Rethinking Progression of Memory State in Robotic Manipulation: An Object-Centric Perspective
作者: Nhat Chung, Taisei Hanyu, Toan Nguyen, Huy Le, Frederick Bumgarner, Duy Minh Ho Nguyen, Khoa Vo, Kashu Yamazaki, Chase Rainwater, Tung Kieu, Anh Nguyen, Ngan Le
分类: cs.RO, cs.CV
发布日期: 2025-11-14 (更新: 2025-11-28)
备注: Accepted at AAAI 2026
💡 一句话要点
提出Embodied-SlotSSM,解决机器人操作中长时记忆和对象跟踪难题。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人操作 长时记忆 对象跟踪 视觉语言动作模型 非马尔可夫决策过程
📋 核心要点
- 现有VLA模型在处理机器人操作任务时,难以有效跟踪和记忆对象状态,尤其是在长时序和部分可观测场景下。
- Embodied-SlotSSM通过slot-centric建模,维护对象时空一致性,并利用关系编码器对齐输入token和动作解码,实现上下文感知的动作预测。
- LIBERO-Mem基准测试表明,Embodied-SlotSSM在非马尔可夫机器人操作任务中表现出良好的性能,为长时记忆提供了可扩展的解决方案。
📝 摘要(中文)
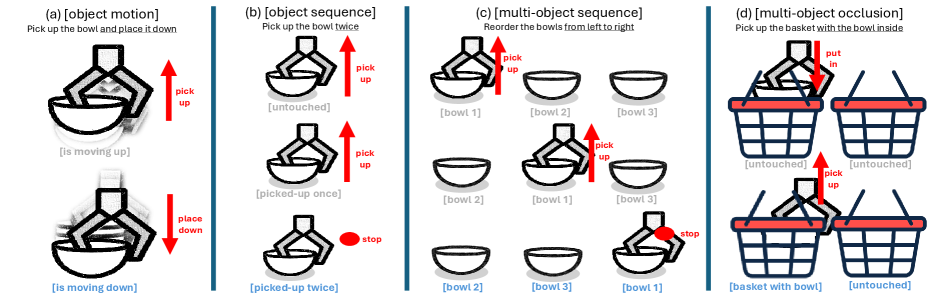
随着具身智能体在日益复杂的环境中运行,感知、跟踪和推理个体对象实例的能力变得至关重要,尤其是在需要与视觉上相似的对象进行序列交互的任务中。在这些非马尔可夫环境中,关键决策线索通常隐藏在对象特定的历史记录中,而不是当前场景中。如果缺乏对先前交互的持久记忆(已经交互了什么,它在哪里,或者它如何变化),视觉运动策略可能会失败,重复过去的动作,或者忽略已完成的动作。为了突出这一挑战,我们引入了LIBERO-Mem,这是一个非马尔可夫任务套件,用于在对象级部分可观察性下对机器人操作进行压力测试。它将短时和长时对象跟踪与时间序列子目标相结合,需要超越当前帧的推理。然而,视觉-语言-动作(VLA)模型通常在这种环境中表现不佳,即使对于仅跨越几百帧的任务,token扩展也很快变得难以处理。我们提出了Embodied-SlotSSM,一个为时间可扩展性而构建的slot-centric VLA框架。它保持了时空一致的slot身份,并通过两种机制利用它们:(1)用于重建短期历史的slot-state-space建模,以及(2)用于将输入token与动作解码对齐的关系编码器。这些组件共同实现了时间上扎根的、上下文感知的动作预测。实验表明Embodied-SlotSSM在LIBERO-Mem和通用任务上的基线性能,为对象中心机器人策略中的非马尔可夫推理提供了一个可扩展的解决方案。
🔬 方法详解
问题定义:论文旨在解决机器人操作任务中,由于环境的部分可观测性和任务的非马尔可夫性,导致现有视觉-语言-动作(VLA)模型难以有效跟踪和记忆对象状态的问题。现有方法在处理长时序任务时,token数量快速增长,计算复杂度高,难以扩展到更复杂的场景。
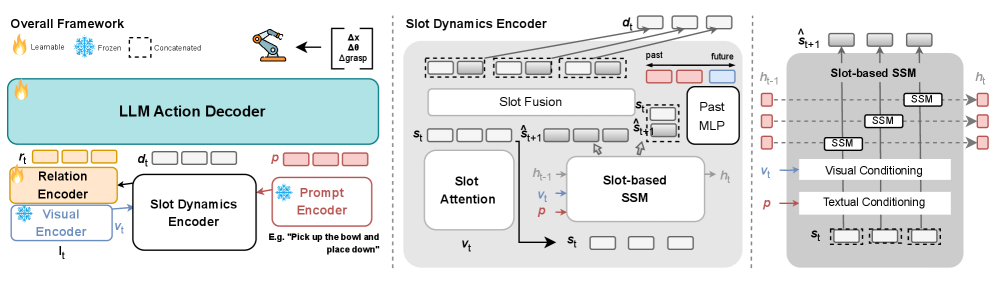
核心思路:论文的核心思路是采用slot-centric建模方法,将场景中的每个对象表示为一个slot,并维护这些slot的时空一致性。通过slot-state-space建模,可以重建对象的短期历史,从而克服部分可观测性带来的挑战。同时,利用关系编码器将输入token与动作解码对齐,实现上下文感知的动作预测。
技术框架:Embodied-SlotSSM框架包含以下主要模块:1) 视觉感知模块:用于从图像中提取视觉特征。2) Slot提取模块:用于将视觉特征转换为slot表示,每个slot对应一个对象。3) Slot-State-Space模型:用于维护每个slot的状态,并重建其短期历史。4) 关系编码器:用于编码slot之间的关系,并将输入token与动作解码对齐。5) 动作解码器:用于根据slot表示和关系编码,预测下一步的动作。
关键创新:该方法最重要的创新点在于slot-centric建模和slot-state-space模型的结合。通过slot-centric建模,可以有效地跟踪和记忆场景中的对象状态,克服部分可观测性带来的挑战。slot-state-space模型则可以重建对象的短期历史,从而实现时间上的推理。与现有方法相比,Embodied-SlotSSM具有更好的可扩展性和鲁棒性。
关键设计:论文中slot-state-space模型可能采用了循环神经网络(RNN)或Transformer等结构,用于维护slot的状态并进行时间上的推理。关系编码器可能采用了图神经网络(GNN)等结构,用于编码slot之间的关系。损失函数的设计可能包括动作预测损失、状态重建损失等,用于优化模型的性能。具体的参数设置和网络结构细节需要在论文中进一步查找。
🖼️ 关键图片

📊 实验亮点
Embodied-SlotSSM在LIBERO-Mem基准测试中表现出良好的性能,证明了其在非马尔可夫机器人操作任务中的有效性。该方法能够有效地跟踪和记忆对象状态,并实现上下文感知的动作预测。具体的性能数据和对比基线需要在论文中进一步查找。
🎯 应用场景
该研究成果可应用于各种需要长时记忆和对象跟踪的机器人操作任务,例如:家庭服务机器人、工业自动化机器人、医疗辅助机器人等。通过提高机器人对环境的理解和推理能力,可以使其更好地完成复杂的任务,提高工作效率和安全性,并扩展机器人的应用范围。
📄 摘要(原文)
As embodied agents operate in increasingly complex environments, the ability to perceive, track, and reason about individual object instances over time becomes essential, especially in tasks requiring sequenced interactions with visually similar objects. In these non-Markovian settings, key decision cues are often hidden in object-specific histories rather than the current scene. Without persistent memory of prior interactions (what has been interacted with, where it has been, or how it has changed) visuomotor policies may fail, repeat past actions, or overlook completed ones. To surface this challenge, we introduce LIBERO-Mem, a non-Markovian task suite for stress-testing robotic manipulation under object-level partial observability. It combines short- and long-horizon object tracking with temporally sequenced subgoals, requiring reasoning beyond the current frame. However, vision-language-action (VLA) models often struggle in such settings, with token scaling quickly becoming intractable even for tasks spanning just a few hundred frames. We propose Embodied-SlotSSM, a slot-centric VLA framework built for temporal scalability. It maintains spatio-temporally consistent slot identities and leverages them through two mechanisms: (1) slot-state-space modeling for reconstructing short-term history, and (2) a relational encoder to align the input tokens with action decoding. Together, these components enable temporally grounded, context-aware action prediction. Experiments show Embodied-SlotSSM's baseline performance on LIBERO-Mem and general tasks, offering a scalable solution for non-Markovian reasoning in object-centric robotic policies.