Scalable Policy Evaluation with Video World Models
作者: Wei-Cheng Tseng, Jinwei Gu, Qinsheng Zhang, Hanzi Mao, Ming-Yu Liu, Florian Shkurti, Lin Yen-Chen
分类: cs.RO
发布日期: 2025-11-14 (更新: 2025-12-04)
💡 一句话要点
提出基于视频世界模型的策略评估方法,提升机器人策略评估的可扩展性。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频世界模型 策略评估 机器人操作 动作条件生成 视频生成模型
📋 核心要点
- 机器人操作通用策略的评估面临真实环境测试成本高、耗时、劳动密集等问题,且存在安全风险。
- 论文提出利用动作条件视频生成模型作为世界模型,通过预测策略在环境中的行为来进行策略评估。
- 实验表明,该方法在策略排序和策略值预测方面表现良好,为无需真实世界交互的策略评估提供了有效途径。
📝 摘要(中文)
本文提出了一种利用动作条件视频生成模型作为世界模型进行策略评估的可扩展方法。针对机器人操作任务中通用策略的评估难题,该方法将动作条件融入到预训练的视频生成模型中,从而能够利用互联网规模的在线视频进行预训练,避免了收集大量配对视频-动作数据的昂贵成本。论文考察了数据集多样性、预训练权重以及常见失败案例对评估流程的影响。实验结果表明,在包括策略排序和实际策略值与预测策略值之间的相关性等多个指标上,该模型为无需真实世界交互的策略评估提供了一种有前景的方法。
🔬 方法详解
问题定义:现有机器人操作策略的评估依赖于真实环境测试,成本高昂且存在安全风险。手动构建仿真环境虽然可以降低成本,但工程量巨大,且存在严重的sim-to-real差距,包括物理引擎和渲染效果的差异。因此,需要一种可扩展且高效的策略评估方法,减少对真实环境交互的依赖。
核心思路:论文的核心思路是利用动作条件视频生成模型来学习世界模型,通过预测给定动作序列后环境的变化,从而评估策略的优劣。这种方法避免了直接在真实环境中测试策略,降低了成本和风险。同时,利用预训练的视频生成模型,可以有效利用互联网上的海量视频数据,减少对特定领域数据的依赖。
技术框架:该方法主要包含以下几个阶段:1) 使用大规模无标注视频数据预训练视频生成模型;2) 将动作信息融入到预训练的视频生成模型中,使其具备动作条件生成能力;3) 使用少量机器人操作数据对模型进行微调;4) 利用训练好的模型预测给定策略在环境中的行为,并根据预测结果评估策略的优劣。整体流程是先利用大规模数据学习通用的视觉表征,再利用少量领域数据进行微调,最后进行策略评估。
关键创新:该方法最重要的创新点在于将动作条件融入到预训练的视频生成模型中,从而能够利用互联网规模的视频数据进行策略评估。与传统的基于仿真的方法相比,该方法避免了手动构建仿真环境的复杂性,并减少了sim-to-real差距。与直接学习策略的方法相比,该方法通过学习世界模型,可以更好地泛化到不同的任务和环境。
关键设计:论文的关键设计包括:1) 使用Transformer架构作为视频生成模型的基础;2) 使用动作嵌入(action embedding)将动作信息融入到视频生成模型中;3) 使用对抗训练(adversarial training)提高生成视频的真实性;4) 使用多种损失函数,包括像素级别的重构损失和感知损失,以提高生成视频的质量。
🖼️ 关键图片
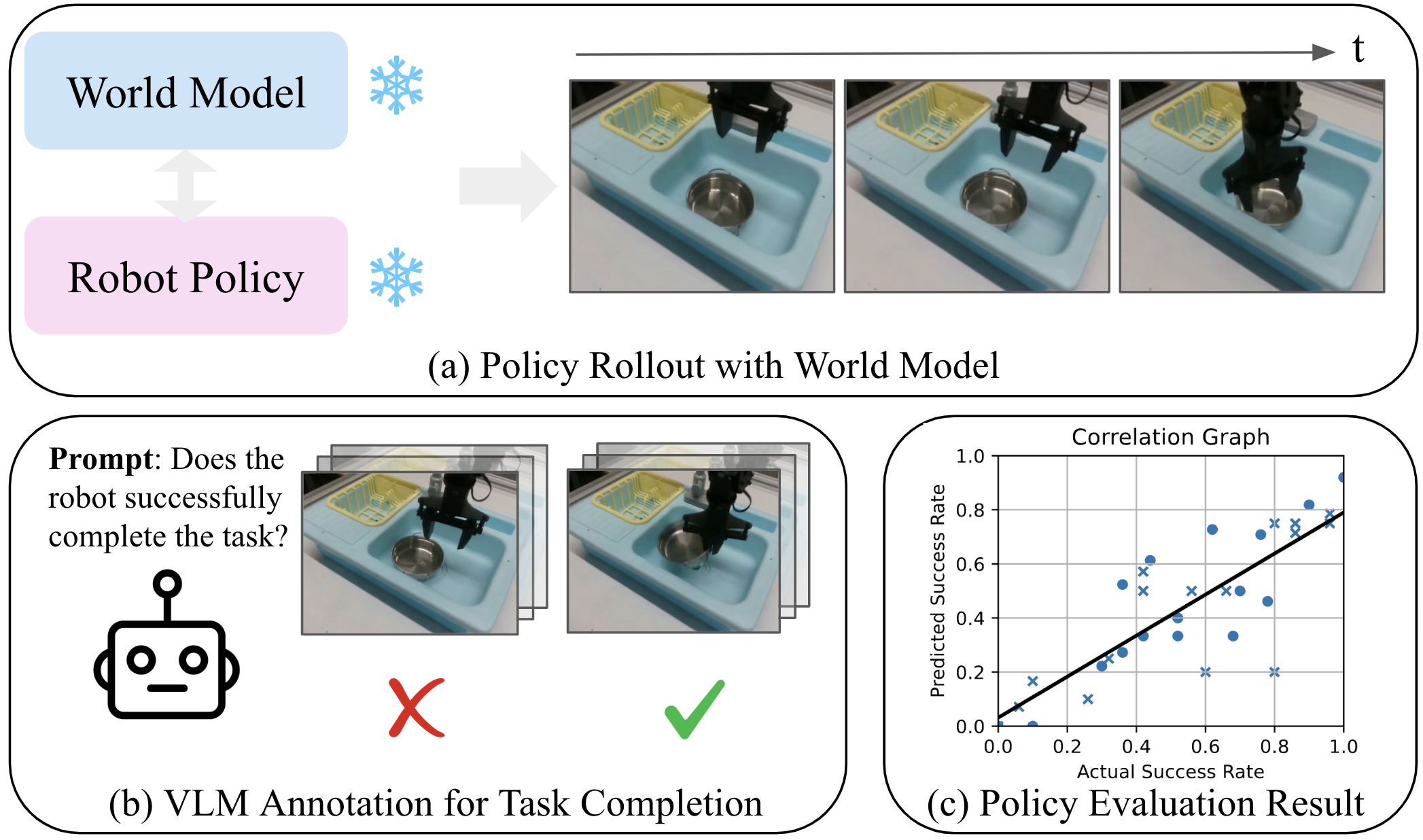
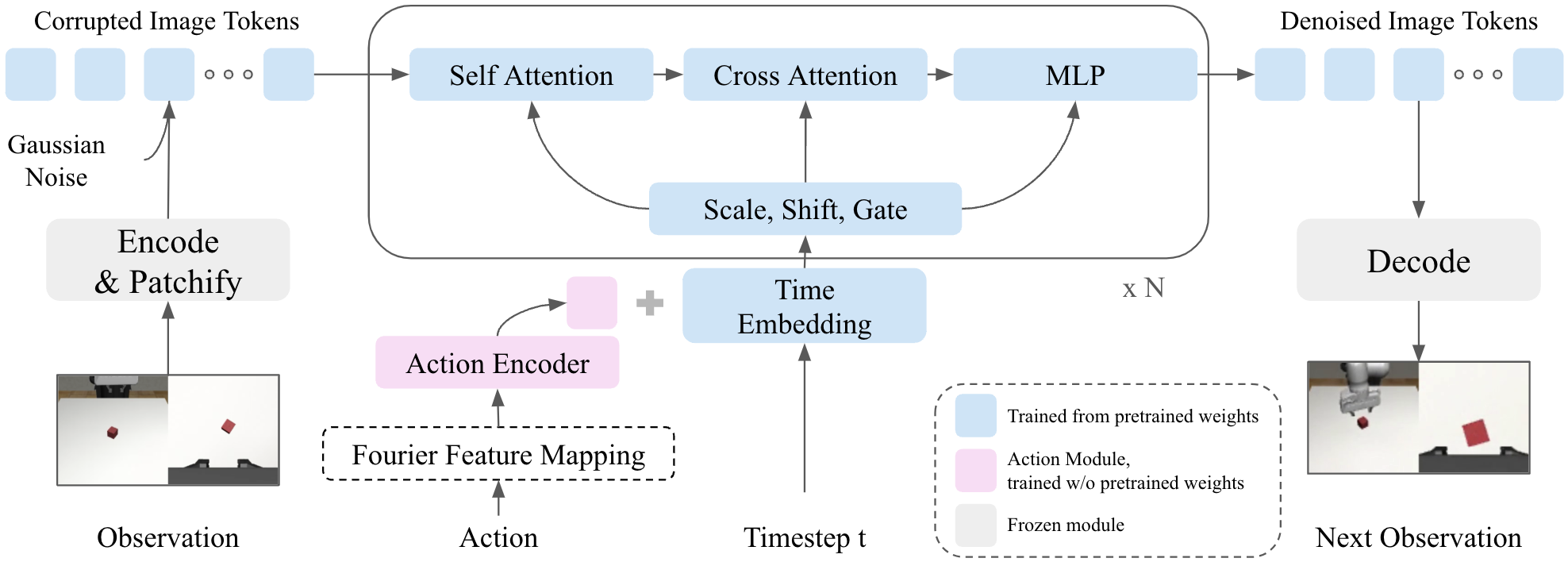
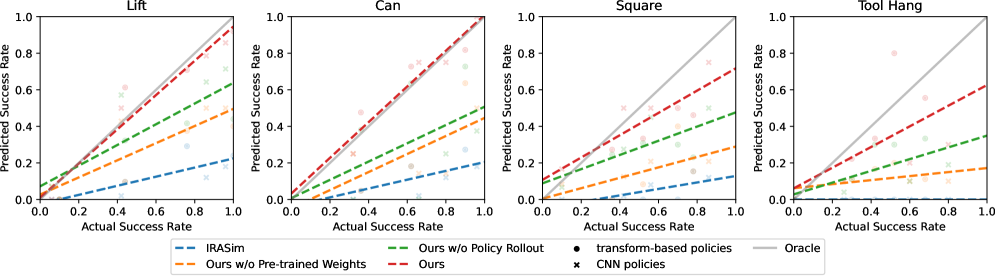
📊 实验亮点
实验结果表明,该方法在策略排序和策略值预测方面表现良好。具体而言,该方法能够准确地对不同策略进行排序,并且预测的策略值与实际策略值之间具有较高的相关性。此外,实验还验证了数据集多样性和预训练权重对模型性能的影响,并分析了常见的失败案例。
🎯 应用场景
该研究成果可应用于机器人操作策略的离线评估与优化,加速机器人学习算法的开发与部署。通过减少对真实环境交互的依赖,降低了机器人实验的成本和风险,促进了通用机器人策略的训练和应用。此外,该方法还可扩展到其他需要预测环境变化的领域,如自动驾驶、游戏AI等。
📄 摘要(原文)
Training generalist policies for robotic manipulation has shown great promise, as they enable language-conditioned, multi-task behaviors across diverse scenarios. However, evaluating these policies remains difficult because real-world testing is expensive, time-consuming, and labor-intensive. It also requires frequent environment resets and carries safety risks when deploying unproven policies on physical robots. Manually creating and populating simulation environments with assets for robotic manipulation has not addressed these issues, primarily due to the significant engineering effort required and the substantial sim-to-real gap, both in terms of physics and rendering. In this paper, we explore the use of action-conditional video generation models as a scalable way to learn world models for policy evaluation. We demonstrate how to incorporate action conditioning into existing pre-trained video generation models. This allows leveraging internet-scale in-the-wild online videos during the pre-training stage and alleviates the need for a large dataset of paired video-action data, which is expensive to collect for robotic manipulation. Our paper examines the effect of dataset diversity, pre-trained weights, and common failure cases for the proposed evaluation pipeline. Our experiments demonstrate that across various metrics, including policy ranking and the correlation between actual policy values and predicted policy values, these models offer a promising approach for evaluating policies without requiring real-world interactions.