Progress-Think: Semantic Progress Reasoning for Vision-Language Navigation
作者: Shuo Wang, Yucheng Wang, Guoxin Lian, Yongcai Wang, Maiyue Chen, Kaihui Wang, Bo Zhang, Zhizhong Su, Yutian Zhou, Wanting Li, Deying Li, Zhaoxin Fan
分类: cs.RO
发布日期: 2025-11-21
💡 一句话要点
Progress-Think提出语义进度推理,提升视觉-语言导航任务的性能和效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言导航 语义进度推理 强化学习 自对齐预训练 多模态融合
📋 核心要点
- 现有VLN模型忽略了视觉观察和指令之间的协同进展关系,导致导航精度受限。
- Progress-Think引入语义进度推理,通过预测指令风格的进度来指导导航,提升一致性。
- 该方法通过三阶段框架实现,并在R2R-CE和RxR-CE数据集上取得了SOTA性能。
📝 摘要(中文)
视觉-语言导航(VLN)要求智能体具备长期连贯的行动能力,不仅要理解局部视觉环境,还要理解在多步指令中已完成的进度。然而,现有的视觉-语言-动作模型侧重于直接的动作预测,而早期的进度方法则预测数值上的成就;两者都忽略了观察序列和指令序列之间的单调协同进展特性。基于此,Progress-Think引入了语义进度推理,从视觉观察中预测指令风格的进度,从而实现更准确的导航。为了在没有昂贵标注的情况下实现这一点,我们提出了一个三阶段框架。在初始阶段,自对齐进度预训练通过视觉历史和指令前缀之间的新型可微对齐来引导推理模块。然后,进度引导策略预训练将学习到的进度状态注入到导航上下文中,引导策略采取一致的行动。最后,进度-策略协同微调使用定制的进度感知强化目标共同优化这两个模块。在R2R-CE和RxR-CE上的实验表明,该方法达到了最先进的成功率和效率,证明了语义进度能够产生更一致的导航进展表示。
🔬 方法详解
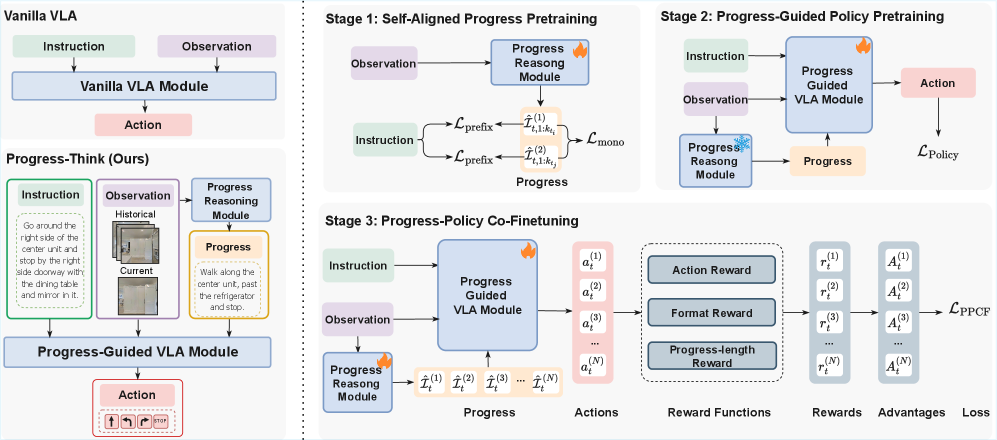
问题定义:视觉-语言导航任务旨在让智能体根据自然语言指令,在真实或模拟环境中导航到目标位置。现有方法主要关注局部视觉信息的理解和动作预测,忽略了导航过程中视觉观察和指令之间的单调协同进展关系。此外,早期方法尝试预测数值进度,但缺乏对语义信息的利用,导致导航效率和准确性不高。
核心思路:Progress-Think的核心思路是利用视觉观察来推断智能体在指令执行过程中的语义进度。通过学习视觉信息和指令之间的对应关系,模型可以更好地理解当前所处的状态,并做出更合理的导航决策。这种语义进度推理能够提供更一致的导航进展表示,从而提升导航性能。
技术框架:该方法采用一个三阶段框架:1) 自对齐进度预训练:利用可微对齐方法,将视觉历史与指令前缀对齐,从而预训练一个推理模块,使其能够从视觉信息中推断语义进度。2) 进度引导策略预训练:将学习到的进度状态注入到导航上下文中,引导策略学习采取与当前进度一致的行动。3) 进度-策略协同微调:使用定制的进度感知强化学习目标,共同优化推理模块和策略网络,进一步提升导航性能。
关键创新:该方法最重要的创新点在于引入了语义进度推理的概念,并设计了一个三阶段框架来实现这一目标。与现有方法相比,Progress-Think不仅考虑了局部视觉信息,还关注了导航过程中的整体进展,从而能够做出更明智的决策。此外,该方法还提出了一种自对齐进度预训练方法,可以在没有昂贵标注的情况下学习语义进度。
关键设计:在自对齐进度预训练阶段,使用了可微对齐损失函数,鼓励视觉历史和指令前缀之间的对齐。在进度引导策略预训练阶段,将学习到的进度状态作为额外的输入特征,输入到策略网络中。在进度-策略协同微调阶段,使用了进度感知的奖励函数,鼓励智能体采取与当前进度一致的行动。具体的网络结构和参数设置在论文中有详细描述。
🖼️ 关键图片


📊 实验亮点
在R2R-CE和RxR-CE数据集上的实验结果表明,Progress-Think方法取得了最先进的性能。具体而言,该方法在成功率和效率方面均优于现有方法,证明了语义进度推理的有效性。实验结果表明,该方法能够更准确地理解导航进展,从而做出更合理的决策。
🎯 应用场景
该研究成果可应用于机器人导航、自动驾驶、虚拟现实等领域。通过理解指令和环境之间的关系,智能体可以更有效地完成导航任务,提升用户体验。未来,该技术有望应用于更复杂的场景,例如室内服务机器人、物流配送机器人等。
📄 摘要(原文)
Vision-Language Navigation requires agents to act coherently over long horizons by understanding not only local visual context but also how far they have advanced within a multi-step instruction. However, recent Vision-Language-Action models focus on direct action prediction and earlier progress methods predict numeric achievements; both overlook the monotonic co-progression property of the observation and instruction sequences. Building on this insight, Progress-Think introduces semantic progress reasoning, predicting instruction-style progress from visual observations to enable more accurate navigation. To achieve this without expensive annotations, we propose a three-stage framework. In the initial stage, Self-Aligned Progress Pretraining bootstraps a reasoning module via a novel differentiable alignment between visual history and instruction prefixes. Then, Progress-Guided Policy Pretraining injects learned progress states into the navigation context, guiding the policy toward consistent actions. Finally, Progress-Policy Co-Finetuning jointly optimizes both modules with tailored progress-aware reinforcement objectives. Experiments on R2R-CE and RxR-CE show state-of-the-art success and efficiency, demonstrating that semantic progress yields a more consistent representation of navigation advancement.