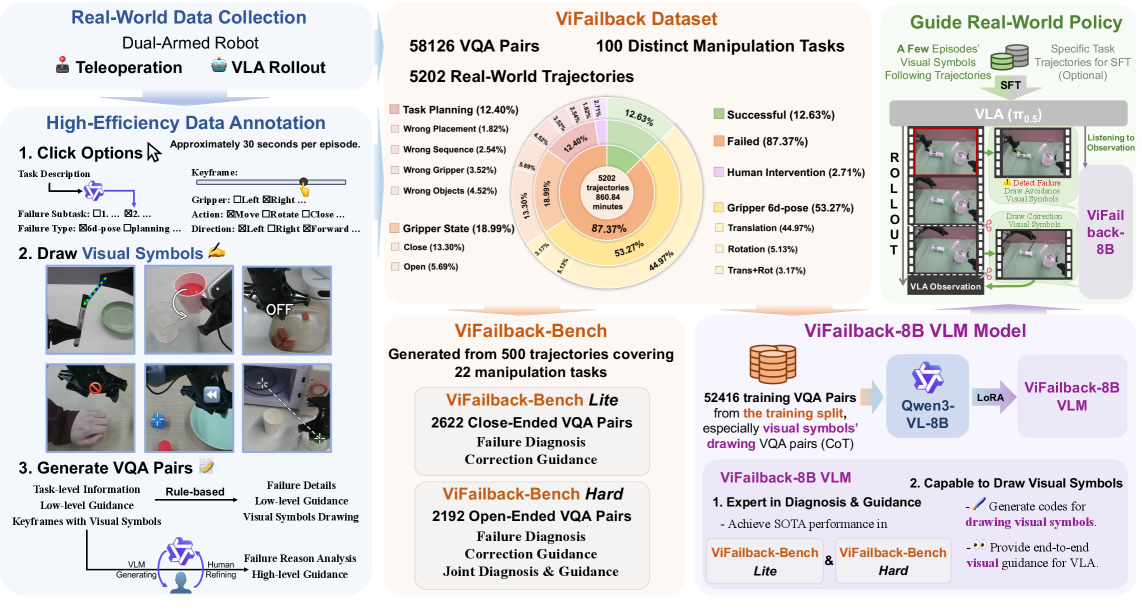
视觉-语言-动作(VLA)模型在机器人操作方面取得了显著进展,但在失败诊断和从失败中学习方面仍存在局限性。此外,现有的失败数据集大多是在模拟环境中通过编程方式生成的,限制了其在现实世界中的泛化能力。为此,我们提出了ViFailback框架,旨在诊断机器人操作失败,并提供文本和视觉纠正指导。我们的框架利用显式的视觉符号来提高标注效率。我们还发布了ViFailback数据集,这是一个大规模的集合,包含58,126个视觉问答(VQA)对以及5,202条对应的真实世界操作轨迹。基于该数据集,我们建立了ViFailback-Bench,一个包含11个细粒度VQA任务的基准,旨在评估视觉-语言模型(VLM)的失败诊断和纠正能力,包括用于封闭式评估的ViFailback-Bench Lite和用于开放式评估的ViFailback-Bench Hard。为了证明我们框架的有效性,我们构建了ViFailback-8B VLM,它不仅在ViFailback-Bench上实现了显著的整体性能提升,还生成了用于纠正动作指导的视觉符号。最后,通过将ViFailback-8B与VLA模型集成,我们进行了真实的机器人实验,证明了其在帮助VLA模型从失败中恢复的能力。
🔬 方法详解
问题定义:现有VLA模型在机器人操作任务中,对于失败情况的诊断和纠正能力不足。现有的失败数据集主要依赖于模拟环境生成,与真实世界的复杂性和多样性存在差距,导致模型在真实场景下的泛化能力受限。因此,如何构建更贴近现实、更具泛化能力的失败诊断和纠正框架,是本文要解决的核心问题。
核心思路:本文的核心思路是利用视觉符号来增强机器人操作失败的诊断和纠正能力。通过引入显式的视觉符号,可以更清晰地表达纠正动作的指导信息,提高标注效率,并使模型能够更好地理解和执行纠正动作。这种方法旨在弥合模拟数据与真实世界数据之间的差距,提升模型在真实场景下的鲁棒性和泛化能力。
技术框架:ViFailback框架主要包含以下几个关键模块:1) 数据收集与标注:收集真实世界机器人操作轨迹,并利用视觉符号进行标注,构建大规模的ViFailback数据集。2) VQA任务构建:基于ViFailback数据集,构建包含11个细粒度VQA任务的ViFailback-Bench,用于评估模型的失败诊断和纠正能力。3) VLM模型训练:训练ViFailback-8B VLM模型,使其能够根据视觉输入和问题,生成文本和视觉纠正指导。4) 机器人实验:将ViFailback-8B与VLA模型集成,进行真实机器人实验,验证其在帮助VLA模型从失败中恢复的能力。
关键创新:本文最重要的技术创新点在于引入了视觉符号来增强机器人操作失败的诊断和纠正能力。与传统的文本指导相比,视觉符号能够更直观、更清晰地表达纠正动作的指导信息,提高标注效率,并使模型能够更好地理解和执行纠正动作。此外,本文还构建了大规模的ViFailback数据集和基准,为该领域的研究提供了有力支持。
关键设计:ViFailback-8B VLM模型的具体结构和参数设置未知,但可以推测其可能采用了Transformer架构,并针对VQA任务进行了优化。数据集的构建过程中,视觉符号的设计和标注策略是关键,需要保证符号的清晰、易懂和一致性。损失函数的设计可能包括交叉熵损失、对比损失等,以鼓励模型学习视觉符号与纠正动作之间的对应关系。
🖼️ 关键图片

📊 实验亮点
ViFailback-8B VLM在ViFailback-Bench上取得了显著的性能提升,证明了该框架的有效性。此外,通过将ViFailback-8B与VLA模型集成,并在真实机器人实验中验证了其在帮助VLA模型从失败中恢复的能力。具体的性能数据和提升幅度在论文中未明确给出,但整体实验结果表明该方法具有较强的实用价值。
🎯 应用场景
该研究成果可应用于各种机器人操作任务,例如工业自动化、家庭服务机器人、医疗机器人等。通过提高机器人对操作失败的诊断和纠正能力,可以显著提升机器人的自主性和可靠性,降低人工干预的需求,从而提高生产效率和服务质量。未来,该技术有望进一步发展,实现更智能、更灵活的机器人操作。
📄 摘要(原文)
Vision-Language-Action (VLA) models have recently achieved remarkable progress in robotic manipulation, yet they remain limited in failure diagnosis and learning from failures. Additionally, existing failure datasets are mostly generated programmatically in simulation, which limits their generalization to the real world. In light of these, we introduce ViFailback, a framework designed to diagnose robotic manipulation failures and provide both textual and visual correction guidance. Our framework utilizes explicit visual symbols to enhance annotation efficiency. We further release the ViFailback dataset, a large-scale collection of 58,126 Visual Question Answering (VQA) pairs along with their corresponding 5,202 real-world manipulation trajectories. Based on the dataset, we establish ViFailback-Bench, a benchmark of 11 fine-grained VQA tasks designed to assess the failure diagnosis and correction abilities of Vision-Language Models (VLMs), featuring ViFailback-Bench Lite for closed-ended and ViFailback-Bench Hard for open-ended evaluation. To demonstrate the effectiveness of our framework, we built the ViFailback-8B VLM, which not only achieves significant overall performance improvement on ViFailback-Bench but also generates visual symbols for corrective action guidance. Finally, by integrating ViFailback-8B with a VLA model, we conduct real-world robotic experiments demonstrating its ability to assist the VLA model in recovering from failures. Project Website: https://x1nyuzhou.github.io/vifailback.github.io/