DiG-Flow: Discrepancy-Guided Flow Matching for Robust VLA Models
作者: Wanpeng Zhang, Ye Wang, Hao Luo, Haoqi Yuan, Yicheng Feng, Sipeng Zheng, Qin Jin, Zongqing Lu
分类: cs.RO
发布日期: 2025-12-01
💡 一句话要点
DiG-Flow:通过差异引导的Flow Matching提升VLA模型在机器人操作任务中的鲁棒性
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言动作模型 机器人操作 Flow Matching 分布差异 几何正则化
📋 核心要点
- 现有的基于Flow Matching的VLA模型在分布偏移和复杂任务中表现下降,表明其表示学习缺乏鲁棒性。
- DiG-Flow通过计算观察和动作嵌入的分布差异,并以此引导表示学习,从而提升VLA模型的鲁棒性。
- 实验表明,DiG-Flow能有效提升VLA模型在复杂多步任务和数据有限情况下的性能,且计算开销小。
📝 摘要(中文)
本文提出了一种名为DiG-Flow的框架,旨在通过几何正则化增强视觉-语言-动作(VLA)模型的鲁棒性。该框架的核心思想是利用观察和动作嵌入之间的分布差异作为几何信号:较低的传输成本表示兼容的表示,而较高的成本则表明潜在的错位。DiG-Flow计算观察和动作嵌入经验分布之间的差异度量,通过单调函数将其映射到调制权重,并在flow matching之前将残差更新应用于观察嵌入。这种干预在表示层面进行,不修改flow matching路径或目标向量场。理论分析表明,差异引导训练可以有效降低训练目标,并且引导推理细化能够收敛。实验结果表明,DiG-Flow可以集成到现有的VLA架构中,开销很小,并能持续提高性能,尤其是在复杂的多步骤任务和有限的训练数据下。
🔬 方法详解
问题定义:现有的视觉-语言-动作(VLA)模型,特别是那些基于Flow Matching训练的模型,在机器人操作任务中表现出了潜力。然而,当面临分布偏移(distribution shift)或需要执行复杂的多步骤任务时,它们的性能会显著下降。这表明这些模型学习到的表示可能无法鲁棒地捕捉到与任务相关的语义信息,从而限制了其泛化能力。
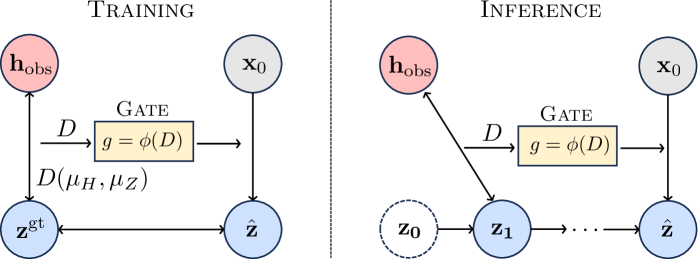
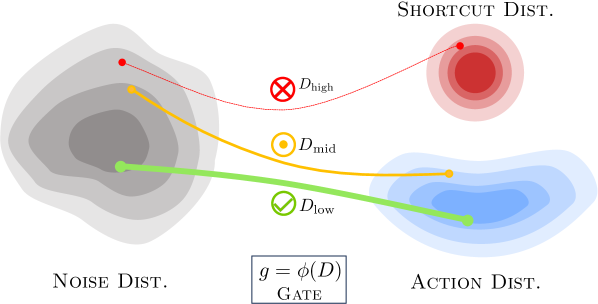
核心思路:DiG-Flow的核心思路是利用观察(observation)和动作(action)嵌入之间的分布差异作为一种几何信号来指导表示学习。具体来说,如果观察和动作的嵌入在语义上是兼容的,那么它们之间的分布差异应该较小;反之,如果它们之间存在错位,那么分布差异应该较大。DiG-Flow利用这种差异来调整观察嵌入,使其更好地与动作嵌入对齐,从而提高模型的鲁棒性。
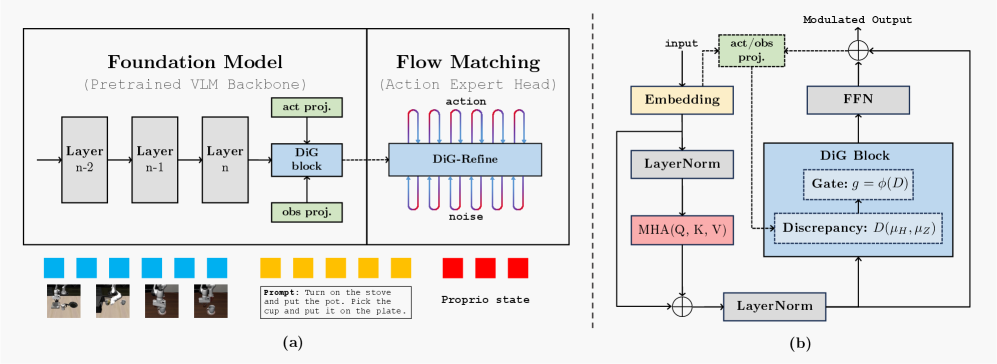
技术框架:DiG-Flow的整体框架可以概括为以下几个步骤:1. 计算差异度量:计算观察和动作嵌入的经验分布之间的差异度量。可以使用各种距离度量,例如Wasserstein距离或最大平均差异(MMD)。2. 映射到调制权重:使用一个单调函数将差异度量映射到一个调制权重。这个单调函数确保差异越大,权重越大,从而对观察嵌入的调整幅度也越大。3. 残差更新:将调制权重应用于观察嵌入,进行残差更新。这意味着观察嵌入会根据其与动作嵌入的差异进行调整,使其更接近动作嵌入的语义空间。4. Flow Matching:使用调整后的观察嵌入进行Flow Matching训练。
关键创新:DiG-Flow的关键创新在于它利用了观察和动作嵌入之间的分布差异作为一种几何信号来指导表示学习。这种方法与传统的Flow Matching方法不同,后者通常只关注如何学习一个从观察到动作的连续映射。DiG-Flow通过在表示层面进行干预,可以更有效地提高模型的鲁棒性,而无需修改Flow Matching的路径或目标向量场。
关键设计:DiG-Flow的关键设计包括:1. 差异度量选择:选择合适的差异度量对于DiG-Flow的性能至关重要。论文中可能使用了Wasserstein距离或MMD等度量。2. 单调函数设计:单调函数的设计需要仔细考虑,以确保差异度量能够有效地映射到调制权重。3. 残差更新策略:残差更新策略需要平衡调整幅度和稳定性,以避免过度调整或训练不稳定。4. 损失函数:DiG-Flow的损失函数包括Flow Matching损失和可能用于正则化差异度量的损失项。
🖼️ 关键图片
📊 实验亮点
DiG-Flow在多个机器人操作任务上进行了评估,并取得了显著的性能提升。特别是在复杂的多步骤任务和有限的训练数据下,DiG-Flow的优势更加明显。实验结果表明,DiG-Flow可以有效地提高VLA模型的鲁棒性,使其更好地适应分布偏移和噪声干扰。该方法可以集成到现有的VLA架构中,开销很小,具有很强的实用性。
🎯 应用场景
DiG-Flow在机器人操作领域具有广泛的应用前景,可以应用于各种需要视觉感知和动作控制的任务,例如物体抓取、装配、导航等。通过提高VLA模型的鲁棒性,DiG-Flow可以使机器人更好地适应真实世界的复杂环境,并完成更具挑战性的任务。此外,该方法还可以应用于其他需要多模态融合的领域,例如自动驾驶、智能助手等。
📄 摘要(原文)
Vision-Language-Action (VLA) models trained with flow matching have demonstrated impressive capabilities on robotic manipulation tasks. However, their performance often degrades under distribution shift and on complex multi-step tasks, suggesting that the learned representations may not robustly capture task-relevant semantics. We introduce DiG-Flow, a principled framework that enhances VLA robustness through geometric regularization. Our key insight is that the distributional discrepancy between observation and action embeddings provides a meaningful geometric signal: lower transport cost indicates compatible representations, while higher cost suggests potential misalignment. DiG-Flow computes a discrepancy measure between empirical distributions of observation and action embeddings, maps it to a modulation weight via a monotone function, and applies residual updates to the observation embeddings before flow matching. Crucially, this intervention operates at the representation level without modifying the flow matching path or target vector field. We provide theoretical guarantees showing that discrepancy-guided training provably decreases the training objective, and that guided inference refinement converges with contraction. Empirically, DiG-Flow integrates into existing VLA architectures with negligible overhead and consistently improves performance, with particularly pronounced gains on complex multi-step tasks and under limited training data.