VISTAv2: World Imagination for Indoor Vision-and-Language Navigation
作者: Yanjia Huang, Xianshun Jiang, Xiangbo Gao, Mingyang Wu, Zhengzhong Tu
分类: cs.RO, cs.CV
发布日期: 2025-11-14
备注: 11 pages, 5 figures
💡 一句话要点
VISTAv2:用于室内视觉-语言导航的生成式世界模型
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱六:视频提取与匹配 (Video Extraction) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言导航 生成式世界模型 条件扩散Transformer 在线价值地图 动作条件预测
📋 核心要点
- 现有基于图像想象的VLN方法缺乏在线动作条件预测,且未产生明确的规划价值,限制了导航性能。
- VISTAv2提出了一种生成式世界模型,通过预测未来视图并融合到在线价值地图中,为规划器提供可达性和风险意识指导。
- 实验表明,VISTAv2在MP3D和RoboTHOR数据集上优于现有基线,证明了动作条件想象和在线价值地图规划器的有效性。
📝 摘要(中文)
视觉-语言导航(VLN)要求智能体在连续的真实世界空间中根据语言指令行动。先前基于图像想象的VLN工作显示了离散全景图的优势,但缺乏在线的、动作条件预测,并且没有产生明确的规划价值;此外,许多方法用脆弱且缓慢的长程目标取代了规划器。为了弥合这一差距,我们提出了VISTAv2,一个生成式世界模型,它展开以自我为中心的未来视图,这些视图以过去的观察、候选动作序列和指令为条件,并将它们投影到用于规划的在线价值地图中。与先前的方法不同,VISTAv2没有取代规划器。在线价值地图在分数级别与基本目标融合,提供可达性和风险意识指导。具体而言,我们采用动作感知的条件扩散Transformer视频预测器来合成短程未来,通过视觉-语言评分器将它们与自然语言指令对齐,并在可微的想象-价值头中融合多个展开,以输出想象的以自我为中心的价值地图。为了提高效率,展开发生在VAE潜在空间中,并使用蒸馏采样器和稀疏解码,从而能够在单个消费级GPU上进行推理。在MP3D和RoboTHOR上的评估表明,VISTAv2优于强大的基线,并且消融实验表明,动作条件想象、指令引导的价值融合和在线价值地图规划器都至关重要,这表明VISTAv2为鲁棒的VLN提供了一条实用且可解释的途径。
🔬 方法详解
问题定义:视觉-语言导航(VLN)任务旨在让智能体根据自然语言指令在真实环境中导航。现有基于图像想象的方法通常依赖于离散的全景图,缺乏在线的、动作条件预测能力,难以进行有效的长期规划。此外,一些方法直接用长程目标取代规划器,导致模型脆弱且效率低下。
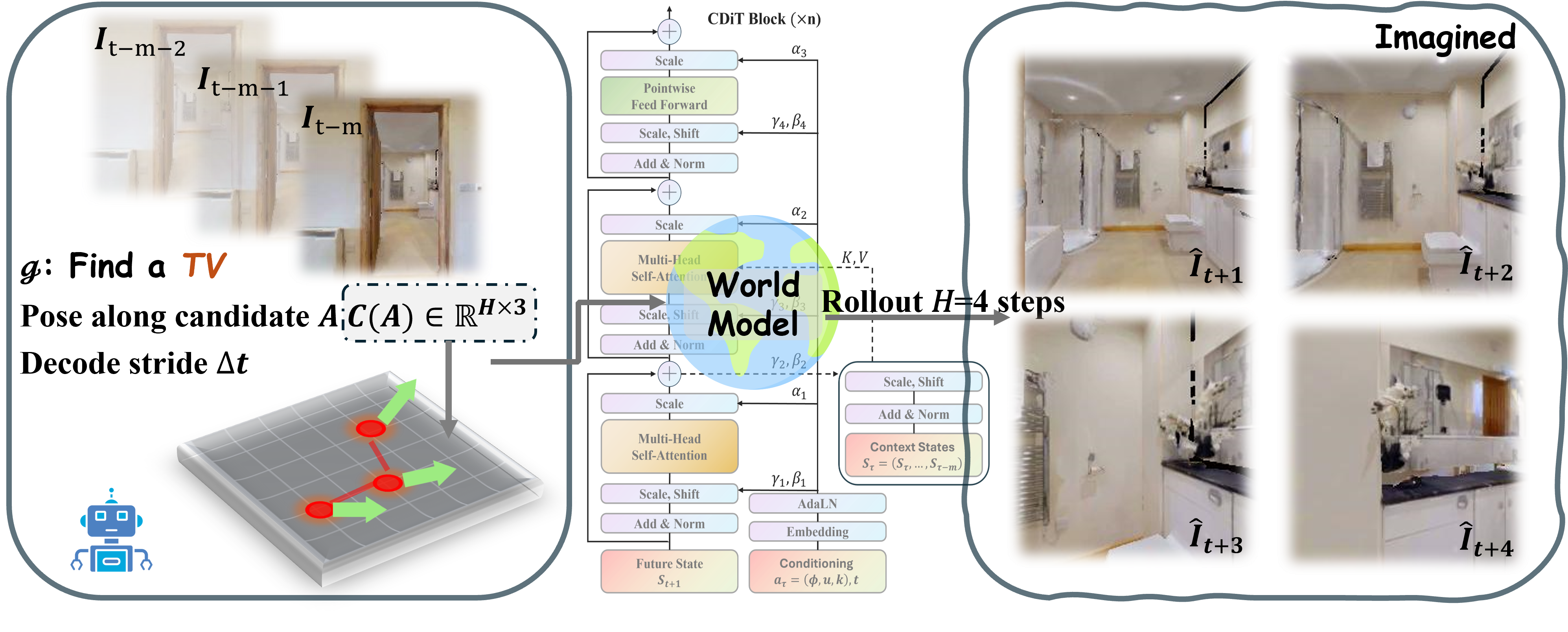
核心思路:VISTAv2的核心思想是构建一个生成式世界模型,该模型能够根据过去的观察、候选动作序列和指令,预测未来可能的场景视图。通过将这些预测的未来视图转化为在线价值地图,VISTAv2能够为规划器提供关于环境可达性和风险的指导,从而实现更鲁棒和高效的导航。
技术框架:VISTAv2的整体框架包括以下几个主要模块:1) 动作感知的条件扩散Transformer视频预测器:用于合成短程的未来视图;2) 视觉-语言评分器:用于将预测的未来视图与自然语言指令对齐;3) 想象-价值头:用于融合多个未来视图的预测结果,生成在线价值地图;4) 规划器:利用在线价值地图和基本目标进行导航决策。整个流程在VAE潜在空间中进行,并采用蒸馏采样器和稀疏解码来提高效率。
关键创新:VISTAv2的关键创新在于其在线价值地图规划器。与以往直接用长程目标取代规划器的方法不同,VISTAv2保留了规划器,并通过在线价值地图为其提供额外的指导信息。这种方法既保证了规划的灵活性,又提高了导航的鲁棒性。此外,使用条件扩散Transformer进行视频预测,能够生成更逼真和多样化的未来视图。
关键设计:VISTAv2采用动作感知的条件扩散Transformer进行视频预测,该Transformer以过去的观察、候选动作序列和指令作为输入,预测未来几步的场景视图。为了提高效率,预测在VAE潜在空间中进行。视觉-语言评分器使用对比学习的方法,将预测的未来视图与自然语言指令对齐。想象-价值头使用可微的融合操作,将多个未来视图的预测结果融合到在线价值地图中。为了进一步提高效率,VISTAv2采用蒸馏采样器和稀疏解码。
🖼️ 关键图片


📊 实验亮点
VISTAv2在MP3D和RoboTHOR数据集上取得了显著的性能提升。消融实验表明,动作条件想象、指令引导的价值融合和在线价值地图规划器都对性能至关重要。与现有基线相比,VISTAv2在导航成功率和路径长度方面均有明显改善,证明了其有效性和鲁棒性。
🎯 应用场景
VISTAv2在室内视觉-语言导航领域具有广泛的应用前景,例如服务型机器人、智能家居、虚拟现实等。该模型能够帮助机器人在复杂环境中根据自然语言指令完成导航任务,提高人机交互的自然性和效率。未来,该技术还可以扩展到其他需要长期规划和决策的任务中,例如自动驾驶、游戏AI等。
📄 摘要(原文)
Vision-and-Language Navigation (VLN) requires agents to follow language instructions while acting in continuous real-world spaces. Prior image imagination based VLN work shows benefits for discrete panoramas but lacks online, action-conditioned predictions and does not produce explicit planning values; moreover, many methods replace the planner with long-horizon objectives that are brittle and slow. To bridge this gap, we propose VISTAv2, a generative world model that rolls out egocentric future views conditioned on past observations, candidate action sequences, and instructions, and projects them into an online value map for planning. Unlike prior approaches, VISTAv2 does not replace the planner. The online value map is fused at score level with the base objective, providing reachability and risk-aware guidance. Concretely, we employ an action-aware Conditional Diffusion Transformer video predictor to synthesize short-horizon futures, align them with the natural language instruction via a vision-language scorer, and fuse multiple rollouts in a differentiable imagination-to-value head to output an imagined egocentric value map. For efficiency, rollouts occur in VAE latent space with a distilled sampler and sparse decoding, enabling inference on a single consumer GPU. Evaluated on MP3D and RoboTHOR, VISTAv2 improves over strong baselines, and ablations show that action-conditioned imagination, instruction-guided value fusion, and the online value-map planner are all critical, suggesting that VISTAv2 offers a practical and interpretable route to robust VLN.