RynnVLA-002: A Unified Vision-Language-Action and World Model
作者: Jun Cen, Siteng Huang, Yuqian Yuan, Kehan Li, Hangjie Yuan, Chaohui Yu, Yuming Jiang, Jiayan Guo, Xin Li, Hao Luo, Fan Wang, Deli Zhao, Hao Chen
分类: cs.RO
发布日期: 2025-11-21 (更新: 2025-11-24)
💡 一句话要点
RynnVLA-002:提出统一的视觉-语言-动作和世界模型,提升机器人任务性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言-动作模型 世界模型 机器人学习 环境动态 动作规划
📋 核心要点
- 现有VLA模型和世界模型通常独立训练,忽略了环境动态和动作规划之间的相互依赖关系。
- RynnVLA-002通过统一VLA和世界模型,实现环境动态和动作规划的联合学习,相互增强。
- 实验表明,RynnVLA-002在仿真和真实机器人任务中均优于单独的VLA和世界模型,显著提升了任务成功率。
📝 摘要(中文)
我们介绍了RynnVLA-002,一个统一的视觉-语言-动作(VLA)和世界模型。该世界模型利用动作和视觉输入来预测未来的图像状态,学习环境的潜在物理特性,从而改进动作生成。反过来,VLA模型从图像观测中产生后续动作,增强视觉理解,并支持世界模型的图像生成。RynnVLA-002的统一框架实现了环境动态和动作规划的联合学习。实验表明,RynnVLA-002超越了单独的VLA和世界模型,证明了它们之间的相互增强。我们在仿真和真实机器人任务中评估了RynnVLA-002。RynnVLA-002在LIBERO仿真基准上实现了97.4%的成功率,无需预训练,而在真实LeRobot实验中,其集成的世界模型将整体成功率提高了50%。
🔬 方法详解
问题定义:现有视觉-语言-动作(VLA)模型和世界模型通常是独立开发的,忽略了它们之间的相互作用。VLA模型侧重于从视觉输入生成动作,而世界模型则侧重于预测环境的未来状态。这种分离导致次优的性能,尤其是在需要长期规划和理解环境动态的复杂机器人任务中。因此,如何有效地整合VLA模型和世界模型,实现它们之间的相互增强,是一个重要的挑战。
核心思路:RynnVLA-002的核心思路是将VLA模型和世界模型统一到一个框架中,使它们能够相互学习和增强。VLA模型利用视觉输入生成动作,同时为世界模型提供动作信息。世界模型则利用动作和视觉输入预测未来的图像状态,从而学习环境的潜在物理特性,并为VLA模型提供更准确的视觉理解。这种相互作用使得模型能够更好地理解环境动态,并生成更有效的动作。
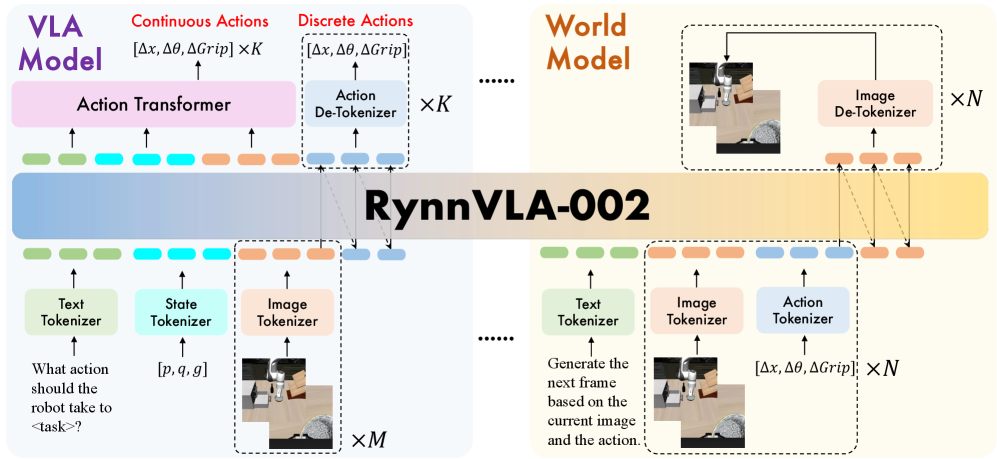
技术框架:RynnVLA-002的整体架构包含两个主要模块:VLA模型和世界模型。VLA模型接收图像观测作为输入,并生成后续动作。世界模型接收图像观测和动作作为输入,并预测未来的图像状态。这两个模块通过共享的潜在空间进行连接,使得它们能够相互传递信息。训练过程中,VLA模型和世界模型联合优化,从而实现环境动态和动作规划的联合学习。
关键创新:RynnVLA-002最重要的技术创新点在于其统一的VLA和世界模型框架。通过将这两个模型整合到一个框架中,RynnVLA-002能够实现环境动态和动作规划的联合学习,从而超越了单独的VLA和世界模型。这种统一框架使得模型能够更好地理解环境动态,并生成更有效的动作。
关键设计:RynnVLA-002的关键设计包括:1) 使用Transformer架构来实现VLA模型和世界模型;2) 使用对比学习来学习共享的潜在空间;3) 使用对抗训练来提高世界模型的图像生成质量;4) 使用强化学习来优化VLA模型的动作生成策略。具体的参数设置、损失函数和网络结构等细节未在摘要中详细说明,属于未知信息。
🖼️ 关键图片


📊 实验亮点
RynnVLA-002在LIBERO仿真基准上实现了97.4%的成功率,无需预训练。在真实LeRobot实验中,集成的世界模型将整体成功率提高了50%。这些结果表明,RynnVLA-002能够有效地学习环境动态和动作规划,并在仿真和真实环境中均表现出优异的性能。
🎯 应用场景
RynnVLA-002具有广泛的应用前景,包括机器人导航、物体操作、自动驾驶等领域。通过学习环境动态和动作规划,RynnVLA-002可以使机器人更好地理解环境,并生成更有效的动作,从而提高机器人的自主性和适应性。未来,RynnVLA-002有望应用于更复杂的机器人任务,例如家庭服务机器人、工业自动化机器人等。
📄 摘要(原文)
We introduce RynnVLA-002, a unified Vision-Language-Action (VLA) and world model. The world model leverages action and visual inputs to predict future image states, learning the underlying physics of the environment to refine action generation. Conversely, the VLA model produces subsequent actions from image observations, enhancing visual understanding and supporting the world model's image generation. The unified framework of RynnVLA-002 enables joint learning of environmental dynamics and action planning. Our experiments show that RynnVLA-002 surpasses individual VLA and world models, demonstrating their mutual enhancement. We evaluate RynnVLA-002 in both simulation and real-world robot tasks. RynnVLA-002 achieves 97.4% success rate on the LIBERO simulation benchmark without pretraining, while in real-world LeRobot experiments, its integrated world model boosts the overall success rate by 50%.