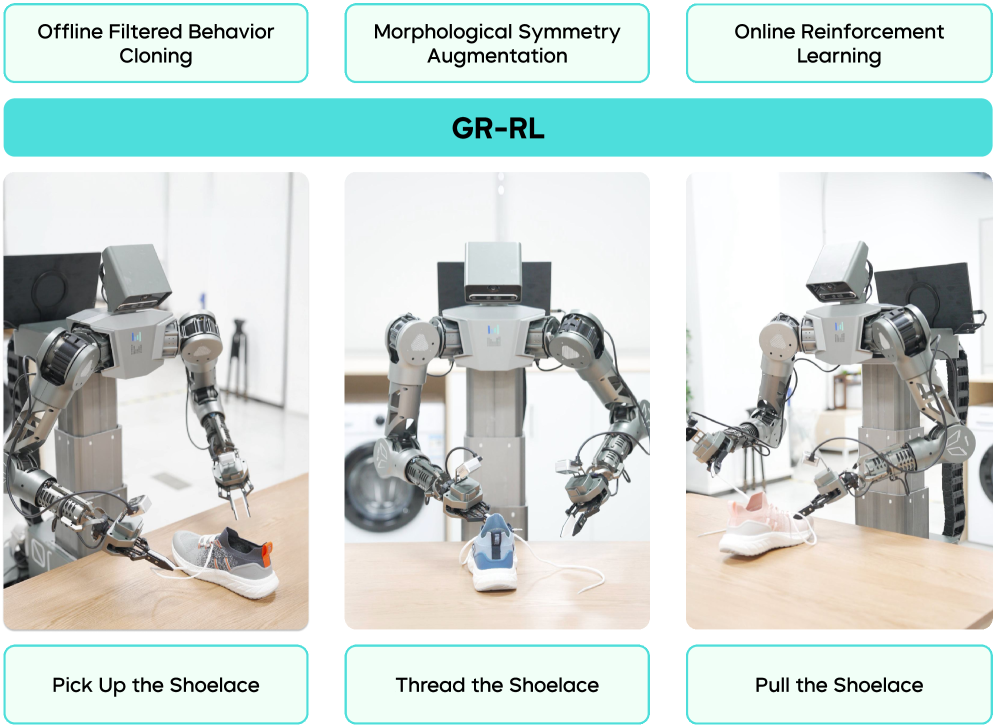
GR-RL: Going Dexterous and Precise for Long-Horizon Robotic Manipulation
作者: Yunfei Li, Xiao Ma, Jiafeng Xu, Yu Cui, Zhongren Cui, Zhigang Han, Liqun Huang, Tao Kong, Yuxiao Liu, Hao Niu, Wanli Peng, Jingchao Qiao, Zeyu Ren, Haixin Shi, Zhi Su, Jiawen Tian, Yuyang Xiao, Shenyu Zhang, Liwei Zheng, Hang Li, Yonghui Wu
分类: cs.RO, cs.LG
发布日期: 2025-12-01 (更新: 2025-12-23)
💡 一句话要点
GR-RL:通过强化学习提升通用视觉-语言-动作策略在灵巧操作中的性能
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人学习 强化学习 灵巧操作 视觉-语言-动作 长时程推理
📋 核心要点
- 现有视觉-语言-动作策略依赖于人类演示,但在灵巧操作任务中,人类演示往往存在噪声和次优性。
- GR-RL通过多阶段训练流程,包括过滤、增强和强化演示,来提升策略在灵巧操作任务中的性能。
- GR-RL在穿鞋带任务中取得了83.3%的成功率,展示了其在长时程推理、高精度控制和柔性物体交互方面的能力。
📝 摘要(中文)
本文提出了一种名为GR-RL的机器人学习框架,旨在将通用的视觉-语言-动作(VLA)策略转化为擅长长时程灵巧操作的专家。该框架基于一个假设:现有VLA策略的核心在于人类演示的最优性。然而,在高度灵巧和精确的操作任务中,人类演示往往存在噪声且并非最优。GR-RL提出了一种多阶段训练流程,通过强化学习来过滤、增强和强化演示。首先,GR-RL学习一个视觉-语言条件下的任务进度,过滤演示轨迹,仅保留对进度有积极贡献的转换。具体而言,通过直接应用稀疏奖励的离线强化学习,得到的Q值可以被视为一个鲁棒的进度函数。其次,引入形态对称增强,显著提高GR-RL的泛化性和性能。最后,为了更好地使VLA策略与其高精度控制的部署行为对齐,通过学习潜在空间噪声预测器来进行在线强化学习。通过这个流程,GR-RL成为首个能够自主完成穿鞋带任务的学习策略,成功率达到83.3%,该任务需要长时程推理、毫米级精度和柔性物体交互。我们希望GR-RL能够推动通用机器人基础模型向可靠的现实世界专家方向发展。
🔬 方法详解
问题定义:论文旨在解决通用视觉-语言-动作(VLA)策略在长时程、高精度灵巧操作任务中表现不佳的问题。现有VLA策略依赖于人类演示,但人类演示在这些任务中通常包含噪声,且并非最优轨迹,导致策略学习受限。
核心思路:论文的核心思路是通过强化学习来提炼和增强人类演示数据。首先,利用离线强化学习学习任务进度,过滤掉对任务进展无益的演示数据。然后,通过形态对称增强来提高模型的泛化能力。最后,通过在线强化学习来微调策略,使其更好地适应实际部署环境中的噪声。
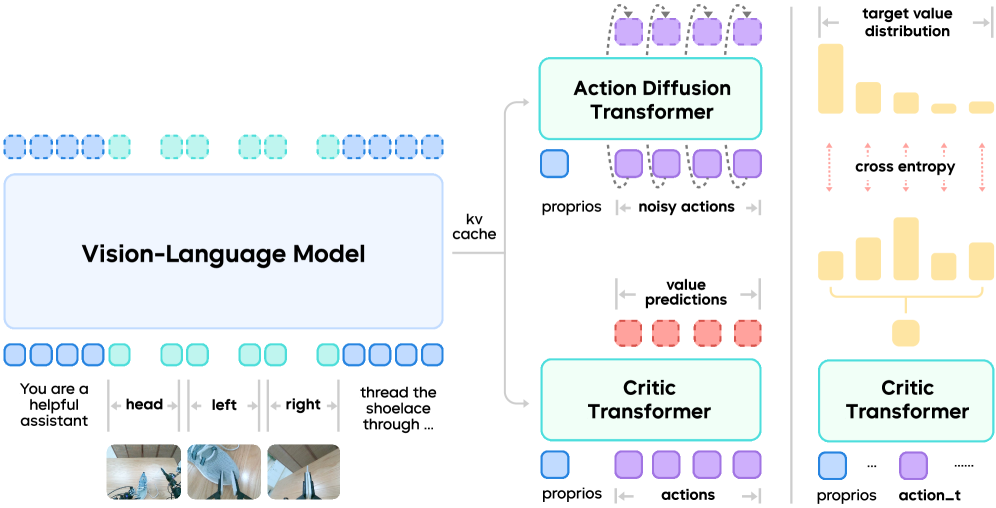
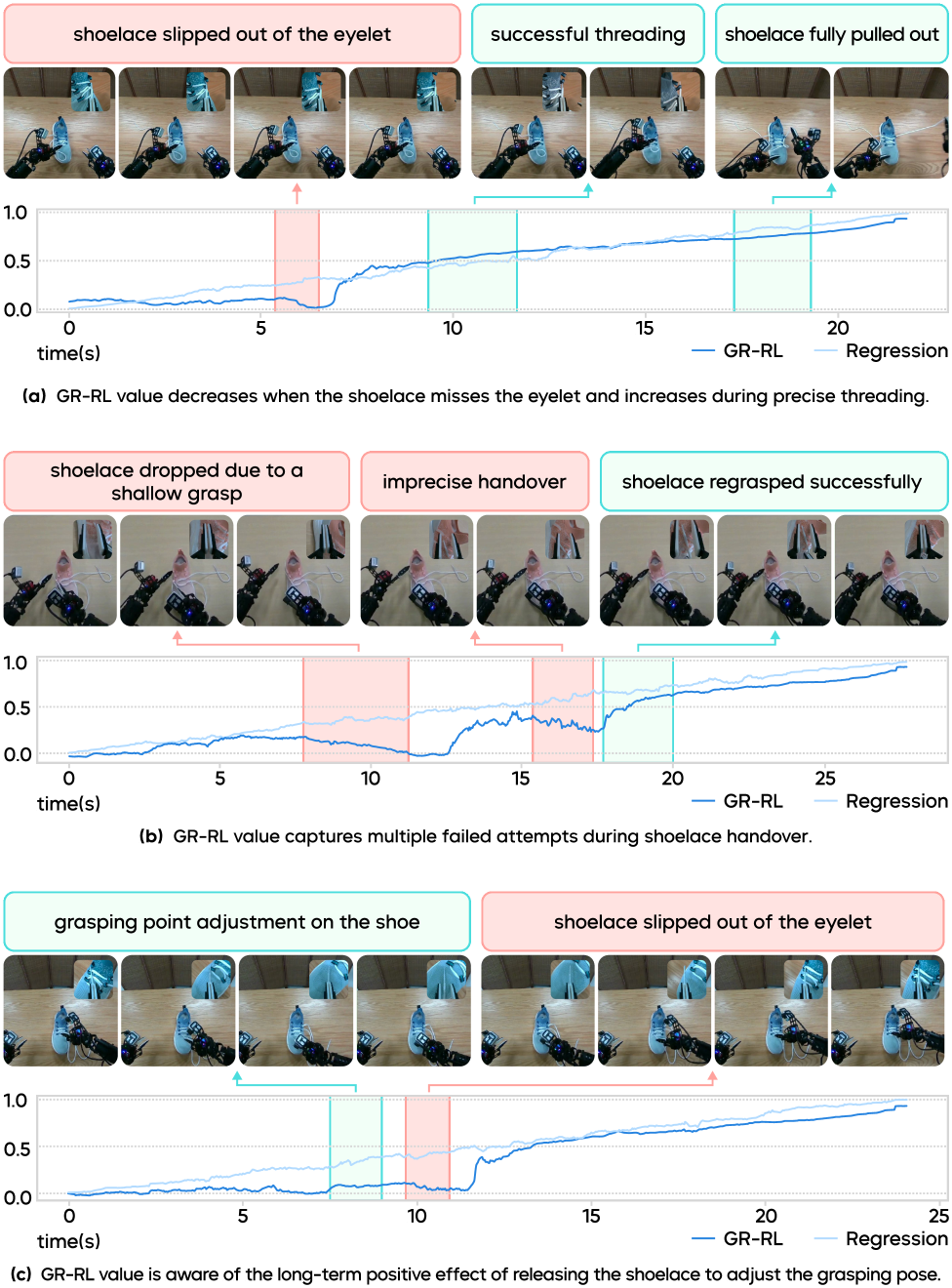
技术框架:GR-RL框架包含三个主要阶段:1) 演示过滤:使用离线强化学习(例如,CQL)学习一个Q函数,并将Q值作为任务进度的度量,过滤掉Q值较低的轨迹片段。2) 形态对称增强:通过对物体进行对称变换(例如,旋转、翻转)来增加训练数据的多样性,提高模型的泛化能力。3) 在线强化学习:通过学习一个潜在空间噪声预测器,来补偿实际部署环境中的噪声,从而提高策略的鲁棒性。
关键创新:GR-RL的关键创新在于将离线强化学习的Q值作为任务进度的度量,并以此来过滤演示数据。这种方法能够有效地去除噪声数据,并保留对任务进展有益的数据,从而提高策略的学习效率和性能。此外,形态对称增强和在线强化学习也进一步提高了策略的泛化能力和鲁棒性。
关键设计:在演示过滤阶段,使用CQL算法进行离线强化学习,奖励函数采用稀疏奖励,只有在任务成功时才给予奖励。在形态对称增强阶段,根据任务的特点选择合适的对称变换方式。在在线强化学习阶段,使用Actor-Critic算法,Critic网络用于评估策略的性能,Actor网络用于学习潜在空间噪声预测器。
🖼️ 关键图片
📊 实验亮点
GR-RL在穿鞋带任务中取得了显著的成果,成功率达到83.3%,远超其他基于学习的方法。该任务需要机器人能够进行长时程推理,精确控制运动轨迹,并与柔性物体进行交互。实验结果表明,GR-RL能够有效地学习到复杂的机器人操作策略,并具有良好的泛化能力和鲁棒性。
🎯 应用场景
GR-RL框架具有广泛的应用前景,可应用于各种需要长时程推理、高精度控制和柔性物体交互的机器人操作任务,例如服装整理、医疗手术、精密装配等。该研究有助于推动通用机器人基础模型向可靠的现实世界专家方向发展,实现机器人的自主化和智能化。
📄 摘要(原文)
We present GR-RL, a robotic learning framework that turns a generalist vision-language-action (VLA) policy into a highly capable specialist for long-horizon dexterous manipulation. Assuming the optimality of human demonstrations is core to existing VLA policies. However, we claim that in highly dexterous and precise manipulation tasks, human demonstrations are noisy and suboptimal. GR-RL proposes a multi-stage training pipeline that filters, augments, and reinforces the demonstrations by reinforcement learning. First, GR-RL learns a vision-language-conditioned task progress, filters the demonstration trajectories, and only keeps the transitions that contribute positively to the progress. Specifically, we show that by directly applying offline RL with sparse reward, the resulting $Q$-values can be treated as a robust progress function. Next, we introduce morphological symmetry augmentation that greatly improves the generalization and performance of GR-RL. Lastly, to better align the VLA policy with its deployment behaviors for high-precision control, we perform online RL by learning a latent space noise predictor. With this pipeline, GR-RL is, to our knowledge, the first learning-based policy that can autonomously lace up a shoe by threading shoelaces through multiple eyelets with an 83.3% success rate, a task requiring long-horizon reasoning, millimeter-level precision, and compliant soft-body interaction. We hope GR-RL provides a step toward enabling generalist robot foundation models to specialize into reliable real-world experts.