ManualVLA: A Unified VLA Model for Chain-of-Thought Manual Generation and Robotic Manipulation
作者: Chenyang Gu, Jiaming Liu, Hao Chen, Runzhong Huang, Qingpo Wuwu, Zhuoyang Liu, Xiaoqi Li, Ying Li, Renrui Zhang, Peng Jia, Pheng-Ann Heng, Shanghang Zhang
分类: cs.RO
发布日期: 2025-12-01
💡 一句话要点
提出ManualVLA,用于生成式操作手册和机器人操作,提升长时程任务性能。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言-动作模型 机器人操作 长时程任务 操作手册生成 链式思考 3D高斯溅射
📋 核心要点
- 现有VLA模型在长时程机器人任务中,难以有效协调高层规划和精确操作,导致任务成功率受限。
- ManualVLA通过生成包含图像、位置提示和文本指令的中间操作手册,实现从结果到过程的推理。
- 实验结果表明,ManualVLA在乐高组装和物体重排任务中,显著优于现有方法,成功率提升32%。
📝 摘要(中文)
视觉-语言-动作(VLA)模型在机器人场景理解和操作中展现了强大的泛化能力。然而,在需要明确目标状态的长时程任务中,如乐高组装或物体重排,现有VLA模型在高层规划与精确操作的协调方面仍面临挑战。因此,本文旨在赋予VLA模型从“结果”推断“过程”的能力,将目标状态转化为可执行的步骤。本文提出了ManualVLA,一个基于混合Transformer(MoT)架构的统一VLA框架,实现了多模态操作手册生成和动作执行之间的连贯协作。与直接将感官输入映射到动作的先前VLA模型不同,ManualVLA首先配备了一个规划专家,生成包含图像、位置提示和文本指令的中间操作手册。在此基础上,设计了操作手册链式思考(ManualCoT)推理过程,将其输入到动作专家,其中每个操作手册步骤提供显式控制条件,而其潜在表示为精确操作提供隐式指导。为了减轻数据收集的负担,开发了一个基于3D高斯溅射的高保真数字孪生工具包,自动生成用于训练规划专家的操作手册数据。ManualVLA展示了强大的真实世界性能,在乐高组装和物体重排任务中,平均成功率比之前的分层SOTA基线高32%。
🔬 方法详解
问题定义:现有VLA模型在处理需要明确目标状态的长时程机器人任务(如乐高组装、物体重排)时,难以将高层规划与精确操作有效结合。痛点在于模型难以从最终目标状态推断出完成任务所需的中间步骤和操作序列,导致任务成功率较低。
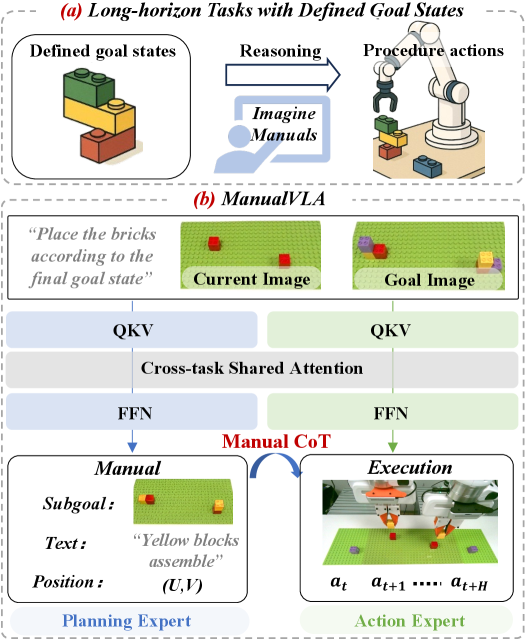
核心思路:ManualVLA的核心思路是引入一个中间层——操作手册(Manual),将目标状态分解为一系列易于理解和执行的步骤。通过让模型首先生成操作手册,然后再根据操作手册执行动作,从而实现从“结果”到“过程”的推理。这种分解策略降低了任务的复杂性,使得模型更容易学习和执行长时程任务。
技术框架:ManualVLA的整体架构基于混合Transformer(MoT),包含两个主要模块:规划专家(Planning Expert)和动作专家(Action Expert)。规划专家负责根据输入的目标状态生成操作手册,操作手册包含图像、位置提示和文本指令等多模态信息。动作专家则根据规划专家生成的操作手册,逐步执行相应的动作。ManualCoT推理过程将操作手册逐步输入动作专家,实现显式控制和隐式指导。
关键创新:ManualVLA的关键创新在于引入了操作手册作为中间表示,并设计了ManualCoT推理过程。与直接将视觉输入映射到动作的传统VLA模型不同,ManualVLA首先生成人类可理解的操作手册,然后利用操作手册指导动作执行。这种方法使得模型能够更好地理解任务目标,并生成更精确的动作序列。此外,利用3D高斯溅射技术构建数字孪生环境,自动生成操作手册数据,缓解了数据收集的难题。
关键设计:ManualVLA的关键设计包括:1) 混合Transformer(MoT)架构,用于处理多模态输入和生成操作手册;2) ManualCoT推理过程,逐步将操作手册输入动作专家,实现显式控制和隐式指导;3) 基于3D高斯溅射的数字孪生工具包,用于自动生成操作手册数据。具体参数设置和损失函数等细节在论文中有详细描述(未知)。
🖼️ 关键图片


📊 实验亮点
ManualVLA在乐高组装和物体重排任务中取得了显著的性能提升。实验结果表明,ManualVLA的平均成功率比之前的分层SOTA基线高32%。这表明ManualVLA能够有效地协调高层规划和精确操作,从而提高长时程任务的成功率。
🎯 应用场景
ManualVLA具有广泛的应用前景,可应用于自动化装配、物体重排、家庭服务机器人等领域。通过生成详细的操作手册,机器人可以更好地理解任务目标并执行复杂的长时程任务。该研究有助于提升机器人的智能化水平,使其能够更好地服务于人类。
📄 摘要(原文)
Vision-Language-Action (VLA) models have recently emerged, demonstrating strong generalization in robotic scene understanding and manipulation. However, when confronted with long-horizon tasks that require defined goal states, such as LEGO assembly or object rearrangement, existing VLA models still face challenges in coordinating high-level planning with precise manipulation. Therefore, we aim to endow a VLA model with the capability to infer the "how" process from the "what" outcomes, transforming goal states into executable procedures. In this paper, we introduce ManualVLA, a unified VLA framework built upon a Mixture-of-Transformers (MoT) architecture, enabling coherent collaboration between multimodal manual generation and action execution. Unlike prior VLA models that directly map sensory inputs to actions, we first equip ManualVLA with a planning expert that generates intermediate manuals consisting of images, position prompts, and textual instructions. Building upon these multimodal manuals, we design a Manual Chain-of-Thought (ManualCoT) reasoning process that feeds them into the action expert, where each manual step provides explicit control conditions, while its latent representation offers implicit guidance for accurate manipulation. To alleviate the burden of data collection, we develop a high-fidelity digital-twin toolkit based on 3D Gaussian Splatting, which automatically generates manual data for planning expert training. ManualVLA demonstrates strong real-world performance, achieving an average success rate 32% higher than the previous hierarchical SOTA baseline on LEGO assembly and object rearrangement tasks.