Humanoid Whole-Body Badminton via Multi-Stage Reinforcement Learning
作者: Chenhao Liu, Leyun Jiang, Yibo Wang, Kairan Yao, Jinchen Fu, Xiaoyu Ren
分类: cs.RO
发布日期: 2025-11-14 (更新: 2025-12-09)
备注: Project Page: https://humanoid-badminton.github.io/Humanoid-Whole-Body-Badminton-via-Multi-Stage-Reinforcement-Learning
💡 一句话要点
提出基于多阶段强化学习的人形机器人羽毛球全身体控制方法
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 人形机器人 强化学习 全身控制 羽毛球 动态交互
📋 核心要点
- 现有方法难以让人形机器人在动态环境中进行全身协调运动,尤其是在羽毛球等需要快速反应和精准控制的场景。
- 论文提出一种多阶段强化学习方法,分阶段训练机器人的步法、挥拍和整体击球策略,实现全身协同控制。
- 实验结果表明,该方法在模拟和真实环境中均能实现稳定击球,真实机器人击球速度达到19.1 m/s,落点距离4米。
📝 摘要(中文)
本文提出了一种基于强化学习的训练流程,用于生成人形机器人羽毛球运动的统一全身体控制器。该控制器无需运动先验或专家演示,即可实现协调的下肢步法和上肢击球动作。训练过程分为三个阶段:首先是步法学习,然后是精确引导的球拍挥动生成,最后是任务聚焦的优化。为了部署,我们结合扩展卡尔曼滤波器(EKF)来估计和预测羽毛球轨迹以进行目标击球。我们还引入了一种无需预测的变体,它不需要EKF和显式轨迹预测。在模拟和真实环境中进行了五组实验来验证该框架。在模拟中,两个机器人连续击球21次。在真实测试中,预测和控制器模块都表现出很高的准确性,并且在球场上的击球速度高达19.1 m/s,平均返回落点距离为4米。这些实验结果表明,我们提出的训练方案可以在羽毛球运动中实现高度动态且精确的目标击球,并且可以适应更多动态关键领域。
🔬 方法详解
问题定义:现有人形机器人控制方法在处理动态交互任务时存在局限性,尤其是在羽毛球这种需要快速反应和全身协调的运动中。传统的控制方法往往依赖于运动先验或专家演示,难以适应复杂多变的运动环境。因此,如何让人形机器人在没有先验知识的情况下,自主学习并完成羽毛球击打任务是一个挑战。
核心思路:论文的核心思路是将复杂的羽毛球击打任务分解为多个阶段,通过强化学习分阶段训练机器人的不同能力,最终实现全身协同控制。这种分阶段训练的方式可以降低学习难度,提高训练效率,并使机器人能够更好地适应不同的运动环境。
技术框架:整体框架包含三个阶段:1) 步法学习:训练机器人快速移动并到达合适的击球位置。2) 挥拍生成:训练机器人精确控制球拍,实现目标击球。3) 任务优化:对整体策略进行优化,使机器人能够更好地完成击球任务。此外,论文还使用了扩展卡尔曼滤波器(EKF)来预测羽毛球的轨迹,并提出了一种无需预测的变体。
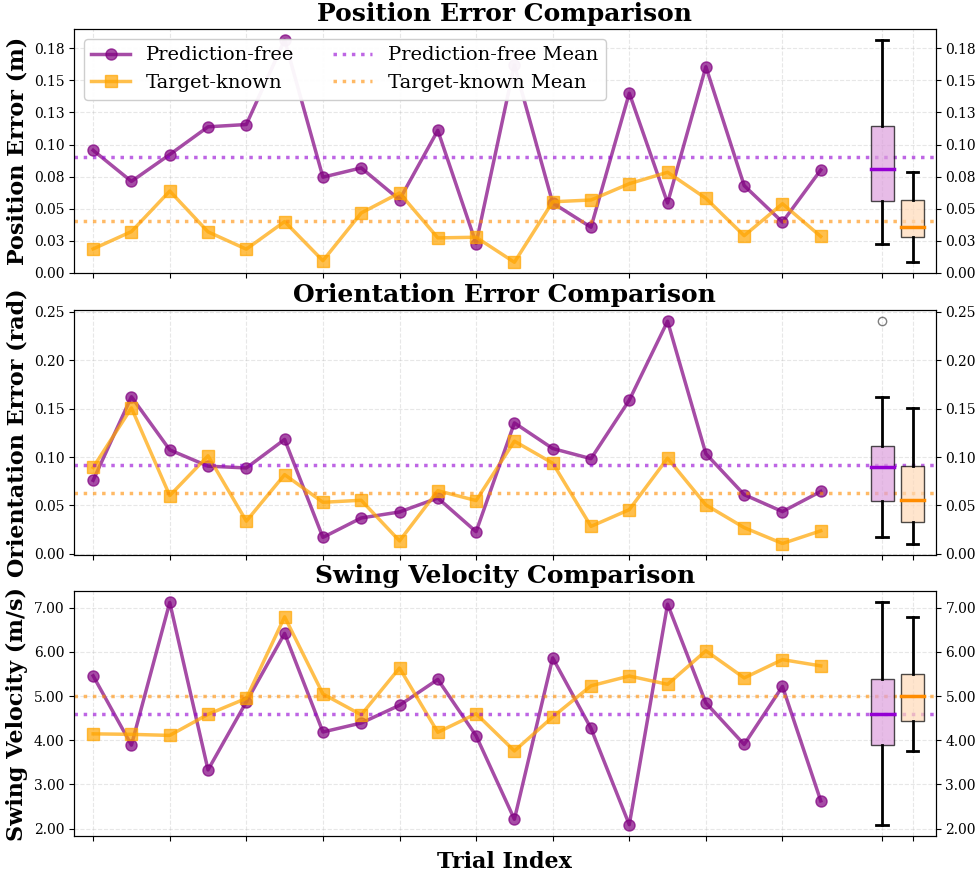
关键创新:论文的关键创新在于提出了一种多阶段强化学习的训练方法,将复杂的全身控制问题分解为多个易于学习的子问题。这种方法可以有效地提高训练效率,并使机器人能够更好地适应不同的运动环境。此外,论文还提出了一种无需预测的控制策略,进一步提高了机器人的鲁棒性。
关键设计:在步法学习阶段,设计了奖励函数鼓励机器人快速移动到目标位置。在挥拍生成阶段,设计了奖励函数鼓励机器人精确控制球拍,实现目标击球。在任务优化阶段,设计了奖励函数鼓励机器人完成整个击球任务。具体参数设置和网络结构等技术细节在论文中有详细描述。
🖼️ 关键图片
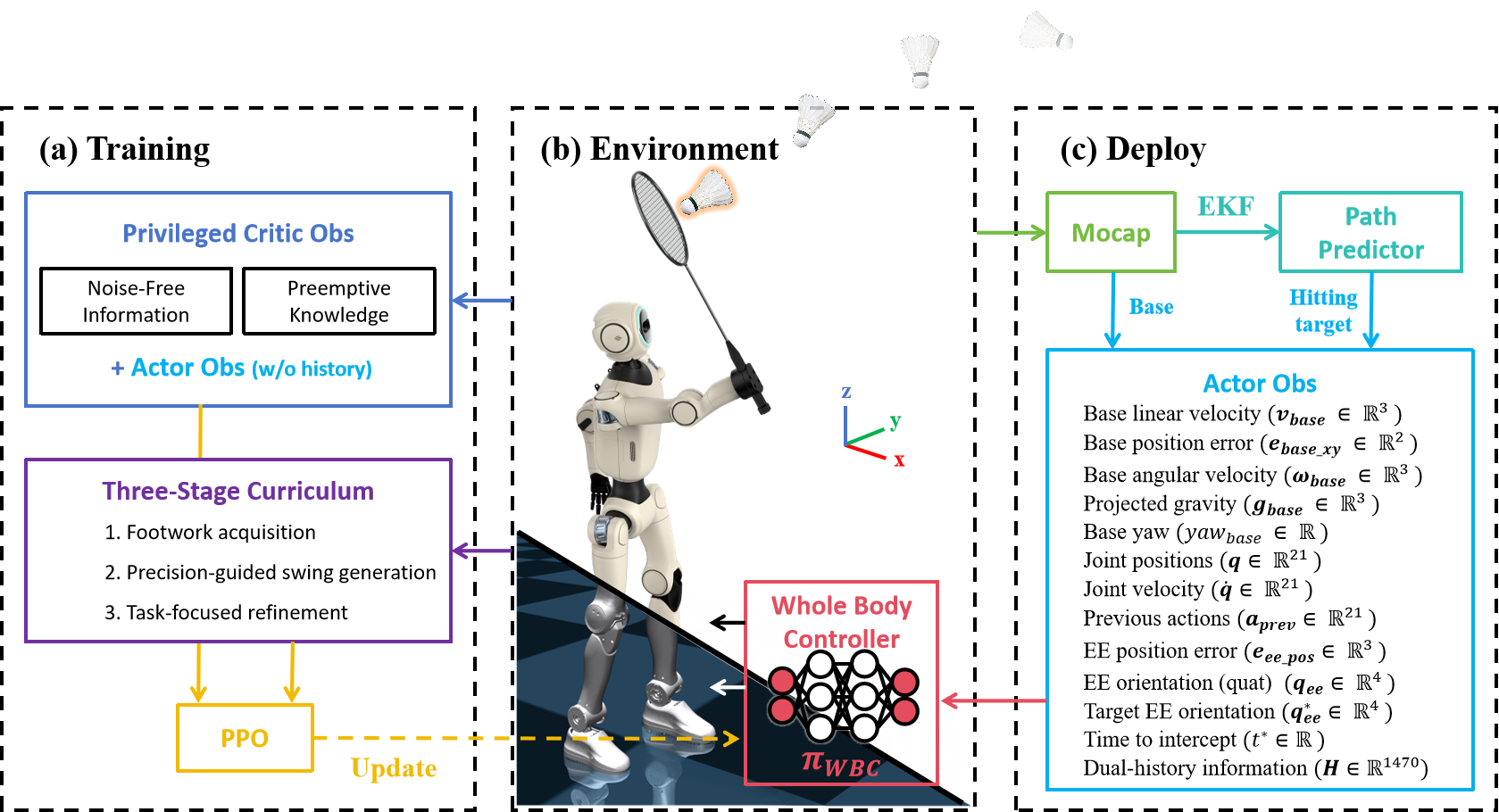

📊 实验亮点
论文在模拟环境中实现了两个机器人连续击球21次,验证了所提出方法的有效性。在真实环境中,机器人击球速度达到19.1 m/s,平均落点距离为4米,表明该方法具有较高的精度和鲁棒性。此外,无需预测的控制策略也取得了与基于预测的策略相当的性能,进一步提高了机器人的适应性。
🎯 应用场景
该研究成果可应用于人形机器人在动态环境中的运动控制,例如体育竞技、人机协作等领域。通过学习羽毛球运动中的全身协调控制策略,可以为其他更复杂的动态交互任务提供参考,例如机器人辅助康复、机器人参与救援等。此外,该研究也有助于推动强化学习在机器人控制领域的应用。
📄 摘要(原文)
Humanoid robots have demonstrated strong capabilities for interacting with static scenes across locomotion, manipulation, and more challenging loco-manipulation tasks. Yet the real world is dynamic, and quasi-static interactions are insufficient to cope with diverse environmental conditions. As a step toward more dynamic interaction scenarios, we present a reinforcement-learning-based training pipeline that produces a unified whole-body controller for humanoid badminton, enabling coordinated lower-body footwork and upper-body striking without motion priors or expert demonstrations. Training follows a three-stage curriculum: first footwork acquisition, then precision-guided racket swing generation, and finally task-focused refinement, yielding motions in which both legs and arms serve the hitting objective. For deployment, we incorporate an Extended Kalman Filter (EKF) to estimate and predict shuttlecock trajectories for target striking. We also introduce a prediction-free variant that dispenses with EKF and explicit trajectory prediction. To validate the framework, we conduct five sets of experiments in both simulation and the real world. In simulation, two robots sustain a rally of 21 consecutive hits. Moreover, the prediction-free variant achieves successful hits with comparable performance relative to the target-known policy. In real-world tests, both prediction and controller modules exhibit high accuracy, and on-court hitting achieves an outgoing shuttle speed up to 19.1 m/s with a mean return landing distance of 4 m. These experimental results show that our proposed training scheme can deliver highly dynamic while precise goal striking in badminton, and can be adapted to more dynamics-critical domains.