IGen: Scalable Data Generation for Robot Learning from Open-World Images
作者: Chenghao Gu, Haolan Kang, Junchao Lin, Jinghe Wang, Duo Wu, Shuzhao Xie, Fanding Huang, Junchen Ge, Ziyang Gong, Letian Li, Hongying Zheng, Changwei Lv, Zhi Wang
分类: cs.RO
发布日期: 2025-12-01
备注: 8 pages, 8 figures
💡 一句话要点
IGen:一种可扩展的机器人学习数据生成框架,利用开放世界图像。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 机器人学习 数据生成 开放世界图像 视觉语言模型 3D场景重建
📋 核心要点
- 现有机器人学习方法依赖于昂贵的在机数据收集,限制了数据规模和环境多样性,阻碍了通用机器人策略的发展。
- IGen框架将开放世界图像转化为机器人可用的训练数据,通过3D场景重建、视觉语言模型规划和动作生成,实现数据自动合成。
- 实验表明,仅使用IGen合成数据训练的策略,性能可与真实数据训练的策略媲美,验证了该方法的可行性和有效性。
📝 摘要(中文)
通用机器人策略的兴起对大规模训练数据提出了指数级的需求。然而,在机器人上进行数据收集既费力又通常局限于特定环境。相比之下,开放世界图像捕捉了大量与机器人操作任务自然对齐的真实场景,为低成本、大规模的机器人数据获取提供了一条有希望的途径。尽管有这种潜力,但由于缺乏相关的机器人动作,开放世界图像在机器人学习中的实际应用受到阻碍,使得这种丰富的视觉资源在很大程度上未被利用。为了弥合这一差距,我们提出了IGen,一个可以从开放世界图像中可扩展地生成逼真的视觉观察和可执行动作的框架。IGen首先将非结构化的2D像素转换为适合场景理解和操作的结构化3D场景表示。然后,它利用视觉语言模型的推理能力将特定于场景的任务指令转换为高级计划,并生成低级动作作为SE(3)末端执行器姿势序列。从这些姿势中,它合成动态场景演化并渲染时间上连贯的视觉观察。实验验证了IGen生成的可视运动数据的高质量,并表明仅在IGen合成数据上训练的策略实现了与在真实世界数据上训练的策略相当的性能。这突出了IGen支持从开放世界图像进行可扩展数据生成以进行通用机器人策略训练的潜力。
🔬 方法详解
问题定义:论文旨在解决机器人学习中数据匮乏的问题,特别是缺乏带有对应机器人动作的开放世界图像数据。现有方法依赖于人工标注或在特定环境中进行机器人数据收集,成本高昂且难以扩展到各种场景,限制了通用机器人策略的训练。
核心思路:论文的核心思路是利用开放世界图像的丰富性和视觉语言模型的推理能力,自动生成带有对应机器人动作的合成数据。通过将2D图像转换为3D场景,并利用视觉语言模型理解任务指令并生成动作序列,从而实现低成本、可扩展的数据生成。
技术框架:IGen框架包含以下主要模块:1) 2D到3D场景重建:将开放世界图像转换为结构化的3D场景表示。2) 视觉语言模型规划:利用视觉语言模型将场景特定的任务指令转换为高级计划。3) 动作生成:将高级计划转换为低级动作,表示为SE(3)末端执行器姿势序列。4) 动态场景合成和渲染:根据生成的动作序列,合成动态场景演化,并渲染时间上连贯的视觉观察。
关键创新:IGen的关键创新在于将开放世界图像与机器人动作联系起来,实现从非结构化数据到结构化机器人训练数据的转换。它结合了3D场景重建、视觉语言模型和动作生成技术,构建了一个端到端的自动化数据生成流程。
关键设计:在3D场景重建方面,可能使用了现有的单目深度估计或多视图几何方法。视觉语言模型可能采用了预训练的大型语言模型,并针对机器人操作任务进行了微调。动作生成可能使用了逆运动学或强化学习方法,以确保生成的动作序列是可执行的。具体的损失函数和网络结构等细节未知。
🖼️ 关键图片


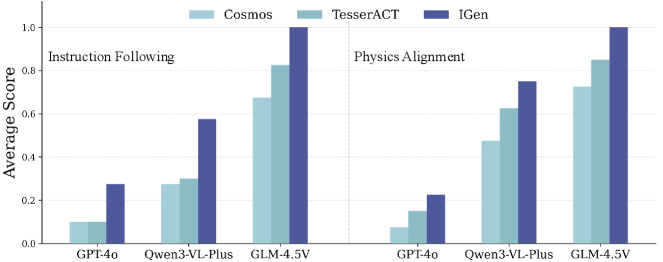
📊 实验亮点
实验结果表明,仅使用IGen合成数据训练的机器人策略,在性能上可以与使用真实世界数据训练的策略相媲美。具体的性能指标和对比基线未知,但该结果证明了IGen生成数据的质量和有效性,为机器人学习提供了一种新的数据来源。
🎯 应用场景
IGen可应用于各种机器人学习任务,例如物体抓取、操作、导航等。它能够降低机器人训练数据的获取成本,加速通用机器人策略的开发和部署。该技术还有潜力应用于虚拟现实、增强现实等领域,生成逼真的交互式环境。
📄 摘要(原文)
The rise of generalist robotic policies has created an exponential demand for large-scale training data. However, on-robot data collection is labor-intensive and often limited to specific environments. In contrast, open-world images capture a vast diversity of real-world scenes that naturally align with robotic manipulation tasks, offering a promising avenue for low-cost, large-scale robot data acquisition. Despite this potential, the lack of associated robot actions hinders the practical use of open-world images for robot learning, leaving this rich visual resource largely unexploited. To bridge this gap, we propose IGen, a framework that scalably generates realistic visual observations and executable actions from open-world images. IGen first converts unstructured 2D pixels into structured 3D scene representations suitable for scene understanding and manipulation. It then leverages the reasoning capabilities of vision-language models to transform scene-specific task instructions into high-level plans and generate low-level actions as SE(3) end-effector pose sequences. From these poses, it synthesizes dynamic scene evolution and renders temporally coherent visual observations. Experiments validate the high quality of visuomotor data generated by IGen, and show that policies trained solely on IGen-synthesized data achieve performance comparable to those trained on real-world data. This highlights the potential of IGen to support scalable data generation from open-world images for generalist robotic policy training.