Lite VLA: Efficient Vision-Language-Action Control on CPU-Bound Edge Robots
作者: Justin Williams, Kishor Datta Gupta, Roy George, Mrinmoy Sarkar
分类: cs.RO, cs.AR, cs.CV, eess.SY
发布日期: 2025-11-07
💡 一句话要点
Lite VLA:CPU约束边缘机器人上的高效视觉-语言-动作控制
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 边缘计算 视觉-语言模型 机器人控制 多模态感知 嵌入式系统
📋 核心要点
- 现有方法通常将感知与移动性分离,限制了边缘机器人在动态环境中实时推理和行动的能力。
- Lite VLA框架通过集成紧凑型VLM与多模态感知,实现在资源受限的边缘设备上进行同步移动和推理。
- 实验表明,该方法在计算效率、任务准确性和系统响应能力之间取得了良好的平衡,并在移动机器人上成功部署。
📝 摘要(中文)
在边缘部署人工智能模型对于在GPS受限环境中运行的自主机器人至关重要,在这些环境中,本地、资源高效的推理至关重要。本文展示了在移动机器人上部署小型视觉-语言模型(VLM)以在严格的计算约束下实现实时场景理解和推理的可行性。与将感知与移动性分离的先前方法不同,所提出的框架仅使用板载硬件即可在动态环境中实现同步移动和推理。该系统集成了紧凑型VLM与多模态感知,以直接在嵌入式硬件上执行上下文解释,从而消除了对云连接的依赖。实验验证突出了计算效率、任务准确性和系统响应能力之间的平衡。在移动机器人上的实施证实了小型VLM在边缘进行并发推理和移动性的首次成功部署之一。这项工作为服务机器人、灾难响应和国防行动等应用中的可扩展、可靠的自主性奠定了基础。
🔬 方法详解
问题定义:论文旨在解决在计算资源受限的边缘机器人上,如何实现高效的视觉-语言-动作控制的问题。现有方法通常依赖于云计算或将感知与移动性分离,导致延迟高、功耗大,并且难以适应动态环境。这些痛点限制了边缘机器人在实际应用中的部署。
核心思路:论文的核心思路是利用小型化的视觉-语言模型(VLM),结合多模态感知,直接在边缘设备上进行实时推理和动作规划。通过优化模型结构和推理流程,在保证任务准确性的前提下,显著降低计算复杂度,从而实现在CPU约束下的高效运行。
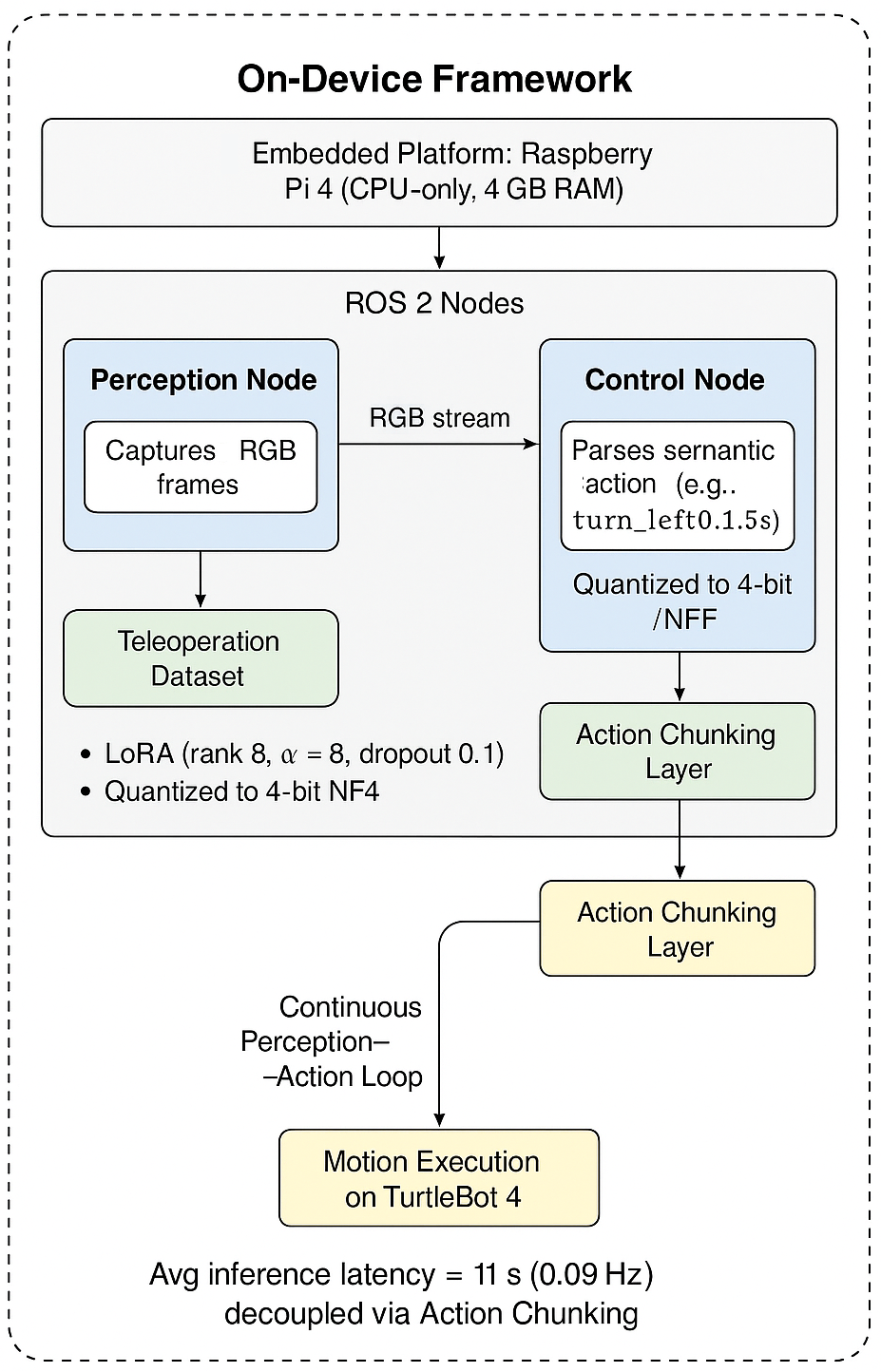
技术框架:Lite VLA框架主要包含以下几个模块:1) 多模态感知模块,负责从摄像头、激光雷达等传感器获取环境信息;2) 小型VLM,用于理解场景描述和用户指令,并生成相应的动作指令;3) 运动控制模块,负责执行动作指令,控制机器人的运动。整个流程是端到端的,从感知到动作,无需依赖云计算。
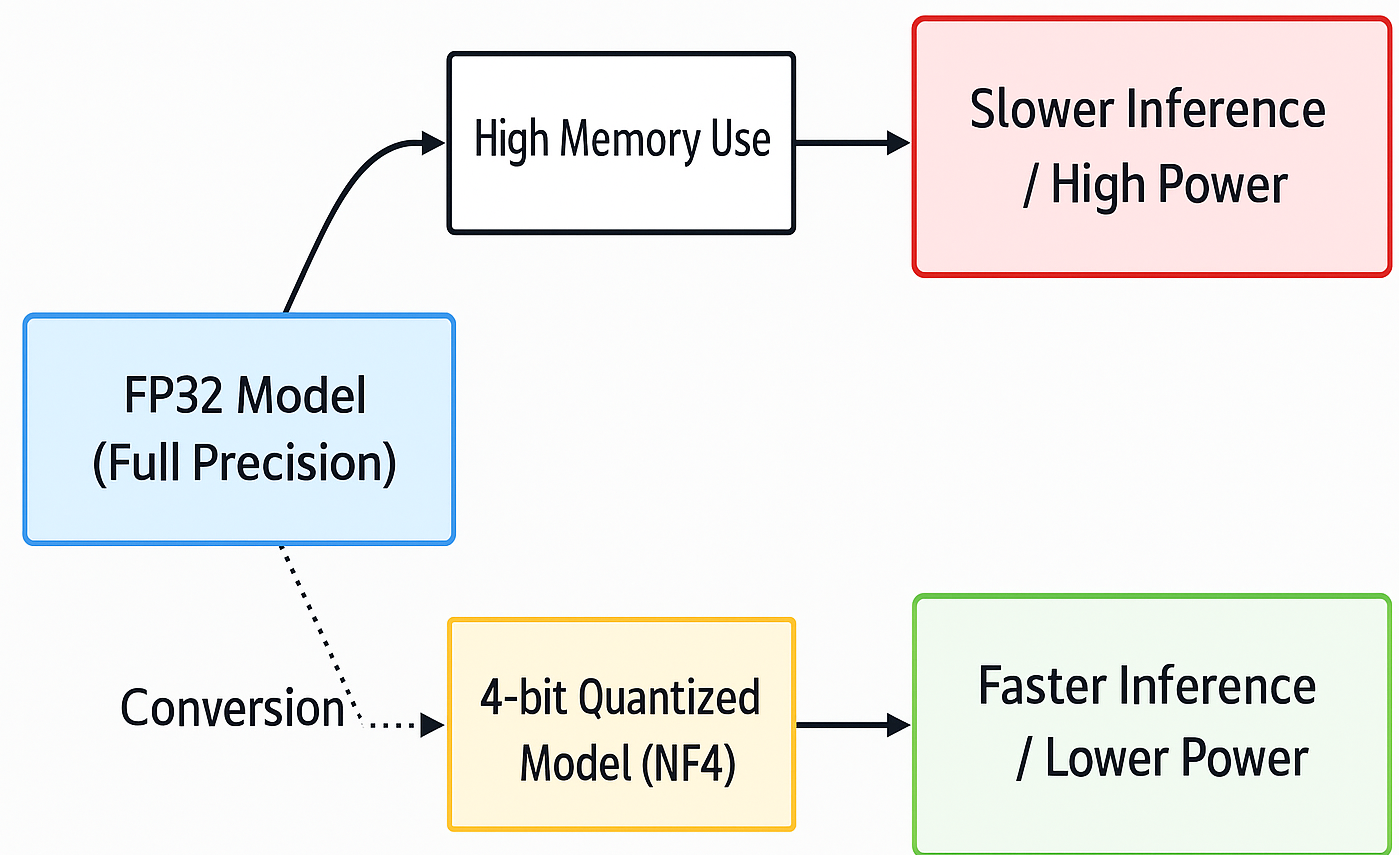
关键创新:论文最重要的技术创新点在于对VLM的轻量化设计和优化。通过模型剪枝、量化等技术,显著降低了模型的参数量和计算复杂度,使其能够在CPU约束的边缘设备上实时运行。此外,论文还提出了针对机器人控制任务的VLM训练方法,提高了模型的任务适应性。
关键设计:论文在VLM的设计上,采用了Transformer架构,并针对机器人控制任务进行了优化。例如,使用了更小的embedding维度、更少的Transformer层数,以及更高效的注意力机制。在损失函数方面,除了传统的语言建模损失外,还引入了动作预测损失,以提高模型对动作的预测精度。具体参数设置未知。
🖼️ 关键图片
📊 实验亮点
该论文在移动机器人上成功部署了小型VLM,实现了并发推理和移动性,这是首次在边缘设备上实现此类功能。实验结果表明,该方法在保证任务准确性的前提下,显著降低了计算复杂度,能够在CPU约束下实时运行。具体的性能数据和对比基线未知。
🎯 应用场景
该研究成果可广泛应用于服务机器人、灾难响应和国防行动等领域。例如,在灾难现场,机器人可以利用Lite VLA框架理解救援人员的指令,自主规划行动路线,并执行搜救任务。在服务机器人领域,该框架可以使机器人更好地理解用户的需求,提供更加智能化的服务。此外,该技术还有潜力应用于自动驾驶、智能制造等领域。
📄 摘要(原文)
The deployment of artificial intelligence models at the edge is increasingly critical for autonomous robots operating in GPS-denied environments where local, resource-efficient reasoning is essential. This work demonstrates the feasibility of deploying small Vision-Language Models (VLMs) on mobile robots to achieve real-time scene understanding and reasoning under strict computational constraints. Unlike prior approaches that separate perception from mobility, the proposed framework enables simultaneous movement and reasoning in dynamic environments using only on-board hardware. The system integrates a compact VLM with multimodal perception to perform contextual interpretation directly on embedded hardware, eliminating reliance on cloud connectivity. Experimental validation highlights the balance between computational efficiency, task accuracy, and system responsiveness. Implementation on a mobile robot confirms one of the first successful deployments of small VLMs for concurrent reasoning and mobility at the edge. This work establishes a foundation for scalable, assured autonomy in applications such as service robotics, disaster response, and defense operations.