Guardian: Detecting Robotic Planning and Execution Errors with Vision-Language Models
作者: Paul Pacaud, Ricardo Garcia, Shizhe Chen, Cordelia Schmid
分类: cs.RO, cs.CV
发布日期: 2025-12-01 (更新: 2025-12-02)
备注: Code, Data, and Models available at https://www.di.ens.fr/willow/research/guardian/. The paper contains 8 pages, 9 figures, 6 tables
💡 一句话要点
提出自动化机器人故障合成方法以提升故障检测能力
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 机器人故障检测 视觉-语言模型 故障合成 多视角图像 任务成功率提升
📋 核心要点
- 现有的视觉-语言模型在故障检测方面的准确性和泛化能力受到故障数据稀缺的限制。
- 提出了一种自动化故障合成方法,通过扰动成功轨迹生成多样的故障数据,以丰富训练集。
- Guardian模型在新构建的基准上表现优异,并在实际机器人操作中提升了任务成功率。
📝 摘要(中文)
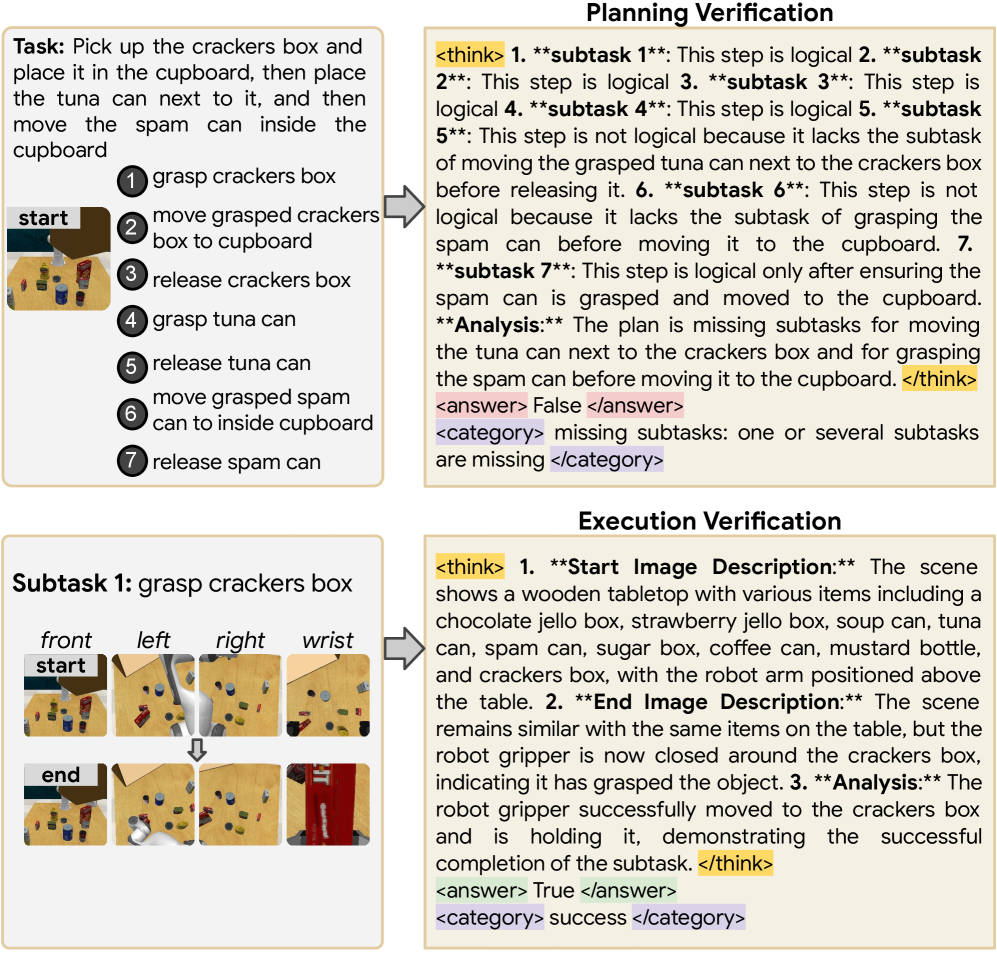
稳健的机器人操作需要可靠的故障检测与恢复。尽管当前的视觉-语言模型(VLMs)展现出潜力,但由于故障数据稀缺,其准确性和泛化能力受到限制。为了解决这一数据缺口,本文提出了一种自动化机器人故障合成方法,通过程序性扰动成功轨迹生成多样的规划和执行故障。该方法不仅生成二元分类标签,还提供细粒度的故障类别和逐步推理轨迹。我们构建了三个新的故障检测基准,显著扩展了现有故障数据集的多样性和规模。训练的Guardian模型在现有和新引入的基准上均取得了最先进的性能,并有效提升了任务成功率。
🔬 方法详解
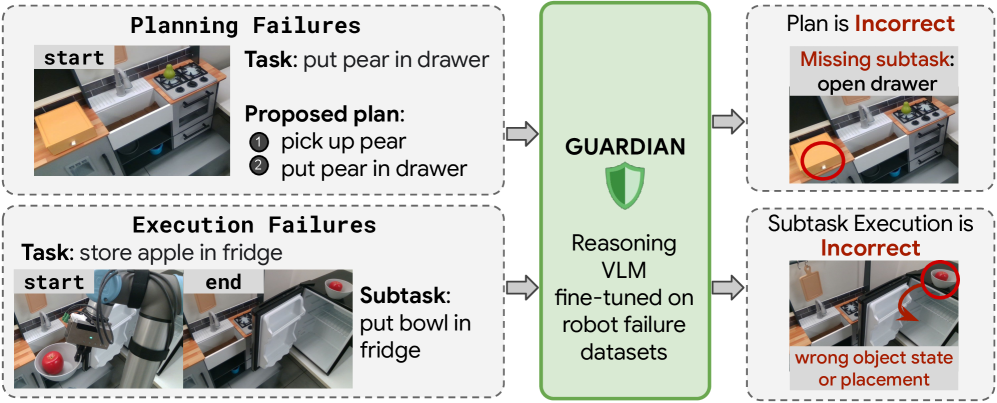
问题定义:本文旨在解决机器人操作中故障检测的不足,现有方法因缺乏足够的故障数据而难以实现高准确性和泛化能力。
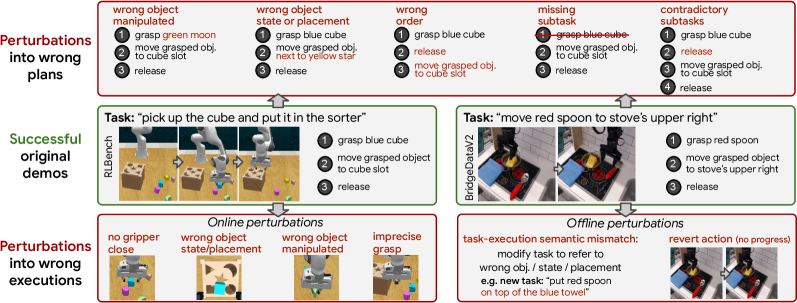
核心思路:提出了一种自动化故障合成方法,通过对成功轨迹进行程序性扰动,生成多样的规划和执行故障,从而丰富训练数据。
技术框架:整体架构包括故障合成模块、数据标注模块和模型训练模块。故障合成模块负责生成多样的故障数据,数据标注模块提供细粒度的故障类别和推理轨迹,模型训练模块则利用生成的数据训练Guardian模型。
关键创新:最重要的创新在于自动化故障合成方法的提出,该方法通过扰动成功轨迹生成多样的故障数据,与现有方法相比,显著提升了数据的多样性和规模。
关键设计:在模型训练中,采用了多视角图像输入以增强故障推理能力,损失函数设计上考虑了分类准确性和推理过程的细致性,确保模型在不同场景下的鲁棒性。
🖼️ 关键图片
📊 实验亮点
Guardian模型在新构建的RLBench-Fail、BridgeDataV2-Fail和UR5-Fail基准上表现出色,取得了最先进的性能,并在实际机器人操作中提升了任务成功率,显示出生成故障数据的显著影响。
🎯 应用场景
该研究的潜在应用领域包括工业机器人、服务机器人和自主移动机器人等,能够有效提升机器人在复杂环境中的故障检测与恢复能力,具有重要的实际价值和广泛的应用前景。
📄 摘要(原文)
Robust robotic manipulation requires reliable failure detection and recovery. Although current Vision-Language Models (VLMs) show promise, their accuracy and generalization are limited by the scarcity of failure data. To address this data gap, we propose an automatic robot failure synthesis approach that procedurally perturbs successful trajectories to generate diverse planning and execution failures. This method produces not only binary classification labels but also fine-grained failure categories and step-by-step reasoning traces in both simulation and the real world. With it, we construct three new failure detection benchmarks: RLBench-Fail, BridgeDataV2-Fail, and UR5-Fail, substantially expanding the diversity and scale of existing failure datasets. We then train Guardian, a VLM with multi-view images for detailed failure reasoning and detection. Guardian achieves state-of-the-art performance on both existing and newly introduced benchmarks. It also effectively improves task success rates when integrated into a state-of-the-art manipulation system in simulation and real robots, demonstrating the impact of our generated failure data. Code, Data, and Models available at https://www.di.ens.fr/willow/research/guardian/.