Large Language Models and 3D Vision for Intelligent Robotic Perception and Autonomy
作者: Vinit Mehta, Charu Sharma, Karthick Thiyagarajan
分类: cs.RO, cs.CV
发布日期: 2025-11-14 (更新: 2025-11-18)
备注: 45 pages, 15 figures, MDPI Sensors Journal
期刊: Sensors 2025, 25(20), 6394
DOI: 10.3390/s25206394
💡 一句话要点
融合LLM与3D视觉,提升机器人感知与自主性
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 3D视觉 机器人感知 自主性 多模态融合
📋 核心要点
- 现有机器人感知技术在复杂环境理解和自然语言交互方面存在不足,限制了其自主性。
- 该研究探索了将大型语言模型与3D视觉融合,使机器人能够通过语言和空间理解与环境交互。
- 综述了该领域的方法、应用和挑战,并讨论了未来研究方向,为机器人感知技术发展提供参考。
📝 摘要(中文)
随着人工智能和机器人技术的快速发展,将大型语言模型(LLM)与3D视觉相结合,正成为增强机器人感知技术的变革性方法。这种融合使机器能够通过自然语言和空间理解来感知、推理和与复杂环境交互,从而弥合了语言智能和空间感知之间的差距。本文全面分析了LLM和3D视觉交叉领域的最新方法、应用和挑战,重点关注下一代机器人传感技术。首先介绍LLM和3D数据表示的基本原理,然后深入研究对机器人至关重要的3D传感技术。接着,探讨了场景理解、文本到3D生成、对象定位和具身智能体等方面的关键进展,重点介绍了零样本3D分割、动态场景合成和语言引导操作等前沿技术。此外,还讨论了将3D数据与触觉、听觉和热输入相结合的多模态LLM,从而增强了环境理解和机器人决策能力。为了支持未来的研究,我们整理了专门为3D语言和视觉任务定制的基准数据集和评估指标。最后,我们确定了关键挑战和未来的研究方向,包括自适应模型架构、增强的跨模态对齐和实时处理能力,这些都为更智能、上下文感知和自主的机器人传感系统铺平了道路。
🔬 方法详解
问题定义:现有机器人感知系统在理解复杂环境和执行需要高级推理的任务时面临挑战。传统的机器人感知方法通常依赖于预定义的规则和有限的传感器数据,难以处理真实世界环境中的不确定性和变化。此外,缺乏自然语言交互能力使得机器人难以与人类进行有效的沟通和协作。
核心思路:该综述的核心思路是探索如何利用大型语言模型(LLM)的强大语言理解和生成能力,结合3D视觉的空间感知能力,来提升机器人的感知和自主性。通过将LLM与3D视觉相结合,机器人可以更好地理解场景、进行推理,并执行复杂的任务。
技术框架:该综述首先介绍了LLM和3D数据表示的基础知识,然后深入探讨了3D传感技术。接着,重点介绍了场景理解、文本到3D生成、对象定位和具身智能体等方面的关键进展。此外,还讨论了多模态LLM,这些模型集成了3D数据以及触觉、听觉和热输入,以增强环境理解和机器人决策能力。最后,该综述还整理了基准数据集和评估指标,并确定了关键挑战和未来的研究方向。
关键创新:该综述的关键创新在于它全面地概述了LLM和3D视觉在机器人感知中的融合,并突出了该领域的前沿技术和未来发展方向。它不仅涵盖了各种方法和应用,还讨论了关键挑战和潜在的解决方案,为未来的研究提供了有价值的指导。与现有方法相比,该综述更侧重于LLM在机器人感知中的作用,并强调了跨模态融合的重要性。
关键设计:该综述并没有提出新的算法或模型,而是对现有文献进行了系统性的回顾和分析。它关注的关键设计包括:如何将LLM与3D视觉数据进行有效对齐,如何利用LLM进行场景理解和推理,以及如何设计多模态LLM来处理来自不同传感器的信息。此外,该综述还强调了数据集和评估指标的重要性,并讨论了如何开发更具挑战性和代表性的基准。
🖼️ 关键图片
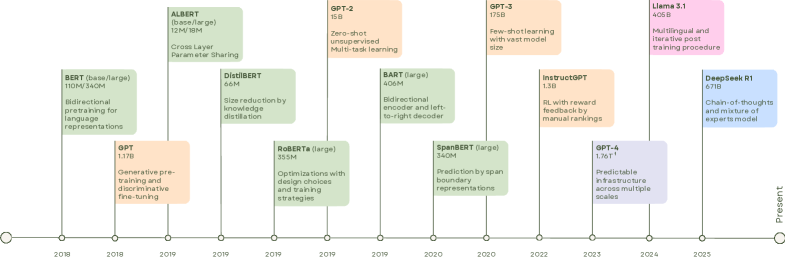
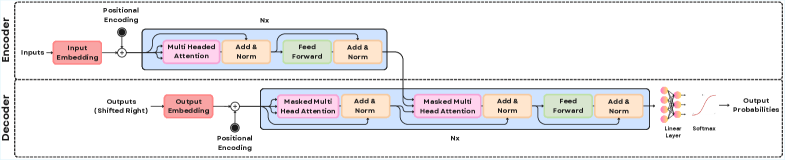
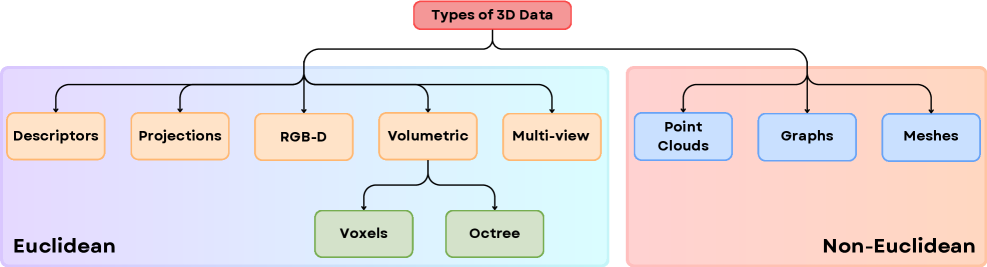
📊 实验亮点
该综述重点介绍了零样本3D分割、动态场景合成和语言引导操作等前沿技术,这些技术代表了LLM和3D视觉融合的最新进展。此外,该综述还强调了多模态LLM的重要性,并讨论了如何将3D数据与触觉、听觉和热输入相结合,以增强环境理解和机器人决策能力。这些亮点表明,LLM和3D视觉的融合具有巨大的潜力,可以推动机器人感知技术的快速发展。
🎯 应用场景
该研究成果可应用于多种领域,包括自动驾驶、智能家居、医疗机器人和工业自动化。通过提升机器人的感知和自主性,可以实现更安全、更高效和更智能的自动化系统。例如,在自动驾驶领域,融合LLM和3D视觉的机器人可以更好地理解交通场景,并做出更合理的决策。在医疗领域,机器人可以辅助医生进行手术,并提供个性化的护理服务。
📄 摘要(原文)
With the rapid advancement of artificial intelligence and robotics, the integration of Large Language Models (LLMs) with 3D vision is emerging as a transformative approach to enhancing robotic sensing technologies. This convergence enables machines to perceive, reason and interact with complex environments through natural language and spatial understanding, bridging the gap between linguistic intelligence and spatial perception. This review provides a comprehensive analysis of state-of-the-art methodologies, applications and challenges at the intersection of LLMs and 3D vision, with a focus on next-generation robotic sensing technologies. We first introduce the foundational principles of LLMs and 3D data representations, followed by an in-depth examination of 3D sensing technologies critical for robotics. The review then explores key advancements in scene understanding, text-to-3D generation, object grounding and embodied agents, highlighting cutting-edge techniques such as zero-shot 3D segmentation, dynamic scene synthesis and language-guided manipulation. Furthermore, we discuss multimodal LLMs that integrate 3D data with touch, auditory and thermal inputs, enhancing environmental comprehension and robotic decision-making. To support future research, we catalog benchmark datasets and evaluation metrics tailored for 3D-language and vision tasks. Finally, we identify key challenges and future research directions, including adaptive model architectures, enhanced cross-modal alignment and real-time processing capabilities, which pave the way for more intelligent, context-aware and autonomous robotic sensing systems.